

Chapter 6: Introduction to Neural Networks and Deep Learning
6.1 Perceptron and Multi-Layer Perceptron
Welcome to the exciting and rapidly advancing world of neural networks and deep learning! This chapter marks a significant shift in our journey as we move from traditional machine learning techniques to the realm of deep learning, which is a subset of machine learning. Due to its potential, deep learning has been at the forefront of many recent advancements in artificial intelligence, with its ability to enable self-driving cars, voice assistants, personalized recommendations, and much more.
In this chapter, we will start by introducing the basic building block of neural networks - the perceptron. This is a simple structure that can help us understand more complex structures such as multi-layer perceptrons. We will then move on to more complex structures and discuss how they form the basis for more advanced deep-learning models. We will also cover the key concepts and principles that underpin these models, including backpropagation and gradient descent, which are fundamental to the workings of neural networks.
Moreover, after providing a solid foundation in neural networks and deep learning, we will delve into the more advanced topics, including convolutional neural networks and recurrent neural networks, which are essential to understanding how deep learning models can be used in the real world. We will also explore how these models are used in natural language processing, image classification, and voice recognition. By the end of this chapter, you will be well-equipped to tackle the more advanced topics that await you in the exciting world of deep learning.
So, let's dive in and embark on this fascinating journey of discovery!
6.1.1 The Perceptron
The perceptron is the simplest form of a neural network. It was introduced by Frank Rosenblatt in the late 1950s. A perceptron takes several binary inputs, x1, x2, ..., and produces a single binary output:
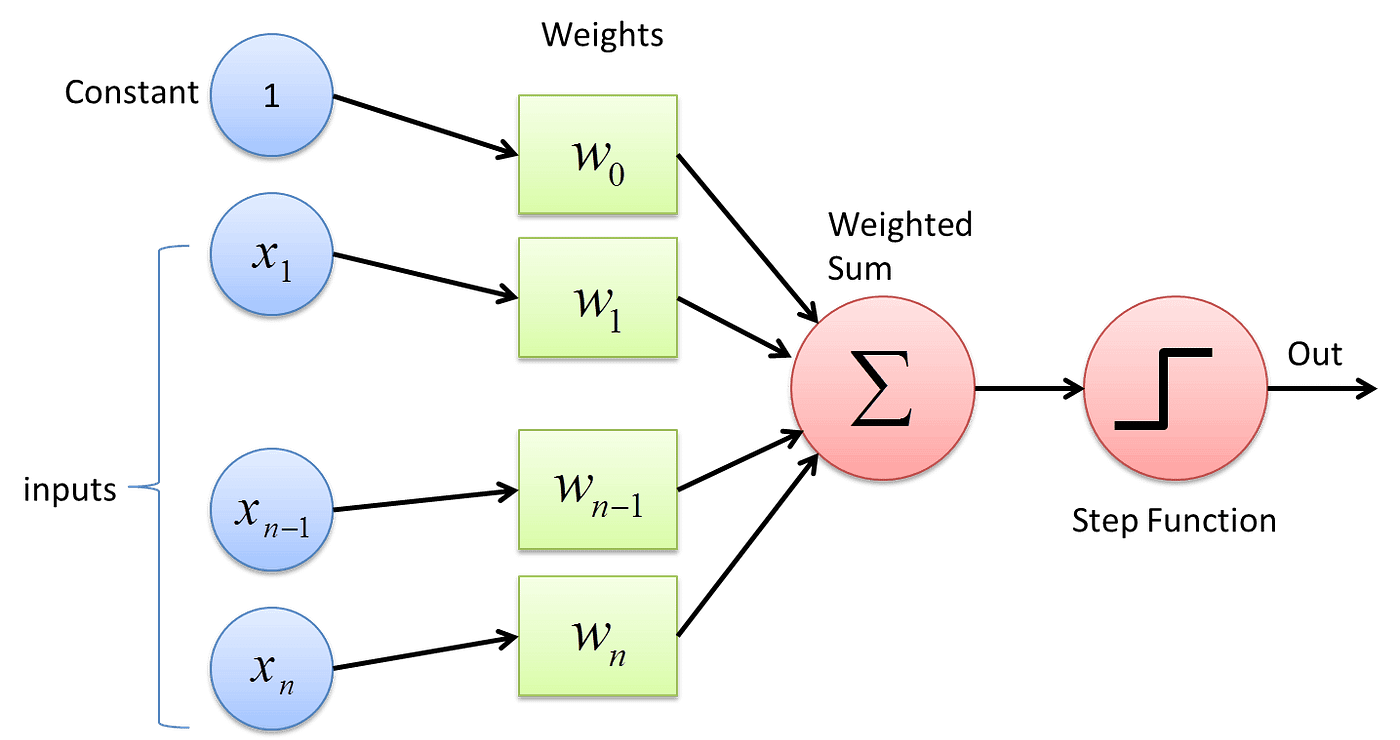
In the modern sense, the perceptron is an algorithm for learning a binary classifier. That is a function that maps its input "x" (a real-valued vector) to an output value "f(x)" (a single binary value):
f(x) = 1 if w·x + b > 0, 0 otherwise
Here "w" is a vector of real-valued weights, "w·x" is the dot product ∑ᵢwᵢxᵢ, where "i" ranges over the indices of the vectors, and "b" is the bias, a constant term that does not depend on any input value.
Example:
Here's a simple implementation of a perceptron in Python:
import numpy as np
class Perceptron(object):
def __init__(self, no_of_inputs, threshold=100, learning_rate=0.01):
self.threshold = threshold
self.learning_rate = learning_rate
self.weights = np.zeros(no_of_inputs + 1) # Initialize weights to zeros
def predict(self, inputs):
summation = np.dot(inputs, self.weights[1:]) + self.weights[0] # Include bias term
activation = 1 if summation > 0 else 0 # Simplified activation calculation
return activation
def train(self, training_inputs, labels):
for _ in range(self.threshold):
for inputs, label in zip(training_inputs, labels):
prediction = self.predict(inputs)
# Update weights including bias term
update = self.learning_rate * (label - prediction)
self.weights[1:] += update * inputs
self.weights[0] += updateThis example code defines a class called Perceptron, which has three methods: __init__, predict, and train. The __init__ method initializes the object's attributes, the predict method predicts the output of the perceptron for a given input, and the train method trains the perceptron on a given set of training data.
The output of the code will depend on the training data that you use. For example, if you train the perceptron on a dataset of binary classification data, then the output of the train method will be a set of weights that can be used to classify new data.
6.1.2 Limitations of a Single Perceptron
While the perceptron forms the basis for neural networks, it has its limitations. Although it can learn many patterns, its capacity to learn can be limited by its design. One of the most significant limitations of a single perceptron is that it can only learn linearly separable patterns. This means that it can only separate data points with a straight line or a hyperplane in higher dimensions. As a result, more complex decision boundaries cannot be learned by a single perceptron. This is a significant limitation because many real-world problems are not linearly separable and require more complex decision boundaries, which a single perceptron may not be able to learn.
For example, consider the XOR problem, where we have four points in a 2D space: (0,0), (0,1), (1,0), and (1,1). The goal is to separate the points where the XOR of the coordinates is 1 from the points where the XOR is 0. This problem is not linearly separable, and a single perceptron cannot solve it. Therefore, to solve such problems, we need to use a more complex architecture that can learn non-linear decision boundaries. One such architecture is a multi-layer perceptron, which consists of multiple perceptrons arranged in layers to learn more complex patterns.
6.1.3 Multi-Layer Perceptron
To overcome the limitations of a single perceptron and further enhance its accuracy, we can use a multi-layer perceptron (MLP). The concept of an MLP is relatively simple: it consists of multiple layers of perceptrons, also known as neurons, with the output of one layer serving as the input for the next layer. This structure allows the MLP to learn more complex, non-linear patterns that a single perceptron would not be able to comprehend.
An MLP usually comprises an input layer, one or more hidden layers, and an output layer. Each of these layers consists of multiple neurons, and each neuron in a layer is connected to every neuron in the next layer. These connections are associated with weights, which are adjusted during the learning process to optimize the performance of the MLP.
The process of training an MLP is iterative and involves forward and backward propagation of the input signal. During forward propagation, the input signal is processed through the layers of neurons, with the output of each layer being passed on to the next layer. During backward propagation, the error in prediction is calculated and propagated backward through the layers to adjust the weights and improve the accuracy of the MLP.
Therefore, it is clear that an MLP is a more sophisticated and powerful form of neural network that can learn and recognize complex patterns. By adding more layers and neurons, an MLP can be trained to achieve higher levels of accuracy and can be used in various applications, such as image recognition, speech recognition, and natural language processing.
Example:
Here's a simple implementation of an MLP with one hidden layer in Python using the Keras library:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer
model.add(Dense(32, input_dim=8, activation='relu'))
# Add an output layer
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)This example code creates a Sequential model with an input layer of 8 neurons, a hidden layer of 32 neurons with ReLU activation, and an output layer of 1 neuron with sigmoid activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
In this example, X is the input data and y are the labels. The model has one hidden layer with 32 neurons, and the output layer uses the sigmoid activation function, which is suitable for binary classification.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1.4 Activation Functions
In the context of neural networks, an activation function defines the output of a neuron given a set of inputs. Biologically inspired by activity in our brains where different neurons fire, or are activated, by different stimuli, activation functions are used to add non-linearity to the learning process.
In the case of the perceptron, we used a simple step function as the activation function. If the weighted sum of the inputs is greater than a threshold, the perceptron fires and outputs a 1; otherwise, it outputs a 0.
However, this step function isn't suitable for multi-layer perceptrons that we use in deep learning. The step function contains only flat segments, and thus, its derivative is zero. This is problematic because during backpropagation (which we'll discuss later), we use the derivative of the activation function to update the weights and biases. If the derivative is zero, then the weights and biases will not get updated effectively during training, and the model might not learn at all.
Therefore, in multi-layer perceptrons, we use different types of activation functions, such as the sigmoid function, hyperbolic tangent function (tanh), and Rectified Linear Unit (ReLU). These functions are non-linear, continuous, and differentiable, which makes them suitable for backpropagation.
Here's a brief overview of these activation functions:
Sigmoid function
The sigmoid function is a mathematical function that maps real-valued inputs to a range between 0 and 1. It is widely used in machine learning and artificial neural networks to model nonlinear relationships between input and output variables.
Despite its usefulness, the sigmoid function suffers from the vanishing gradient problem, which is a common issue in deep learning. This problem occurs when the sigmoid function is used in deep neural networks with many layers. As the input to the function becomes larger, the gradient becomes smaller, making it difficult to train the network.
To overcome this issue, researchers have developed alternative activation functions, such as the ReLU function, which do not suffer from the vanishing gradient problem. However, the sigmoid function is still used in many applications due to its simplicity and ease of use.
Hyperbolic tangent function (tanh)
The tanh function is similar to the sigmoid function but squashes the input to range between -1 and 1. It also suffers from the vanishing gradient problem.
The hyperbolic tangent function, also known as the tanh function, is a mathematical function that is similar to the sigmoid function. It is defined as the ratio of the hyperbolic sine function to the hyperbolic cosine function. The main difference between the two functions is that while the sigmoid function squashes the input to a range between 0 and 1, the tanh function squashes the input to a range between -1 and 1. This means that the tanh function has a wider output range, which makes it more suitable for certain machine learning applications.
However, the tanh function is not without its drawbacks. One of the main issues with the tanh function is the vanishing gradient problem, which occurs when the gradients of the function become very small. This can make it difficult for neural networks to learn effectively, especially when the inputs are large or the network is deep. Nevertheless, the tanh function remains a popular choice for certain types of neural networks, especially those that require outputs between -1 and 1.
Rectified Linear Unit (ReLU)
The ReLU function is the most commonly used activation function in deep learning models. When compared to other activation functions, such as sigmoid or tanh, ReLU has been found to be more computationally efficient, making it a popular choice.
Additionally, ReLU has been shown to mitigate the vanishing gradient problem, which can occur in deep neural networks when using certain activation functions. This is because ReLU only sets negative values to 0, while leaving positive values unchanged, allowing for better propagation of gradients.
However, it is important to note that ReLU can suffer from the "dead neuron" problem, where neurons can become inactive and produce 0 for every input, resulting in a loss of learning. To address this issue, variants of ReLU, such as Leaky ReLU and Parametric ReLU, have been developed to provide a small slope for negative inputs, preventing neurons from becoming completely inactive.
Example:
Here's how you can implement these activation functions in a multi-layer perceptron using Keras:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer with sigmoid activation function
model.add(Dense(32, input_dim=8, activation='sigmoid'))
# Add a hidden layer with tanh activation function
model.add(Dense(32, activation='tanh'))
# Add a hidden layer with ReLU activation function
model.add(Dense(32, activation='relu'))
# Add an output layer with sigmoid activation function
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)
# Evaluate the model
score = model.evaluate(X, y, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
This example code creates a Sequential model with an input layer of 8 neurons, three hidden layers with 32 neurons each, and an output layer of 1 neuron. The first hidden layer uses sigmoid activation, the second hidden layer uses tanh activation, and the third hidden layer uses ReLU activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1 Perceptron and Multi-Layer Perceptron
Welcome to the exciting and rapidly advancing world of neural networks and deep learning! This chapter marks a significant shift in our journey as we move from traditional machine learning techniques to the realm of deep learning, which is a subset of machine learning. Due to its potential, deep learning has been at the forefront of many recent advancements in artificial intelligence, with its ability to enable self-driving cars, voice assistants, personalized recommendations, and much more.
In this chapter, we will start by introducing the basic building block of neural networks - the perceptron. This is a simple structure that can help us understand more complex structures such as multi-layer perceptrons. We will then move on to more complex structures and discuss how they form the basis for more advanced deep-learning models. We will also cover the key concepts and principles that underpin these models, including backpropagation and gradient descent, which are fundamental to the workings of neural networks.
Moreover, after providing a solid foundation in neural networks and deep learning, we will delve into the more advanced topics, including convolutional neural networks and recurrent neural networks, which are essential to understanding how deep learning models can be used in the real world. We will also explore how these models are used in natural language processing, image classification, and voice recognition. By the end of this chapter, you will be well-equipped to tackle the more advanced topics that await you in the exciting world of deep learning.
So, let's dive in and embark on this fascinating journey of discovery!
6.1.1 The Perceptron
The perceptron is the simplest form of a neural network. It was introduced by Frank Rosenblatt in the late 1950s. A perceptron takes several binary inputs, x1, x2, ..., and produces a single binary output:
In the modern sense, the perceptron is an algorithm for learning a binary classifier. That is a function that maps its input "x" (a real-valued vector) to an output value "f(x)" (a single binary value):
f(x) = 1 if w·x + b > 0, 0 otherwise
Here "w" is a vector of real-valued weights, "w·x" is the dot product ∑ᵢwᵢxᵢ, where "i" ranges over the indices of the vectors, and "b" is the bias, a constant term that does not depend on any input value.
Example:
Here's a simple implementation of a perceptron in Python:
import numpy as np
class Perceptron(object):
def __init__(self, no_of_inputs, threshold=100, learning_rate=0.01):
self.threshold = threshold
self.learning_rate = learning_rate
self.weights = np.zeros(no_of_inputs + 1) # Initialize weights to zeros
def predict(self, inputs):
summation = np.dot(inputs, self.weights[1:]) + self.weights[0] # Include bias term
activation = 1 if summation > 0 else 0 # Simplified activation calculation
return activation
def train(self, training_inputs, labels):
for _ in range(self.threshold):
for inputs, label in zip(training_inputs, labels):
prediction = self.predict(inputs)
# Update weights including bias term
update = self.learning_rate * (label - prediction)
self.weights[1:] += update * inputs
self.weights[0] += updateThis example code defines a class called Perceptron, which has three methods: __init__, predict, and train. The __init__ method initializes the object's attributes, the predict method predicts the output of the perceptron for a given input, and the train method trains the perceptron on a given set of training data.
The output of the code will depend on the training data that you use. For example, if you train the perceptron on a dataset of binary classification data, then the output of the train method will be a set of weights that can be used to classify new data.
6.1.2 Limitations of a Single Perceptron
While the perceptron forms the basis for neural networks, it has its limitations. Although it can learn many patterns, its capacity to learn can be limited by its design. One of the most significant limitations of a single perceptron is that it can only learn linearly separable patterns. This means that it can only separate data points with a straight line or a hyperplane in higher dimensions. As a result, more complex decision boundaries cannot be learned by a single perceptron. This is a significant limitation because many real-world problems are not linearly separable and require more complex decision boundaries, which a single perceptron may not be able to learn.
For example, consider the XOR problem, where we have four points in a 2D space: (0,0), (0,1), (1,0), and (1,1). The goal is to separate the points where the XOR of the coordinates is 1 from the points where the XOR is 0. This problem is not linearly separable, and a single perceptron cannot solve it. Therefore, to solve such problems, we need to use a more complex architecture that can learn non-linear decision boundaries. One such architecture is a multi-layer perceptron, which consists of multiple perceptrons arranged in layers to learn more complex patterns.
6.1.3 Multi-Layer Perceptron
To overcome the limitations of a single perceptron and further enhance its accuracy, we can use a multi-layer perceptron (MLP). The concept of an MLP is relatively simple: it consists of multiple layers of perceptrons, also known as neurons, with the output of one layer serving as the input for the next layer. This structure allows the MLP to learn more complex, non-linear patterns that a single perceptron would not be able to comprehend.
An MLP usually comprises an input layer, one or more hidden layers, and an output layer. Each of these layers consists of multiple neurons, and each neuron in a layer is connected to every neuron in the next layer. These connections are associated with weights, which are adjusted during the learning process to optimize the performance of the MLP.
The process of training an MLP is iterative and involves forward and backward propagation of the input signal. During forward propagation, the input signal is processed through the layers of neurons, with the output of each layer being passed on to the next layer. During backward propagation, the error in prediction is calculated and propagated backward through the layers to adjust the weights and improve the accuracy of the MLP.
Therefore, it is clear that an MLP is a more sophisticated and powerful form of neural network that can learn and recognize complex patterns. By adding more layers and neurons, an MLP can be trained to achieve higher levels of accuracy and can be used in various applications, such as image recognition, speech recognition, and natural language processing.
Example:
Here's a simple implementation of an MLP with one hidden layer in Python using the Keras library:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer
model.add(Dense(32, input_dim=8, activation='relu'))
# Add an output layer
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)This example code creates a Sequential model with an input layer of 8 neurons, a hidden layer of 32 neurons with ReLU activation, and an output layer of 1 neuron with sigmoid activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
In this example, X is the input data and y are the labels. The model has one hidden layer with 32 neurons, and the output layer uses the sigmoid activation function, which is suitable for binary classification.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1.4 Activation Functions
In the context of neural networks, an activation function defines the output of a neuron given a set of inputs. Biologically inspired by activity in our brains where different neurons fire, or are activated, by different stimuli, activation functions are used to add non-linearity to the learning process.
In the case of the perceptron, we used a simple step function as the activation function. If the weighted sum of the inputs is greater than a threshold, the perceptron fires and outputs a 1; otherwise, it outputs a 0.
However, this step function isn't suitable for multi-layer perceptrons that we use in deep learning. The step function contains only flat segments, and thus, its derivative is zero. This is problematic because during backpropagation (which we'll discuss later), we use the derivative of the activation function to update the weights and biases. If the derivative is zero, then the weights and biases will not get updated effectively during training, and the model might not learn at all.
Therefore, in multi-layer perceptrons, we use different types of activation functions, such as the sigmoid function, hyperbolic tangent function (tanh), and Rectified Linear Unit (ReLU). These functions are non-linear, continuous, and differentiable, which makes them suitable for backpropagation.
Here's a brief overview of these activation functions:
Sigmoid function
The sigmoid function is a mathematical function that maps real-valued inputs to a range between 0 and 1. It is widely used in machine learning and artificial neural networks to model nonlinear relationships between input and output variables.
Despite its usefulness, the sigmoid function suffers from the vanishing gradient problem, which is a common issue in deep learning. This problem occurs when the sigmoid function is used in deep neural networks with many layers. As the input to the function becomes larger, the gradient becomes smaller, making it difficult to train the network.
To overcome this issue, researchers have developed alternative activation functions, such as the ReLU function, which do not suffer from the vanishing gradient problem. However, the sigmoid function is still used in many applications due to its simplicity and ease of use.
Hyperbolic tangent function (tanh)
The tanh function is similar to the sigmoid function but squashes the input to range between -1 and 1. It also suffers from the vanishing gradient problem.
The hyperbolic tangent function, also known as the tanh function, is a mathematical function that is similar to the sigmoid function. It is defined as the ratio of the hyperbolic sine function to the hyperbolic cosine function. The main difference between the two functions is that while the sigmoid function squashes the input to a range between 0 and 1, the tanh function squashes the input to a range between -1 and 1. This means that the tanh function has a wider output range, which makes it more suitable for certain machine learning applications.
However, the tanh function is not without its drawbacks. One of the main issues with the tanh function is the vanishing gradient problem, which occurs when the gradients of the function become very small. This can make it difficult for neural networks to learn effectively, especially when the inputs are large or the network is deep. Nevertheless, the tanh function remains a popular choice for certain types of neural networks, especially those that require outputs between -1 and 1.
Rectified Linear Unit (ReLU)
The ReLU function is the most commonly used activation function in deep learning models. When compared to other activation functions, such as sigmoid or tanh, ReLU has been found to be more computationally efficient, making it a popular choice.
Additionally, ReLU has been shown to mitigate the vanishing gradient problem, which can occur in deep neural networks when using certain activation functions. This is because ReLU only sets negative values to 0, while leaving positive values unchanged, allowing for better propagation of gradients.
However, it is important to note that ReLU can suffer from the "dead neuron" problem, where neurons can become inactive and produce 0 for every input, resulting in a loss of learning. To address this issue, variants of ReLU, such as Leaky ReLU and Parametric ReLU, have been developed to provide a small slope for negative inputs, preventing neurons from becoming completely inactive.
Example:
Here's how you can implement these activation functions in a multi-layer perceptron using Keras:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer with sigmoid activation function
model.add(Dense(32, input_dim=8, activation='sigmoid'))
# Add a hidden layer with tanh activation function
model.add(Dense(32, activation='tanh'))
# Add a hidden layer with ReLU activation function
model.add(Dense(32, activation='relu'))
# Add an output layer with sigmoid activation function
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)
# Evaluate the model
score = model.evaluate(X, y, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
This example code creates a Sequential model with an input layer of 8 neurons, three hidden layers with 32 neurons each, and an output layer of 1 neuron. The first hidden layer uses sigmoid activation, the second hidden layer uses tanh activation, and the third hidden layer uses ReLU activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1 Perceptron and Multi-Layer Perceptron
Welcome to the exciting and rapidly advancing world of neural networks and deep learning! This chapter marks a significant shift in our journey as we move from traditional machine learning techniques to the realm of deep learning, which is a subset of machine learning. Due to its potential, deep learning has been at the forefront of many recent advancements in artificial intelligence, with its ability to enable self-driving cars, voice assistants, personalized recommendations, and much more.
In this chapter, we will start by introducing the basic building block of neural networks - the perceptron. This is a simple structure that can help us understand more complex structures such as multi-layer perceptrons. We will then move on to more complex structures and discuss how they form the basis for more advanced deep-learning models. We will also cover the key concepts and principles that underpin these models, including backpropagation and gradient descent, which are fundamental to the workings of neural networks.
Moreover, after providing a solid foundation in neural networks and deep learning, we will delve into the more advanced topics, including convolutional neural networks and recurrent neural networks, which are essential to understanding how deep learning models can be used in the real world. We will also explore how these models are used in natural language processing, image classification, and voice recognition. By the end of this chapter, you will be well-equipped to tackle the more advanced topics that await you in the exciting world of deep learning.
So, let's dive in and embark on this fascinating journey of discovery!
6.1.1 The Perceptron
The perceptron is the simplest form of a neural network. It was introduced by Frank Rosenblatt in the late 1950s. A perceptron takes several binary inputs, x1, x2, ..., and produces a single binary output:
In the modern sense, the perceptron is an algorithm for learning a binary classifier. That is a function that maps its input "x" (a real-valued vector) to an output value "f(x)" (a single binary value):
f(x) = 1 if w·x + b > 0, 0 otherwise
Here "w" is a vector of real-valued weights, "w·x" is the dot product ∑ᵢwᵢxᵢ, where "i" ranges over the indices of the vectors, and "b" is the bias, a constant term that does not depend on any input value.
Example:
Here's a simple implementation of a perceptron in Python:
import numpy as np
class Perceptron(object):
def __init__(self, no_of_inputs, threshold=100, learning_rate=0.01):
self.threshold = threshold
self.learning_rate = learning_rate
self.weights = np.zeros(no_of_inputs + 1) # Initialize weights to zeros
def predict(self, inputs):
summation = np.dot(inputs, self.weights[1:]) + self.weights[0] # Include bias term
activation = 1 if summation > 0 else 0 # Simplified activation calculation
return activation
def train(self, training_inputs, labels):
for _ in range(self.threshold):
for inputs, label in zip(training_inputs, labels):
prediction = self.predict(inputs)
# Update weights including bias term
update = self.learning_rate * (label - prediction)
self.weights[1:] += update * inputs
self.weights[0] += updateThis example code defines a class called Perceptron, which has three methods: __init__, predict, and train. The __init__ method initializes the object's attributes, the predict method predicts the output of the perceptron for a given input, and the train method trains the perceptron on a given set of training data.
The output of the code will depend on the training data that you use. For example, if you train the perceptron on a dataset of binary classification data, then the output of the train method will be a set of weights that can be used to classify new data.
6.1.2 Limitations of a Single Perceptron
While the perceptron forms the basis for neural networks, it has its limitations. Although it can learn many patterns, its capacity to learn can be limited by its design. One of the most significant limitations of a single perceptron is that it can only learn linearly separable patterns. This means that it can only separate data points with a straight line or a hyperplane in higher dimensions. As a result, more complex decision boundaries cannot be learned by a single perceptron. This is a significant limitation because many real-world problems are not linearly separable and require more complex decision boundaries, which a single perceptron may not be able to learn.
For example, consider the XOR problem, where we have four points in a 2D space: (0,0), (0,1), (1,0), and (1,1). The goal is to separate the points where the XOR of the coordinates is 1 from the points where the XOR is 0. This problem is not linearly separable, and a single perceptron cannot solve it. Therefore, to solve such problems, we need to use a more complex architecture that can learn non-linear decision boundaries. One such architecture is a multi-layer perceptron, which consists of multiple perceptrons arranged in layers to learn more complex patterns.
6.1.3 Multi-Layer Perceptron
To overcome the limitations of a single perceptron and further enhance its accuracy, we can use a multi-layer perceptron (MLP). The concept of an MLP is relatively simple: it consists of multiple layers of perceptrons, also known as neurons, with the output of one layer serving as the input for the next layer. This structure allows the MLP to learn more complex, non-linear patterns that a single perceptron would not be able to comprehend.
An MLP usually comprises an input layer, one or more hidden layers, and an output layer. Each of these layers consists of multiple neurons, and each neuron in a layer is connected to every neuron in the next layer. These connections are associated with weights, which are adjusted during the learning process to optimize the performance of the MLP.
The process of training an MLP is iterative and involves forward and backward propagation of the input signal. During forward propagation, the input signal is processed through the layers of neurons, with the output of each layer being passed on to the next layer. During backward propagation, the error in prediction is calculated and propagated backward through the layers to adjust the weights and improve the accuracy of the MLP.
Therefore, it is clear that an MLP is a more sophisticated and powerful form of neural network that can learn and recognize complex patterns. By adding more layers and neurons, an MLP can be trained to achieve higher levels of accuracy and can be used in various applications, such as image recognition, speech recognition, and natural language processing.
Example:
Here's a simple implementation of an MLP with one hidden layer in Python using the Keras library:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer
model.add(Dense(32, input_dim=8, activation='relu'))
# Add an output layer
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)This example code creates a Sequential model with an input layer of 8 neurons, a hidden layer of 32 neurons with ReLU activation, and an output layer of 1 neuron with sigmoid activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
In this example, X is the input data and y are the labels. The model has one hidden layer with 32 neurons, and the output layer uses the sigmoid activation function, which is suitable for binary classification.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1.4 Activation Functions
In the context of neural networks, an activation function defines the output of a neuron given a set of inputs. Biologically inspired by activity in our brains where different neurons fire, or are activated, by different stimuli, activation functions are used to add non-linearity to the learning process.
In the case of the perceptron, we used a simple step function as the activation function. If the weighted sum of the inputs is greater than a threshold, the perceptron fires and outputs a 1; otherwise, it outputs a 0.
However, this step function isn't suitable for multi-layer perceptrons that we use in deep learning. The step function contains only flat segments, and thus, its derivative is zero. This is problematic because during backpropagation (which we'll discuss later), we use the derivative of the activation function to update the weights and biases. If the derivative is zero, then the weights and biases will not get updated effectively during training, and the model might not learn at all.
Therefore, in multi-layer perceptrons, we use different types of activation functions, such as the sigmoid function, hyperbolic tangent function (tanh), and Rectified Linear Unit (ReLU). These functions are non-linear, continuous, and differentiable, which makes them suitable for backpropagation.
Here's a brief overview of these activation functions:
Sigmoid function
The sigmoid function is a mathematical function that maps real-valued inputs to a range between 0 and 1. It is widely used in machine learning and artificial neural networks to model nonlinear relationships between input and output variables.
Despite its usefulness, the sigmoid function suffers from the vanishing gradient problem, which is a common issue in deep learning. This problem occurs when the sigmoid function is used in deep neural networks with many layers. As the input to the function becomes larger, the gradient becomes smaller, making it difficult to train the network.
To overcome this issue, researchers have developed alternative activation functions, such as the ReLU function, which do not suffer from the vanishing gradient problem. However, the sigmoid function is still used in many applications due to its simplicity and ease of use.
Hyperbolic tangent function (tanh)
The tanh function is similar to the sigmoid function but squashes the input to range between -1 and 1. It also suffers from the vanishing gradient problem.
The hyperbolic tangent function, also known as the tanh function, is a mathematical function that is similar to the sigmoid function. It is defined as the ratio of the hyperbolic sine function to the hyperbolic cosine function. The main difference between the two functions is that while the sigmoid function squashes the input to a range between 0 and 1, the tanh function squashes the input to a range between -1 and 1. This means that the tanh function has a wider output range, which makes it more suitable for certain machine learning applications.
However, the tanh function is not without its drawbacks. One of the main issues with the tanh function is the vanishing gradient problem, which occurs when the gradients of the function become very small. This can make it difficult for neural networks to learn effectively, especially when the inputs are large or the network is deep. Nevertheless, the tanh function remains a popular choice for certain types of neural networks, especially those that require outputs between -1 and 1.
Rectified Linear Unit (ReLU)
The ReLU function is the most commonly used activation function in deep learning models. When compared to other activation functions, such as sigmoid or tanh, ReLU has been found to be more computationally efficient, making it a popular choice.
Additionally, ReLU has been shown to mitigate the vanishing gradient problem, which can occur in deep neural networks when using certain activation functions. This is because ReLU only sets negative values to 0, while leaving positive values unchanged, allowing for better propagation of gradients.
However, it is important to note that ReLU can suffer from the "dead neuron" problem, where neurons can become inactive and produce 0 for every input, resulting in a loss of learning. To address this issue, variants of ReLU, such as Leaky ReLU and Parametric ReLU, have been developed to provide a small slope for negative inputs, preventing neurons from becoming completely inactive.
Example:
Here's how you can implement these activation functions in a multi-layer perceptron using Keras:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer with sigmoid activation function
model.add(Dense(32, input_dim=8, activation='sigmoid'))
# Add a hidden layer with tanh activation function
model.add(Dense(32, activation='tanh'))
# Add a hidden layer with ReLU activation function
model.add(Dense(32, activation='relu'))
# Add an output layer with sigmoid activation function
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)
# Evaluate the model
score = model.evaluate(X, y, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
This example code creates a Sequential model with an input layer of 8 neurons, three hidden layers with 32 neurons each, and an output layer of 1 neuron. The first hidden layer uses sigmoid activation, the second hidden layer uses tanh activation, and the third hidden layer uses ReLU activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1 Perceptron and Multi-Layer Perceptron
Welcome to the exciting and rapidly advancing world of neural networks and deep learning! This chapter marks a significant shift in our journey as we move from traditional machine learning techniques to the realm of deep learning, which is a subset of machine learning. Due to its potential, deep learning has been at the forefront of many recent advancements in artificial intelligence, with its ability to enable self-driving cars, voice assistants, personalized recommendations, and much more.
In this chapter, we will start by introducing the basic building block of neural networks - the perceptron. This is a simple structure that can help us understand more complex structures such as multi-layer perceptrons. We will then move on to more complex structures and discuss how they form the basis for more advanced deep-learning models. We will also cover the key concepts and principles that underpin these models, including backpropagation and gradient descent, which are fundamental to the workings of neural networks.
Moreover, after providing a solid foundation in neural networks and deep learning, we will delve into the more advanced topics, including convolutional neural networks and recurrent neural networks, which are essential to understanding how deep learning models can be used in the real world. We will also explore how these models are used in natural language processing, image classification, and voice recognition. By the end of this chapter, you will be well-equipped to tackle the more advanced topics that await you in the exciting world of deep learning.
So, let's dive in and embark on this fascinating journey of discovery!
6.1.1 The Perceptron
The perceptron is the simplest form of a neural network. It was introduced by Frank Rosenblatt in the late 1950s. A perceptron takes several binary inputs, x1, x2, ..., and produces a single binary output:
In the modern sense, the perceptron is an algorithm for learning a binary classifier. That is a function that maps its input "x" (a real-valued vector) to an output value "f(x)" (a single binary value):
f(x) = 1 if w·x + b > 0, 0 otherwise
Here "w" is a vector of real-valued weights, "w·x" is the dot product ∑ᵢwᵢxᵢ, where "i" ranges over the indices of the vectors, and "b" is the bias, a constant term that does not depend on any input value.
Example:
Here's a simple implementation of a perceptron in Python:
import numpy as np
class Perceptron(object):
def __init__(self, no_of_inputs, threshold=100, learning_rate=0.01):
self.threshold = threshold
self.learning_rate = learning_rate
self.weights = np.zeros(no_of_inputs + 1) # Initialize weights to zeros
def predict(self, inputs):
summation = np.dot(inputs, self.weights[1:]) + self.weights[0] # Include bias term
activation = 1 if summation > 0 else 0 # Simplified activation calculation
return activation
def train(self, training_inputs, labels):
for _ in range(self.threshold):
for inputs, label in zip(training_inputs, labels):
prediction = self.predict(inputs)
# Update weights including bias term
update = self.learning_rate * (label - prediction)
self.weights[1:] += update * inputs
self.weights[0] += updateThis example code defines a class called Perceptron, which has three methods: __init__, predict, and train. The __init__ method initializes the object's attributes, the predict method predicts the output of the perceptron for a given input, and the train method trains the perceptron on a given set of training data.
The output of the code will depend on the training data that you use. For example, if you train the perceptron on a dataset of binary classification data, then the output of the train method will be a set of weights that can be used to classify new data.
6.1.2 Limitations of a Single Perceptron
While the perceptron forms the basis for neural networks, it has its limitations. Although it can learn many patterns, its capacity to learn can be limited by its design. One of the most significant limitations of a single perceptron is that it can only learn linearly separable patterns. This means that it can only separate data points with a straight line or a hyperplane in higher dimensions. As a result, more complex decision boundaries cannot be learned by a single perceptron. This is a significant limitation because many real-world problems are not linearly separable and require more complex decision boundaries, which a single perceptron may not be able to learn.
For example, consider the XOR problem, where we have four points in a 2D space: (0,0), (0,1), (1,0), and (1,1). The goal is to separate the points where the XOR of the coordinates is 1 from the points where the XOR is 0. This problem is not linearly separable, and a single perceptron cannot solve it. Therefore, to solve such problems, we need to use a more complex architecture that can learn non-linear decision boundaries. One such architecture is a multi-layer perceptron, which consists of multiple perceptrons arranged in layers to learn more complex patterns.
6.1.3 Multi-Layer Perceptron
To overcome the limitations of a single perceptron and further enhance its accuracy, we can use a multi-layer perceptron (MLP). The concept of an MLP is relatively simple: it consists of multiple layers of perceptrons, also known as neurons, with the output of one layer serving as the input for the next layer. This structure allows the MLP to learn more complex, non-linear patterns that a single perceptron would not be able to comprehend.
An MLP usually comprises an input layer, one or more hidden layers, and an output layer. Each of these layers consists of multiple neurons, and each neuron in a layer is connected to every neuron in the next layer. These connections are associated with weights, which are adjusted during the learning process to optimize the performance of the MLP.
The process of training an MLP is iterative and involves forward and backward propagation of the input signal. During forward propagation, the input signal is processed through the layers of neurons, with the output of each layer being passed on to the next layer. During backward propagation, the error in prediction is calculated and propagated backward through the layers to adjust the weights and improve the accuracy of the MLP.
Therefore, it is clear that an MLP is a more sophisticated and powerful form of neural network that can learn and recognize complex patterns. By adding more layers and neurons, an MLP can be trained to achieve higher levels of accuracy and can be used in various applications, such as image recognition, speech recognition, and natural language processing.
Example:
Here's a simple implementation of an MLP with one hidden layer in Python using the Keras library:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer
model.add(Dense(32, input_dim=8, activation='relu'))
# Add an output layer
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)This example code creates a Sequential model with an input layer of 8 neurons, a hidden layer of 32 neurons with ReLU activation, and an output layer of 1 neuron with sigmoid activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
In this example, X is the input data and y are the labels. The model has one hidden layer with 32 neurons, and the output layer uses the sigmoid activation function, which is suitable for binary classification.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.
6.1.4 Activation Functions
In the context of neural networks, an activation function defines the output of a neuron given a set of inputs. Biologically inspired by activity in our brains where different neurons fire, or are activated, by different stimuli, activation functions are used to add non-linearity to the learning process.
In the case of the perceptron, we used a simple step function as the activation function. If the weighted sum of the inputs is greater than a threshold, the perceptron fires and outputs a 1; otherwise, it outputs a 0.
However, this step function isn't suitable for multi-layer perceptrons that we use in deep learning. The step function contains only flat segments, and thus, its derivative is zero. This is problematic because during backpropagation (which we'll discuss later), we use the derivative of the activation function to update the weights and biases. If the derivative is zero, then the weights and biases will not get updated effectively during training, and the model might not learn at all.
Therefore, in multi-layer perceptrons, we use different types of activation functions, such as the sigmoid function, hyperbolic tangent function (tanh), and Rectified Linear Unit (ReLU). These functions are non-linear, continuous, and differentiable, which makes them suitable for backpropagation.
Here's a brief overview of these activation functions:
Sigmoid function
The sigmoid function is a mathematical function that maps real-valued inputs to a range between 0 and 1. It is widely used in machine learning and artificial neural networks to model nonlinear relationships between input and output variables.
Despite its usefulness, the sigmoid function suffers from the vanishing gradient problem, which is a common issue in deep learning. This problem occurs when the sigmoid function is used in deep neural networks with many layers. As the input to the function becomes larger, the gradient becomes smaller, making it difficult to train the network.
To overcome this issue, researchers have developed alternative activation functions, such as the ReLU function, which do not suffer from the vanishing gradient problem. However, the sigmoid function is still used in many applications due to its simplicity and ease of use.
Hyperbolic tangent function (tanh)
The tanh function is similar to the sigmoid function but squashes the input to range between -1 and 1. It also suffers from the vanishing gradient problem.
The hyperbolic tangent function, also known as the tanh function, is a mathematical function that is similar to the sigmoid function. It is defined as the ratio of the hyperbolic sine function to the hyperbolic cosine function. The main difference between the two functions is that while the sigmoid function squashes the input to a range between 0 and 1, the tanh function squashes the input to a range between -1 and 1. This means that the tanh function has a wider output range, which makes it more suitable for certain machine learning applications.
However, the tanh function is not without its drawbacks. One of the main issues with the tanh function is the vanishing gradient problem, which occurs when the gradients of the function become very small. This can make it difficult for neural networks to learn effectively, especially when the inputs are large or the network is deep. Nevertheless, the tanh function remains a popular choice for certain types of neural networks, especially those that require outputs between -1 and 1.
Rectified Linear Unit (ReLU)
The ReLU function is the most commonly used activation function in deep learning models. When compared to other activation functions, such as sigmoid or tanh, ReLU has been found to be more computationally efficient, making it a popular choice.
Additionally, ReLU has been shown to mitigate the vanishing gradient problem, which can occur in deep neural networks when using certain activation functions. This is because ReLU only sets negative values to 0, while leaving positive values unchanged, allowing for better propagation of gradients.
However, it is important to note that ReLU can suffer from the "dead neuron" problem, where neurons can become inactive and produce 0 for every input, resulting in a loss of learning. To address this issue, variants of ReLU, such as Leaky ReLU and Parametric ReLU, have been developed to provide a small slope for negative inputs, preventing neurons from becoming completely inactive.
Example:
Here's how you can implement these activation functions in a multi-layer perceptron using Keras:
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# Placeholder data (replace with your actual data)
X = np.random.rand(100, 8)
y = np.random.randint(2, size=(100, 1))
# Create a Sequential model
model = Sequential()
# Add an input layer and a hidden layer with sigmoid activation function
model.add(Dense(32, input_dim=8, activation='sigmoid'))
# Add a hidden layer with tanh activation function
model.add(Dense(32, activation='tanh'))
# Add a hidden layer with ReLU activation function
model.add(Dense(32, activation='relu'))
# Add an output layer with sigmoid activation function
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, y, epochs=150, batch_size=10)
# Evaluate the model
score = model.evaluate(X, y, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
This example code creates a Sequential model with an input layer of 8 neurons, three hidden layers with 32 neurons each, and an output layer of 1 neuron. The first hidden layer uses sigmoid activation, the second hidden layer uses tanh activation, and the third hidden layer uses ReLU activation. The model is compiled with binary crossentropy loss, Adam optimizer, and accuracy metrics. The model is fit on the data X and y for 150 epochs with a batch size of 10.
The output of the code will be a history object, which contains information about the training process, such as the loss and accuracy at each epoch. You can use the history object to evaluate the model's performance and to select the best hyperparameters.