
Capítulo 1: Generación de Imágenes y Visión con Modelos de OpenAI
1.3 Capacidades de Visión de GPT-4o
Con el lanzamiento de GPT-4o, OpenAI logró un avance significativo en inteligencia artificial al introducir soporte de visión multimodal nativo. Esta capacidad revolucionaria permite al modelo procesar simultáneamente información visual y textual, permitiéndole interpretar, analizar y razonar sobre imágenes con la misma sofisticación que aplica al procesamiento de texto. La comprensión visual del modelo es integral y versátil, siendo capaz de:
- Análisis Detallado de Imágenes: Convertir contenido visual en descripciones en lenguaje natural, identificando objetos, colores, patrones y relaciones espaciales.
- Interpretación Técnica: Procesar visualizaciones complejas como gráficos, diagramas y esquemas, extrayendo perspectivas y tendencias significativas.
- Procesamiento de Documentos: Leer y comprender varios formatos de documentos, desde notas manuscritas hasta formularios estructurados y dibujos técnicos.
- Detección de Problemas Visuales: Identificar problemas en interfaces de usuario, maquetas de diseño y layouts visuales, haciéndolo valioso para procesos de control de calidad y revisión de diseño.
En esta sección, obtendrás conocimiento práctico sobre la integración de las capacidades visuales de GPT-4o en tus aplicaciones. Cubriremos los aspectos técnicos de enviar imágenes como entrada, explorando tanto la extracción de datos estructurados como enfoques de procesamiento de lenguaje natural. Aprenderás a implementar aplicaciones del mundo real como:
- Sistemas interactivos de preguntas y respuestas visuales que pueden responder preguntas sobre el contenido de imágenes
Soluciones automatizadas de procesamiento de formularios para gestión documental
Sistemas avanzados de reconocimiento de objetos para diversas industrias
Herramientas de accesibilidad que pueden describir imágenes para usuarios con discapacidad visual
1.3.1 ¿Qué es GPT-4o Vision?
GPT-4o ("o" de "omni") representa un salto revolucionario en la tecnología de inteligencia artificial al lograr una integración perfecta de las capacidades de procesamiento de lenguaje y visual en un único modelo unificado. Esta integración es particularmente innovadora porque refleja la capacidad natural del cerebro humano para procesar múltiples tipos de información simultáneamente. Así como los humanos pueden combinar sin esfuerzo señales visuales con información verbal para entender su entorno, GPT-4o puede procesar e interpretar tanto texto como imágenes de manera unificada e inteligente.
La arquitectura técnica de GPT-4o representa una desviación significativa de los modelos tradicionales de IA. Los sistemas anteriores típicamente requerían una cadena compleja de modelos separados - uno para procesamiento de imágenes, otro para análisis de texto, y componentes adicionales para conectar estos sistemas separados. Estos enfoques más antiguos no solo eran computacionalmente intensivos, sino que a menudo resultaban en pérdida de información entre pasos de procesamiento. GPT-4o elimina estas ineficiencias al manejar todo el procesamiento dentro de un sistema único y optimizado. Los usuarios ahora pueden enviar tanto imágenes como texto a través de una simple llamada API, haciendo la tecnología más accesible y fácil de implementar.
Lo que verdaderamente distingue a GPT-4o es su sofisticada arquitectura neural que permite una verdadera comprensión multimodal. En lugar de tratar el texto y las imágenes como entradas separadas que se procesan independientemente, el modelo crea un espacio semántico unificado donde la información visual y textual pueden interactuar e informarse mutuamente.
Esto significa que al analizar un gráfico, por ejemplo, GPT-4o no solo realiza reconocimiento óptico de caracteres o reconocimiento básico de patrones - realmente comprende la relación entre elementos visuales, datos numéricos y contexto textual. Esta integración profunda le permite proporcionar respuestas matizadas y conscientes del contexto que extraen tanto de los elementos visuales como textuales de la entrada, muy similar a como lo haría un experto humano al analizar información compleja.
Requisitos Clave para la Integración de Visión
- Selección del Modelo: GPT-4o debe ser especificado explícitamente como tu elección de modelo. Esto es crucial ya que las versiones anteriores de GPT no soportan capacidades de visión. La designación 'o' indica la versión omni-modal con capacidades de procesamiento visual. Al implementar características de visión, asegurarse de usar GPT-4o es esencial para acceder al rango completo de capacidades de análisis visual y lograr un rendimiento óptimo.
- Proceso de Carga de Imágenes: Tu implementación debe manejar adecuadamente las cargas de archivos de imagen a través del endpoint dedicado de carga de imágenes de OpenAI. Esto implica:
- Convertir la imagen a un formato apropiado: Asegurar que las imágenes estén en formatos soportados (PNG, JPEG) y cumplan con las limitaciones de tamaño. El sistema acepta imágenes de hasta 20MB de tamaño.
- Generar un identificador de archivo seguro: La API crea un identificador único para cada imagen cargada, permitiendo referencias seguras en llamadas API subsecuentes mientras mantiene la privacidad de los datos.
- Gestionar adecuadamente el ciclo de vida del archivo cargado: Implementar procedimientos apropiados de limpieza para eliminar archivos cargados cuando ya no se necesiten, ayudando a mantener la eficiencia y seguridad del sistema.
- Ingeniería de Prompts: Aunque el modelo puede procesar imágenes independientemente, combinarlas con prompts de texto bien elaborados a menudo produce mejores resultados. Puedes:
- Hacer preguntas específicas sobre la imagen: Formular consultas precisas que apunten a la información exacta que necesitas, como "¿De qué color es el auto en primer plano?" o "¿Cuántas personas llevan sombreros?"
- Solicitar tipos particulares de análisis: Especificar el tipo de análisis necesario, ya sea técnico (medición, conteo), descriptivo (colores, formas), o interpretativo (emociones, estilo).
- Guiar la atención del modelo a aspectos o regiones específicas: Dirigir al modelo para que se enfoque en áreas o elementos particulares dentro de la imagen para un análisis más detallado, como "Mira la esquina superior derecha" o "Concéntrate en el texto en el centro."
Ejemplo: Analizar un Gráfico desde una Imagen
Veamos paso a paso cómo enviar una imagen (por ejemplo, un gráfico de barras o captura de pantalla) a GPT-4o y hacerle una pregunta específica.
Ejemplo Paso a Paso en Python
Paso 1: Cargar la Imagen a OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Analicemos este código:
- Declaraciones de Importación
openai: Biblioteca principal para interactuar con la API de OpenAIos: Para manejar variables de entornodotenv: Carga variables de entorno desde un archivo .env
- Configuración del Entorno
- Carga las variables de entorno usando
load_dotenv() - Establece la clave API de OpenAI desde las variables de entorno para la autenticación
- Carga de Imagen
- Crea una nueva carga de archivo usando
openai.files.create() - Abre 'sales_chart.png' en modo de lectura binaria (
'rb') - Especifica el propósito como "vision" para el procesamiento de imágenes
Este código representa el primer paso para utilizar las capacidades de visión de GPT-4o, lo cual es necesario antes de poder analizar imágenes con el modelo. El identificador del archivo de imagen devuelto por esta carga puede usarse posteriormente en llamadas a la API.
Paso 2: Enviar Imagen + Prompt de Texto a GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Analicemos este código:
- Estructura de la Llamada API:
- Utiliza el método ChatCompletion.create() de OpenAI
- Especifica "gpt-4o" como el modelo, lo cual es necesario para las capacidades de visión
- Formato del Mensaje:
- Crea un array de mensajes con un único mensaje de usuario
- El contenido es un array que contiene dos elementos:
- Un elemento de texto con el prompt solicitando el análisis del gráfico
- Un elemento image_url que hace referencia al archivo previamente cargado
- Parámetros:
- Establece max_tokens en 300 para limitar la longitud de la respuesta
- Utiliza el ID del archivo del paso de carga previo
- Manejo de la Salida:
- Imprime "GPT-4o Vision Response:"
- Extrae y muestra la respuesta del modelo desde el array de opciones
Este código demuestra cómo combinar entradas tanto de texto como de imagen en un único prompt, permitiendo que GPT-4o analice contenido visual y proporcione información basada en la pregunta específica realizada.
En este ejemplo, estás enviando tanto un prompt de texto como una imagen en el mismo mensaje. GPT-4o analiza la entrada visual y la combina con tus instrucciones.
1.3.2 Casos de Uso para Visión en GPT-4o
Las capacidades de visión de GPT-4o abren un amplio rango de aplicaciones prácticas a través de varias industrias y casos de uso. Desde mejorar la accesibilidad hasta automatizar tareas complejas de análisis visual, la capacidad del modelo para entender e interpretar imágenes ha transformado cómo interactuamos con datos visuales. Esta sección explora las diversas aplicaciones de las capacidades de visión de GPT-4o, demostrando cómo las organizaciones y desarrolladores pueden aprovechar esta tecnología para resolver problemas del mundo real y crear soluciones innovadoras.
Al examinar casos de uso específicos y ejemplos de implementación, veremos cómo las capacidades de comprensión visual de GPT-4o pueden aplicarse a tareas que van desde la simple descripción de imágenes hasta el análisis técnico complejo. Estas aplicaciones muestran la versatilidad del modelo y su potencial para revolucionar los flujos de trabajo en campos como la salud, educación, diseño y documentación técnica.
Análisis Detallado de Imágenes
La conversión de contenido visual en descripciones en lenguaje natural es una de las capacidades más poderosas y sofisticadas de GPT-4o. El modelo demuestra una notable habilidad en el análisis integral de escenas, descomponiendo metódicamente las imágenes en sus componentes fundamentales con excepcional precisión y detalle. A través del procesamiento neural avanzado, puede realizar múltiples niveles de análisis simultáneamente:
- Identificar objetos individuales y sus características - desde elementos simples como forma y tamaño hasta características complejas como nombres de marca, condiciones y variaciones específicas de objetos
- Describir relaciones espaciales entre elementos - analizando con precisión cómo los objetos están posicionados entre sí, incluyendo percepción de profundidad, superposición y disposiciones jerárquicas en el espacio tridimensional
- Reconocer colores, texturas y patrones con alta precisión - distinguiendo entre variaciones sutiles de tonos, propiedades complejas de materiales y repeticiones o irregularidades intrincadas de patrones
- Detectar detalles visuales sutiles que podrían pasar desapercibidos por sistemas convencionales de visión por computadora - incluyendo sombras, reflejos, oclusiones parciales y efectos ambientales que afectan la apariencia de los objetos
- Comprender relaciones contextuales entre objetos en una escena - interpretando cómo diferentes elementos interactúan entre sí, su probable propósito o función, y el contexto general del entorno
Estas capacidades sofisticadas permiten una amplia gama de aplicaciones prácticas. En la catalogación automatizada de imágenes, el sistema puede crear descripciones detalladas y buscables de grandes bases de datos de imágenes. Para usuarios con discapacidad visual, proporciona descripciones ricas y contextuales que pintan una imagen completa de la escena visual. La versatilidad del modelo se extiende al procesamiento de varios tipos de contenido visual:
- Fotos de productos - descripciones detalladas de características, materiales y elementos de diseño
- Dibujos arquitectónicos - interpretación de detalles técnicos, medidas y relaciones espaciales
- Escenas naturales - análisis exhaustivo de paisajes, condiciones climáticas y características ambientales
- Situaciones sociales - comprensión de interacciones humanas, expresiones y lenguaje corporal
Esta capacidad permite aplicaciones que van desde la catalogación automatizada de imágenes hasta la descripción detallada de escenas para usuarios con discapacidad visual. El modelo puede procesar desde simples fotos de productos hasta complejos dibujos arquitectónicos, proporcionando descripciones ricas y contextuales que capturan elementos visuales tanto obvios como sutiles.
Ejemplo: Sistemas Interactivos de Preguntas y Respuestas Visuales
Este código enviará una imagen (desde un archivo local) y un prompt multi-parte al modelo GPT-4o para mostrar estos diferentes tipos de análisis en una sola respuesta.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para realizar análisis detallados de imágenes, combinando varios casos de uso discutidos: generación de descripciones de accesibilidad, reconocimiento de objetos y respuesta a preguntas contextuales sobre el contenido visual.
- Requisitos previos: Enumera la biblioteca necesaria (
openai,python-dotenv), cómo manejar la clave API de forma segura (usando un archivo.env), y la necesidad de un archivo de imagen de muestra. - Codificación de imagen: Incluye una función auxiliar
encode_image_to_base64para convertir un archivo de imagen local al formato URI de datos base64 requerido por la API cuando no se usa una URL pública directa. También realiza verificaciones básicas del tipo de archivo. - Cliente API: Inicializa el cliente estándar de OpenAI, cargando la clave API desde las variables de entorno. Incluye manejo de errores para claves faltantes o problemas de inicialización.
- Prompt Multi-Modal: El núcleo de la solicitud es la estructura de
messages.- Contiene un único mensaje de usuario.
- El
contentde este mensaje es una lista que contiene múltiples partes:- Una parte de
textque contiene las instrucciones (el prompt que solicita descripción, lista de objetos y contexto). - Una parte de
image_url. Crucialmente, el campourldentro deimage_urlse establece como el URIdata:[media_type];base64,[encoded_string]generado por la función auxiliar. El parámetrodetailpuede ajustarse (low,high,auto) para influir en la profundidad del análisis y el costo de tokens.
- Una parte de
- Llamada a la API (
client.chat.completions.create):- Especifica
model="gpt-4o". - Pasa la lista estructurada de
messages. - Establece
max_tokenspara controlar la longitud de la respuesta.
- Especifica
- Manejo de Respuesta: Extrae el contenido de texto del campo
choices[0].message.contentde la respuesta de la API y lo imprime. También muestra cómo acceder a la información de uso de tokens. - Manejo de Errores: Incluye bloques
try...exceptpara errores de API (OpenAIError) y excepciones generales, proporcionando sugerencias para problemas comunes como marcadores de política de contenido o imágenes inválidas. - Capacidades Demostradas: Esta única llamada a la API muestra efectivamente:
- Accesibilidad: El modelo genera una descripción textual adecuada para lectores de pantalla.
- Reconocimiento de Objetos: Identifica y enumera los objetos presentes en la imagen.
- Preguntas y Respuestas Visuales/Inferencia: Responde preguntas sobre el contexto y posibles actividades basándose en evidencia visual.
Este ejemplo proporciona una demostración práctica y completa de las capacidades de visión de GPT-4o para la comprensión detallada de imágenes en el contexto de tu capítulo del libro. Recuerda reemplazar "sample_scene.jpg" con un archivo de imagen real para realizar pruebas.
Interpretación Técnica y Análisis de Datos
El procesamiento de visualizaciones complejas como gráficos, diagramas y esquemas requiere una comprensión sofisticada para extraer insights y tendencias significativas. El sistema demuestra capacidades notables en la traducción de datos visuales a información procesable.
Esto incluye la capacidad de:
- Analizar datos cuantitativos presentados en varios formatos de gráficos (gráficos de barras, gráficos de líneas, diagramas de dispersión) e identificar patrones clave, valores atípicos y correlaciones. Por ejemplo, puede detectar tendencias estacionales en gráficos de líneas, identificar puntos de datos inusuales en diagramas de dispersión y comparar proporciones en gráficos de barras.
- Interpretar diagramas técnicos complejos como planos arquitectónicos, esquemas de ingeniería e ilustraciones científicas con precisión detallada. Esto incluye la comprensión de dibujos a escala, diagramas de circuitos eléctricos, estructuras moleculares e instrucciones de ensamblaje mecánico.
- Extraer valores numéricos, etiquetas y leyendas de visualizaciones manteniendo la precisión contextual. El sistema puede leer e interpretar etiquetas de ejes, valores de puntos de datos, entradas de leyendas y notas al pie, asegurando que toda la información cuantitativa se capture con precisión.
- Comparar múltiples puntos de datos o tendencias a través de diferentes períodos de tiempo o categorías para proporcionar insights analíticos completos. Esto incluye comparaciones año tras año, análisis entre categorías e identificación de tendencias multivariables.
- Traducir información estadística visual en explicaciones escritas claras que los usuarios no técnicos puedan entender, desglosando relaciones de datos complejas en un lenguaje accesible mientras preserva la precisión de la información subyacente.
Ejemplo:
Este código enviará un archivo de imagen (por ejemplo, un gráfico de barras) y prompts específicos a GPT-4o, solicitándole identificar el tipo de gráfico, comprender los datos presentados y extraer insights o tendencias clave.
Descarga una muestra del archivo "sales_chart.png" https://files.cuantum.tech/images/sales-chart.png
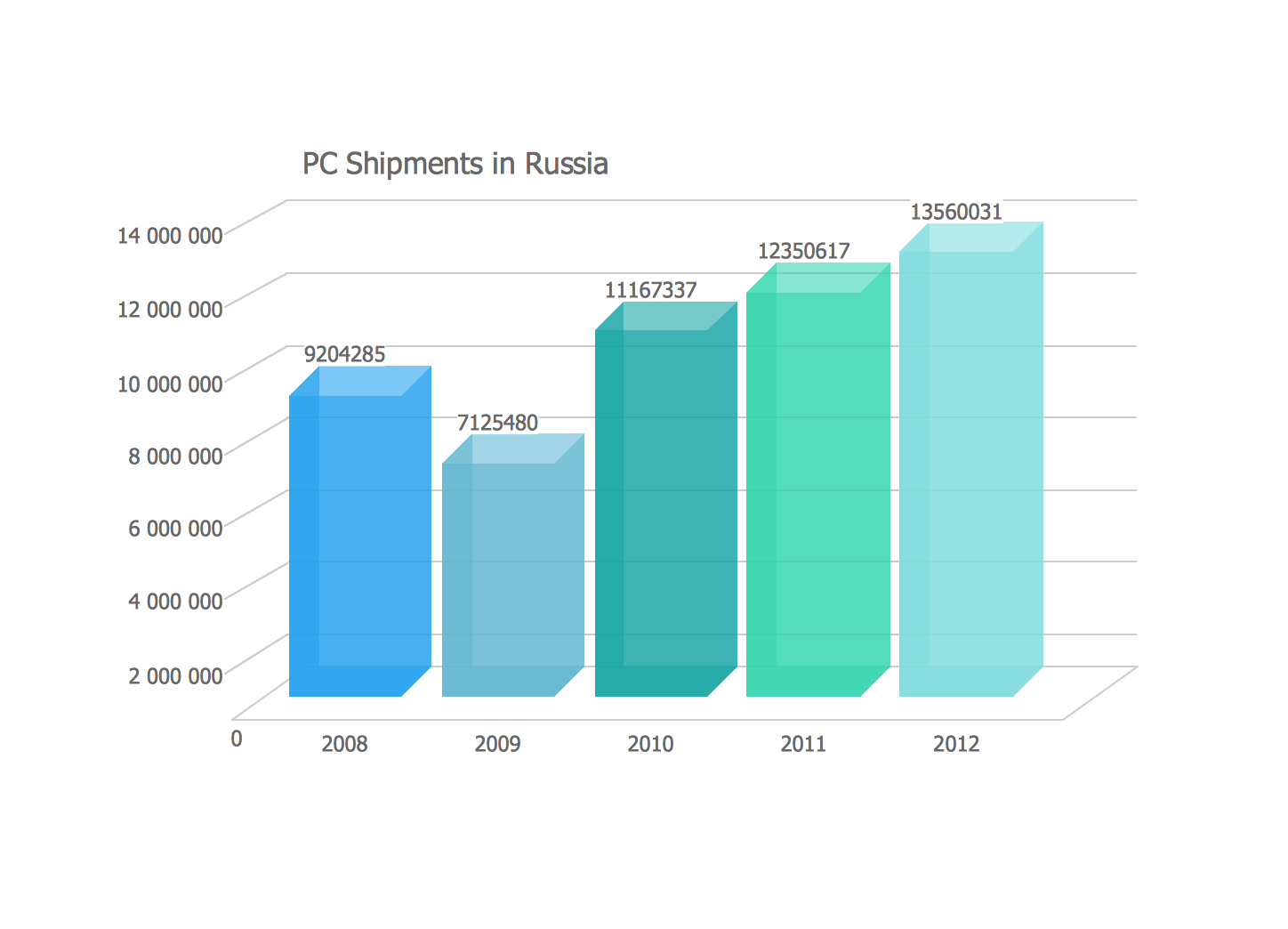{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para la interpretación técnica, específicamente para analizar representaciones visuales de datos como gráficos y diagramas. En lugar de simplemente describir la imagen, el objetivo es extraer insights significativos y comprender los datos presentados.
- Requisitos previos: Requisitos de configuración similares: bibliotecas
openai,python-dotenv, clave API en.env, y lo más importante, un archivo de imagen que contenga un gráfico o diagrama (sales_chart.pngusado como ejemplo). - Codificación de imagen: Utiliza la misma función
encode_image_to_base64para preparar el archivo de imagen local para la API. - Diseño del prompt para interpretación: El prompt está cuidadosamente elaborado para guiar a GPT-4o hacia el análisis en lugar de una simple descripción. Hace preguntas específicas sobre:
- Tipo de gráfico: Identificación básica.
- Representación de datos: Comprensión de ejes, unidades y categorías.
- Insights y tendencias clave: La tarea analítica principal – resumir patrones, máximos/mínimos.
- Puntos de datos específicos: Probando la capacidad de leer valores aproximados del gráfico.
- Resumen general: Un mensaje conciso de conclusiones.
- Información contextual: Incluye la fecha actual y nombre del archivo como referencia dentro del prompt.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multipartes que contiene el prompt analítico de texto y la imagen del gráfico codificada en base64.
- Establece
detailcomo"high"en la parte deimage_url, sugiriendo al modelo que use más recursos para un análisis potencialmente más preciso de los detalles visuales en el gráfico (esto puede aumentar el costo de tokens). - Asigna potencialmente más
max_tokens(por ejemplo, 700) anticipando una respuesta analítica más detallada en comparación con una descripción simple.
- Apunta al modelo
- Manejo de respuesta: Extrae e imprime el análisis textual proporcionado por GPT-4o. Incluye detalles de uso de tokens.
- Manejo de errores: Verificaciones estándar para errores de API y problemas de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Interpretación Técnica" al mostrar cómo GPT-4o puede procesar visualizaciones complejas, extraer puntos de datos, identificar tendencias y proporcionar resúmenes, convirtiendo datos visuales en insights accionables. Esto es valioso para flujos de trabajo de análisis de datos, generación de informes y comprensión de documentos técnicos.
Recuerda usar una imagen clara y de alta resolución de un gráfico o diagrama para obtener mejores resultados al probar este código. Reemplaza "sales_chart.png" con la ruta correcta a tu archivo de imagen.
Procesamiento de Documentos
GPT-4o demuestra capacidades excepcionales en el procesamiento y análisis de diversos formatos de documentos, sirviendo como una solución integral para el análisis de documentos y la extracción de información. Este sistema avanzado aprovecha la sofisticada visión por computadora y el procesamiento del lenguaje natural para manejar una amplia gama de tipos de documentos con notable precisión. Aquí hay un desglose detallado de sus capacidades de procesamiento de documentos:
- Documentos manuscritos: El sistema sobresale en la interpretación de contenido manuscrito a través de múltiples estilos y formatos. Puede:
- Reconocer con precisión diferentes estilos de escritura a mano, desde cursiva pulcra hasta garabatos apresurados
- Procesar tanto documentos formales como notas informales con alta precisión
- Manejar múltiples idiomas y caracteres especiales en forma manuscrita
- Formularios estructurados: Demuestra una capacidad superior en el procesamiento de documentación estandarizada con:
- Extracción precisa de campos de datos clave de formularios complejos
- Organización automática de la información extraída en formatos estructurados
- Validación de la consistencia de datos a través de múltiples campos del formulario
- Documentación técnica: Muestra comprensión avanzada de materiales técnicos especializados a través de:
- Interpretación detallada de notaciones y símbolos técnicos complejos
- Comprensión de información de escala y dimensiones en dibujos
- Reconocimiento de especificaciones técnicas y terminología estándar de la industria
- Documentos de formato mixto: Demuestra capacidades versátiles de procesamiento mediante:
- Integración perfecta de información de texto, imágenes y elementos gráficos
- Mantenimiento del contexto a través de diferentes tipos de contenido dentro del mismo documento
- Procesamiento de diseños complejos con múltiples jerarquías de información
- Documentos antiguos: Ofrece un manejo sofisticado de materiales históricos mediante:
- Adaptación a varios niveles de degradación y envejecimiento de documentos
- Procesamiento de estilos de formato y tipografía obsoletos
- Mantenimiento del contexto histórico mientras hace el contenido accesible en formatos modernos
Ejemplo:
Este código enviará una imagen de un documento (como una factura o recibo) a GPT-4o y le solicitará identificar el tipo de documento y extraer información específica, como nombre del vendedor, fecha, monto total y elementos detallados.
Descarga una muestra del archivo "sample_invoice.png" https://files.cuantum.tech/images/sample_invoice.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o en el procesamiento de documentos, un caso de uso clave que implica la comprensión y extracción de información de imágenes de documentos como facturas, recibos, formularios o notas.
- Requisitos previos: Requiere la configuración estándar: bibliotecas
openai,python-dotenv, clave API y un archivo de imagen del documento a procesar (sample_invoice.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64convierte la imagen local del documento al formato requerido para la API. - Diseño del prompt para extracción: El prompt es crucial para el procesamiento de documentos. Solicita explícitamente al modelo:
- Identificar el tipo de documento.
- Extraer una lista predefinida de campos específicos (Vendedor, Fecha, Total, Artículos, etc.). Solicitar "No encontrado" para campos faltantes fomenta una salida estructurada.
- Proporcionar un resumen.
- Incluir el nombre del archivo y la marca de tiempo actual proporciona contexto.
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o. - Envía el mensaje multipartes con el prompt de texto y la imagen del documento codificada en base64.
- Utiliza
detail: "high"para la imagen, lo cual puede ser beneficioso para mejorar la precisión del Reconocimiento Óptico de Caracteres (OCR) y la comprensión del texto dentro de la imagen del documento, aunque utiliza más tokens. - Establece
max_tokenspara acomodar información potencialmente extensa, especialmente líneas de artículos.
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta de texto de GPT-4o, que debe contener el tipo de documento identificado y los campos extraídos según lo solicitado por el prompt. También se muestra el uso de tokens.
- Manejo de errores: Incluye verificaciones para errores de API y problemas del sistema de archivos, con sugerencias específicas para posibles problemas de procesamiento de imágenes.
- Relevancia del caso de uso: Aborda directamente el caso de uso de "Procesamiento de Documentos". Demuestra cómo la visión de GPT-4o puede automatizar tareas como la entrada de datos de facturas/recibos, el resumen de correspondencia o incluso la interpretación de notas manuscritas, agilizando significativamente los flujos de trabajo que involucran el procesamiento de documentos visuales.
Para pruebas, use una imagen clara de un documento. La precisión de la extracción dependerá de la calidad de la imagen, la claridad del diseño del documento y la legibilidad del texto. Recuerde reemplazar "sample_invoice.png" con la ruta a su imagen de documento real.
Detección de Problemas Visuales
La Detección de Problemas Visuales es una capacidad sofisticada de IA que revoluciona la forma en que identificamos y analizamos problemas visuales en activos digitales. Esta tecnología avanzada aprovecha algoritmos de visión por computadora y aprendizaje automático para escanear y evaluar automáticamente elementos visuales, detectando problemas que podrían pasar desapercibidos para los revisores humanos. Examina sistemáticamente varios aspectos del contenido visual, encontrando inconsistencias, errores y problemas de usabilidad en:
- Interfaces de usuario: Detectando elementos mal alineados, diseños rotos, estilos inconsistentes y problemas de accesibilidad. Esta capacidad realiza un análisis integral de elementos de UI, incluyendo:
- Colocación de botones y zonas de interacción para garantizar una experiencia de usuario óptima
- Alineación y validación de campos de formulario para mantener la armonía visual
- Consistencia del menú de navegación a través de diferentes páginas y estados
- Relaciones de contraste de color para cumplimiento WCAG y estándares de accesibilidad
- Espaciado de elementos interactivos y dimensionamiento de puntos de contacto para compatibilidad móvil
- Maquetas de diseño: Identificando problemas de espaciado, problemas de contraste de color y desviaciones de las pautas de diseño. El sistema realiza análisis detallados incluyendo:
- Mediciones de relleno y margen según especificaciones establecidas
- Verificación de consistencia del esquema de color en todos los elementos de diseño
- Verificación de jerarquía tipográfica para legibilidad y consistencia de marca
- Cumplimiento de biblioteca de componentes y adherencia al sistema de diseño
- Evaluación de ritmo visual y balance en diseños
- Diseños visuales: Detectando errores tipográficos, problemas de alineación de cuadrícula y fallos de diseño responsivo. Esto implica un análisis sofisticado de:
- Patrones de uso de fuentes a través de diferentes tipos y secciones de contenido
- Optimización de espaciado de texto y altura de línea para legibilidad
- Cumplimiento del sistema de cuadrícula en varios tamaños de viewport
- Pruebas de comportamiento responsivo en puntos de quiebre estándar
- Consistencia de diseño a través de diferentes dispositivos y orientaciones
Esta capacidad se ha vuelto indispensable para los equipos de control de calidad y diseñadores en el mantenimiento de altos estándares en productos digitales. Al implementar la Detección de Problemas Visuales:
- Los equipos pueden automatizar hasta el 80% de los procesos de control de calidad visual
- La precisión de detección alcanza el 95% para problemas visuales comunes
- Los ciclos de revisión se reducen en un promedio del 60%
La tecnología acelera significativamente el proceso de revisión al marcar automáticamente posibles problemas antes de que lleguen a producción. Este enfoque proactivo no solo reduce la necesidad de inspección manual que consume tiempo, sino que también mejora la calidad general del producto al garantizar estándares visuales consistentes en todos los activos digitales. El resultado son ciclos de desarrollo más rápidos, costos reducidos y entregables de mayor calidad que cumplen tanto con estándares técnicos como estéticos.
Ejemplo:
Este código envía una imagen de una interfaz de usuario (UI) o una captura de pantalla de diseño a GPT-4o y le solicita identificar posibles defectos de diseño, problemas de usabilidad, inconsistencias y otros problemas visuales.
Descarga una muestra del archivo "ui_mockup.png" https://files.cuantum.tech/images/ui_mockup.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este ejemplo de código muestra la capacidad de GPT-4o para la detección de problemas visuales, particularmente útil en revisiones de diseño UI/UX, control de calidad (QA) e identificación de posibles problemas en diseños visuales o maquetas.
- Requisitos previos: Configuración estándar que involucra
openai,python-dotenv, configuración de la clave API y un archivo de imagen de entrada que representa un diseño UI o maqueta (ui_mockup.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64se utiliza para preparar el archivo de imagen local para la solicitud API. - Diseño del prompt para revisión: El prompt está específicamente estructurado para guiar a GPT-4o a actuar como revisor de UI/UX. Solicita al modelo buscar problemas dentro de categorías definidas comunes en críticas de diseño:
- Diseño y Alineación
- Tipografía
- Color y Contraste (mencionando accesibilidad/WCAG como punto clave)
- Consistencia
- Usabilidad y Claridad
- Principios Generales de Diseño
De manera crucial, pregunta el por qué algo es un problema, solicitando justificación más allá de la simple identificación.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multi-parte que contiene el prompt detallado de revisión y la imagen codificada en base64.
- Utiliza
detail: "high"para la imagen, potencialmente mejorando la capacidad del modelo para percibir detalles visuales sutiles como ligeras desalineaciones o problemas de renderizado de texto. - Establece
max_tokenspara permitir una lista completa de posibles problemas y explicaciones.
- Apunta al modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener una lista estructurada de problemas visuales identificados basados en las categorías del prompt. También se proporciona el uso de tokens.
- Manejo de errores: Incluye verificaciones estándar para errores de API y problemas del sistema de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Detección de Problemas Visuales". Demuestra cómo la IA puede ayudar a diseñadores y desarrolladores al escanear automáticamente interfaces en busca de fallos comunes, potencialmente acelerando el proceso de revisión, detectando problemas temprano y mejorando la calidad general y usabilidad de los productos digitales.
Para pruebas efectivas, use una imagen de UI que incluya fallos de diseño intencional o no intencionalmente. Recuerde reemplazar "ui_mockup.png" con la ruta a su archivo de imagen real.
1.3.3 Casos de Uso Compatibles para Visión en GPT-4o
Las capacidades de visión de GPT-4o van mucho más allá del simple reconocimiento de imágenes, ofreciendo una amplia gama de aplicaciones que pueden transformar la manera en que interactuamos con el contenido visual. Esta sección explora los diversos casos de uso donde se puede aprovechar la comprensión visual de GPT-4o para crear aplicaciones más inteligentes y receptivas.
Desde el análisis de diagramas complejos hasta la provisión de descripciones detalladas de imágenes, las características de visión de GPT-4o permiten a los desarrolladores construir soluciones que cierran la brecha entre la comprensión visual y textual. Estas capacidades pueden ser particularmente valiosas en campos como la educación, la accesibilidad, la moderación de contenido y el análisis automatizado.
Exploremos los casos de uso clave donde brillan las capacidades de visión de GPT-4o, junto con ejemplos prácticos y estrategias de implementación que demuestran su versatilidad en aplicaciones del mundo real.
| Caso de Uso | Ejemplo | Explicación |
| Generación de pies de foto | "Describe esta imagen en detalle." | Convierte contenido visual en descripciones textuales detalladas, útil para catalogación de contenido, accesibilidad e indexación automatizada de imágenes. |
| Análisis de interfaz de usuario | "¿Hay errores visuales en esta captura de pantalla de la página web?" | Examina interfaces de usuario en busca de inconsistencias de diseño, problemas de alineación y de usabilidad, ayudando a agilizar los procesos de control de calidad. |
| Lectura de documentos | "Extrae el número de factura y la fecha de este escaneo." | Procesa documentos escaneados para extraer información específica, automatizando flujos de trabajo de entrada de datos y procesamiento de documentos. |
| Interpretación de visualización de datos | "Resume este gráfico circular en lenguaje sencillo." | Traduce representaciones visuales complejas de datos en descripciones narrativas claras, haciendo los datos más accesibles para todos los usuarios. |
| Preguntas y respuestas educativas | "¿Qué figura geométrica es esta? ¿Cuáles son sus propiedades?" | Proporciona apoyo al aprendizaje interactivo mediante el análisis y explicación de contenido educativo visual, ayudando a los estudiantes a comprender conceptos complejos. |
| Soporte de accesibilidad | "Lee en voz alta el contenido de esta imagen." | Mejora la accesibilidad digital proporcionando descripciones detalladas del contenido visual para usuarios con discapacidades visuales. |
1.3.4 Mejores Prácticas para Prompts de Visión
La creación de prompts efectivos para modelos de IA habilitados para visión requiere un enfoque diferente en comparación con las interacciones solo de texto. Si bien los principios fundamentales de comunicación clara siguen siendo importantes, los prompts visuales necesitan tener en cuenta la naturaleza espacial, contextual y multimodal del análisis de imágenes. Esta sección explora estrategias clave y mejores prácticas para ayudarte a crear prompts basados en visión más efectivos que maximicen las capacidades de comprensión visual de GPT-4o.
Ya sea que estés construyendo aplicaciones para análisis de imágenes, procesamiento de documentos o control de calidad visual, entender estas mejores prácticas te ayudará a:
- Obtener respuestas más precisas y relevantes del modelo
- Reducir la ambigüedad en tus solicitudes
- Estructurar tus prompts para tareas complejas de análisis visual
- Optimizar la interacción entre elementos textuales y visuales
Exploremos los principios fundamentales que te ayudarán a crear prompts más efectivos basados en visión:
Sé directo con tu solicitud:
Ejemplo 1 (Prompt Inefectivo):
"¿Cuáles son las características principales en esta habitación?"
Este prompt tiene varios problemas:
- Es demasiado amplio y poco enfocado
- Carece de criterios específicos sobre qué constituye una "característica principal"
- Puede resultar en respuestas inconsistentes o superficiales
- No guía a la IA hacia ningún aspecto particular de análisis
Ejemplo 2 (Prompt Efectivo):
"Identifica todos los dispositivos electrónicos en esta sala de estar y describe su posición."
Este prompt es superior porque:
- Define claramente qué buscar (dispositivos electrónicos)
- Especifica el alcance (sala de estar)
- Solicita información específica (posición/ubicación)
- Generará información estructurada y procesable
- Facilita verificar si la IA omitió algo
La diferencia clave es que el segundo prompt proporciona parámetros claros para el análisis y un tipo específico de salida, lo que hace mucho más probable recibir información útil y relevante que sirva a tu propósito previsto.
Combina con texto cuando sea necesario
Una imagen por sí sola puede ser suficiente para una descripción básica, pero combinarla con un prompt bien elaborado mejora significativamente las capacidades analíticas del modelo y la precisión de la salida. La clave es proporcionar un contexto claro y específico que guíe la atención del modelo hacia los aspectos más relevantes para tus necesidades.
Por ejemplo, en lugar de solo subir una imagen, añade prompts contextuales detallados como:
- "Analiza este plano arquitectónico enfocándote en posibles riesgos de seguridad, particularmente en áreas de escaleras y salidas"
- "Revisa esta gráfica y explica la tendencia entre 2020-2023, destacando cualquier patrón estacional y anomalía"
- "Examina esta maqueta de interfaz de usuario e identifica problemas de accesibilidad para usuarios con discapacidades visuales"
Este enfoque ofrece varias ventajas:
- Enfoca el análisis del modelo en características o preocupaciones específicas
- Reduce observaciones irrelevantes o superficiales
- Asegura respuestas más consistentes y estructuradas
- Permite un análisis más profundo y matizado de elementos visuales complejos
- Ayuda a generar perspectivas y recomendaciones más procesables
La combinación de entrada visual con guía textual precisa ayuda al modelo a entender exactamente qué aspectos de la imagen son más importantes para tu caso de uso, resultando en respuestas más valiosas y dirigidas.
Utiliza seguimientos estructurados
Después de completar un análisis visual inicial, puedes aprovechar el hilo de conversación para realizar una investigación más exhaustiva mediante preguntas de seguimiento estructuradas. Este enfoque te permite construir sobre las observaciones iniciales del modelo y extraer información más detallada y específica. Las preguntas de seguimiento ayudan a crear un proceso de análisis más interactivo y completo.
Así es como usar efectivamente los seguimientos estructurados:
- Profundizar en detalles específicos
- Ejemplo: "¿Puedes describir las luminarias en más detalle?"
- Esto ayuda a enfocar la atención del modelo en elementos particulares que necesitan un examen más cercano
- Útil para análisis técnico o documentación detallada
- Comparar elementos
- Ejemplo: "¿Cómo se compara la distribución de la habitación A con la habitación B?"
- Permite la comparación sistemática de diferentes componentes o áreas
- Ayuda a identificar patrones, inconsistencias o relaciones
- Obtener recomendaciones
- Ejemplo: "Basado en este plano, ¿qué mejoras sugerirías?"
- Aprovecha la comprensión del modelo para generar perspectivas prácticas
- Puede llevar a retroalimentación procesable para mejoras
Al usar seguimientos estructurados, creas una interacción más dinámica que puede descubrir perspectivas más profundas y una comprensión más matizada del contenido visual que estás analizando.
1.3.5 Entrada de Múltiples Imágenes
Puedes enviar múltiples imágenes en un solo mensaje si tu caso de uso requiere comparación entre imágenes. Esta potente función te permite analizar relaciones entre imágenes, comparar diferentes versiones de diseños o evaluar cambios a lo largo del tiempo. El modelo procesa todas las imágenes simultáneamente, permitiendo un análisis sofisticado de múltiples imágenes que típicamente requeriría varias solicitudes separadas.
Esto es lo que puedes hacer con la entrada de múltiples imágenes:
- Comparar Iteraciones de Diseño
- Analizar cambios de UI/UX entre versiones
- Seguir la progresión de implementaciones de diseño
- Identificar consistencia entre diferentes pantallas
- Análisis de Documentos
- Comparar múltiples versiones de documentos
- Hacer referencias cruzadas de documentación relacionada
- Verificar la autenticidad de documentos
- Análisis Temporal
- Revisar escenarios de antes y después
- Rastrear cambios en datos visuales a lo largo del tiempo
- Monitorear el progreso en proyectos visuales
El modelo procesa estas imágenes contextualmente, comprendiendo sus relaciones y proporcionando un análisis integral. Puede identificar patrones, inconsistencias, mejoras y relaciones entre todas las imágenes proporcionadas, ofreciendo perspectivas detalladas que serían difíciles de obtener mediante el análisis de una sola imagen.
Ejemplo:
Este código envía dos imágenes (por ejemplo, dos versiones de una maqueta de UI) junto con un prompt de texto en una sola llamada a la API, pidiendo al modelo que las compare e identifique diferencias.
Descarga una muestra del archivo "image_path_1.png" https://files.cuantum.tech/images/image_path_1.png
{kind=link}
Descarga una muestra del archivo "image_path_2.png" https://files.cuantum.tech/images/image_path_2.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Desglose del código:
- Contexto: Este código demuestra la capacidad de entrada múltiple de imágenes de GPT-4o, permitiendo a los usuarios enviar varias imágenes en una sola solicitud de API para tareas como comparación, análisis de relaciones o síntesis de información entre elementos visuales. El ejemplo se centra en comparar dos maquetas de interfaz de usuario para identificar diferencias.
- Requisitos previos: Requiere la configuración estándar (
openai,python-dotenv, clave API) pero específicamente necesita dos archivos de imagen de entrada para la tarea de comparación (ui_mockup_v1.pngyui_mockup_v2.pngusados como marcadores de posición). - Codificación de imágenes: La función
encode_image_to_base64se utiliza dos veces, una vez para cada imagen de entrada. El manejo de errores asegura que ambas imágenes se procesen correctamente antes de continuar. - Estructura de la solicitud API: La diferencia clave está en la lista
messages[0]["content"]. Ahora contiene:- Un diccionario de
type: "text"para el prompt. - Múltiples diccionarios de
type: "image_url", uno para cada imagen que se envía. Las imágenes se incluyen secuencialmente después del prompt de texto.
- Un diccionario de
- Diseño del prompt para tareas multi-imagen: El prompt hace referencia explícita a las dos imágenes (por ejemplo, "la primera imagen", "la segunda imagen", o por nombre de archivo como se hace aquí) y establece claramente la tarea que involucra ambas imágenes (por ejemplo, "Compara la Versión 1 y la Versión 2", "enumera las diferencias").
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o, que admite entradas múltiples de imágenes. - Envía la lista estructurada de
messagesque contiene el prompt de texto y múltiples imágenes codificadas en base64. - Establece
max_tokensapropiado para la salida esperada (una lista de diferencias).
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener los resultados de la comparación basados en el prompt y las dos imágenes proporcionadas. El uso de tokens refleja el procesamiento del texto y todas las imágenes.
- Manejo de errores: Incluye verificaciones estándar, enfatizando posibles problemas con cualquiera de los archivos de imagen.
- Relevancia de casos de uso: Esto aborda directamente la capacidad de "Entrada Multi-Imagen". Es útil para comparación de versiones (diseños, documentos), análisis de secuencias (fotos de antes/después), combinación de información de diferentes fuentes visuales (por ejemplo, fotos de productos + tabla de tallas), o cualquier tarea donde se requiera entender la relación o diferencias entre múltiples imágenes.
Recuerda proporcionar dos archivos de imagen distintos (por ejemplo, dos versiones diferentes de una maqueta de UI) al probar este código, y actualizar las variables image_path_1 y image_path_2 según corresponda.
1.3.6 Privacidad y Seguridad
A medida que los sistemas de IA procesan y analizan cada vez más datos visuales, entender las implicaciones de privacidad y seguridad se vuelve fundamental. Esta sección explora los aspectos críticos de la protección de datos de imagen al trabajar con modelos de IA habilitados para visión, cubriendo todo desde protocolos básicos de seguridad hasta mejores prácticas para el manejo responsable de datos.
Examinaremos las medidas técnicas de seguridad implementadas, las estrategias de gestión de datos y las consideraciones esenciales de privacidad que los desarrolladores deben abordar al construir aplicaciones que procesan imágenes enviadas por usuarios. Entender estos principios es crucial para mantener la confianza del usuario y asegurar el cumplimiento de las regulaciones de protección de datos.
Las áreas clave que cubriremos incluyen:
- Protocolos de seguridad para la transmisión y almacenamiento de datos de imagen
- Mejores prácticas para gestionar contenido visual enviado por usuarios
- Consideraciones de privacidad y requisitos de cumplimiento
- Estrategias de implementación para procesamiento seguro de imágenes
Exploremos en detalle las medidas de seguridad integrales y consideraciones de privacidad que son esenciales para proteger datos visuales:
- Carga segura de imágenes y autenticación API:
- Los datos de imagen están protegidos mediante encriptación avanzada durante el tránsito utilizando protocolos TLS estándar de la industria, asegurando la seguridad de extremo a extremo
- Un sistema robusto de autenticación asegura que el acceso esté estrictamente limitado a solicitudes verificadas con tus credenciales API específicas, previniendo accesos no autorizados
- El sistema implementa aislamiento estricto - las imágenes asociadas con tu clave API permanecen completamente separadas e inaccesibles para otros usuarios o claves API, manteniendo la soberanía de datos
- Estrategias efectivas de gestión de datos de imagen:
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
openai.files.delete(file_id), dándote control completo sobre la retención de datos - Las mejores prácticas incluyen implementar sistemas automatizados de limpieza que eliminen regularmente las cargas temporales de imágenes, reduciendo riesgos de seguridad y sobrecarga de almacenamiento
- Las auditorías sistemáticas regulares de archivos almacenados son cruciales para mantener una organización óptima de datos y cumplimiento de seguridad
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
- Protección integral de privacidad del usuario:
- Implementar mecanismos explícitos de consentimiento del usuario antes de que comience cualquier análisis de imagen, asegurando transparencia y confianza
- Desarrollar e integrar flujos claros de consentimiento dentro de tu aplicación que informen a los usuarios sobre cómo se procesarán sus imágenes
- Crear políticas de privacidad detalladas que explícitamente describan los procedimientos de procesamiento de imágenes, limitaciones de uso y medidas de protección de datos
- Establecer y comunicar claramente políticas específicas de retención de datos, incluyendo cuánto tiempo se almacenan las imágenes y cuándo se eliminan automáticamente
Resumen
En esta sección, has adquirido conocimientos exhaustivos sobre las revolucionarias capacidades de visión de GPT-4o, que transforman fundamentalmente cómo los sistemas de IA procesan y comprenden el contenido visual. Esta característica revolucionaria va mucho más allá del procesamiento tradicional de texto, permitiendo a la IA realizar análisis detallados de imágenes con una comprensión similar a la humana. A través de redes neuronales avanzadas y sofisticados algoritmos de visión por computadora, el sistema puede identificar objetos, interpretar escenas, comprender el contexto e incluso reconocer detalles sutiles dentro de las imágenes. Con una eficiencia y facilidad de implementación notables, puedes aprovechar estas potentes capacidades a través de una API simplificada que procesa simultáneamente tanto imágenes como comandos en lenguaje natural.
Esta tecnología innovadora representa un cambio de paradigma en las aplicaciones de IA, abriendo una amplia gama de implementaciones prácticas en numerosos dominios:
- Educación: Crear experiencias de aprendizaje dinámicas e interactivas con explicaciones visuales y tutoría automatizada basada en imágenes
- Generar ayudas visuales personalizadas para conceptos complejos
- Proporcionar retroalimentación en tiempo real sobre dibujos o diagramas de estudiantes
- Accesibilidad: Desarrollar herramientas sofisticadas que proporcionen descripciones detalladas de imágenes para usuarios con discapacidad visual
- Generar descripciones contextuales de imágenes con detalles relevantes
- Crear narrativas de audio a partir de contenido visual
- Análisis: Realizar análisis sofisticados de datos visuales para inteligencia empresarial e investigación
- Extraer información de gráficos, diagramas y esquemas técnicos
- Analizar tendencias en datos visuales a través de grandes conjuntos de datos
- Automatización: Optimizar flujos de trabajo con procesamiento y categorización automatizada de imágenes
- Clasificar y etiquetar automáticamente contenido visual
- Procesar documentos con contenido mixto de texto e imágenes
A lo largo de esta exploración exhaustiva, has dominado varias capacidades esenciales que forman la base de la implementación de IA visual:
- Cargar e interpretar imágenes: Domina los fundamentos técnicos de integrar la API en tus aplicaciones, incluyendo el formato adecuado de imágenes, procedimientos eficientes de carga y comprensión de los diversos parámetros que afectan la precisión de interpretación. Aprende a recibir y analizar interpretaciones detalladas y contextualizadas que pueden impulsar el procesamiento posterior.
- Usar prompts multimodales con texto + imagen: Desarrolla experiencia en la creación de prompts efectivos que combinen perfectamente instrucciones textuales con entradas visuales. Comprende cómo estructurar consultas que aprovechen ambas modalidades para obtener resultados más precisos y matizados. Aprende técnicas avanzadas de prompting que pueden guiar la atención de la IA hacia aspectos específicos de las imágenes.
- Construir asistentes que ven antes de hablar: Crea aplicaciones sofisticadas de IA que procesan información visual como parte fundamental de su proceso de toma de decisiones. Aprende a desarrollar sistemas que pueden entender el contexto tanto de entradas visuales como textuales, lo que lleva a interacciones más inteligentes, naturales y conscientes del contexto que verdaderamente conectan la brecha entre la comprensión humana y la máquina.
1.3 Capacidades de Visión de GPT-4o
Con el lanzamiento de GPT-4o, OpenAI logró un avance significativo en inteligencia artificial al introducir soporte de visión multimodal nativo. Esta capacidad revolucionaria permite al modelo procesar simultáneamente información visual y textual, permitiéndole interpretar, analizar y razonar sobre imágenes con la misma sofisticación que aplica al procesamiento de texto. La comprensión visual del modelo es integral y versátil, siendo capaz de:
- Análisis Detallado de Imágenes: Convertir contenido visual en descripciones en lenguaje natural, identificando objetos, colores, patrones y relaciones espaciales.
- Interpretación Técnica: Procesar visualizaciones complejas como gráficos, diagramas y esquemas, extrayendo perspectivas y tendencias significativas.
- Procesamiento de Documentos: Leer y comprender varios formatos de documentos, desde notas manuscritas hasta formularios estructurados y dibujos técnicos.
- Detección de Problemas Visuales: Identificar problemas en interfaces de usuario, maquetas de diseño y layouts visuales, haciéndolo valioso para procesos de control de calidad y revisión de diseño.
En esta sección, obtendrás conocimiento práctico sobre la integración de las capacidades visuales de GPT-4o en tus aplicaciones. Cubriremos los aspectos técnicos de enviar imágenes como entrada, explorando tanto la extracción de datos estructurados como enfoques de procesamiento de lenguaje natural. Aprenderás a implementar aplicaciones del mundo real como:
- Sistemas interactivos de preguntas y respuestas visuales que pueden responder preguntas sobre el contenido de imágenes
Soluciones automatizadas de procesamiento de formularios para gestión documental
Sistemas avanzados de reconocimiento de objetos para diversas industrias
Herramientas de accesibilidad que pueden describir imágenes para usuarios con discapacidad visual
1.3.1 ¿Qué es GPT-4o Vision?
GPT-4o ("o" de "omni") representa un salto revolucionario en la tecnología de inteligencia artificial al lograr una integración perfecta de las capacidades de procesamiento de lenguaje y visual en un único modelo unificado. Esta integración es particularmente innovadora porque refleja la capacidad natural del cerebro humano para procesar múltiples tipos de información simultáneamente. Así como los humanos pueden combinar sin esfuerzo señales visuales con información verbal para entender su entorno, GPT-4o puede procesar e interpretar tanto texto como imágenes de manera unificada e inteligente.
La arquitectura técnica de GPT-4o representa una desviación significativa de los modelos tradicionales de IA. Los sistemas anteriores típicamente requerían una cadena compleja de modelos separados - uno para procesamiento de imágenes, otro para análisis de texto, y componentes adicionales para conectar estos sistemas separados. Estos enfoques más antiguos no solo eran computacionalmente intensivos, sino que a menudo resultaban en pérdida de información entre pasos de procesamiento. GPT-4o elimina estas ineficiencias al manejar todo el procesamiento dentro de un sistema único y optimizado. Los usuarios ahora pueden enviar tanto imágenes como texto a través de una simple llamada API, haciendo la tecnología más accesible y fácil de implementar.
Lo que verdaderamente distingue a GPT-4o es su sofisticada arquitectura neural que permite una verdadera comprensión multimodal. En lugar de tratar el texto y las imágenes como entradas separadas que se procesan independientemente, el modelo crea un espacio semántico unificado donde la información visual y textual pueden interactuar e informarse mutuamente.
Esto significa que al analizar un gráfico, por ejemplo, GPT-4o no solo realiza reconocimiento óptico de caracteres o reconocimiento básico de patrones - realmente comprende la relación entre elementos visuales, datos numéricos y contexto textual. Esta integración profunda le permite proporcionar respuestas matizadas y conscientes del contexto que extraen tanto de los elementos visuales como textuales de la entrada, muy similar a como lo haría un experto humano al analizar información compleja.
Requisitos Clave para la Integración de Visión
- Selección del Modelo: GPT-4o debe ser especificado explícitamente como tu elección de modelo. Esto es crucial ya que las versiones anteriores de GPT no soportan capacidades de visión. La designación 'o' indica la versión omni-modal con capacidades de procesamiento visual. Al implementar características de visión, asegurarse de usar GPT-4o es esencial para acceder al rango completo de capacidades de análisis visual y lograr un rendimiento óptimo.
- Proceso de Carga de Imágenes: Tu implementación debe manejar adecuadamente las cargas de archivos de imagen a través del endpoint dedicado de carga de imágenes de OpenAI. Esto implica:
- Convertir la imagen a un formato apropiado: Asegurar que las imágenes estén en formatos soportados (PNG, JPEG) y cumplan con las limitaciones de tamaño. El sistema acepta imágenes de hasta 20MB de tamaño.
- Generar un identificador de archivo seguro: La API crea un identificador único para cada imagen cargada, permitiendo referencias seguras en llamadas API subsecuentes mientras mantiene la privacidad de los datos.
- Gestionar adecuadamente el ciclo de vida del archivo cargado: Implementar procedimientos apropiados de limpieza para eliminar archivos cargados cuando ya no se necesiten, ayudando a mantener la eficiencia y seguridad del sistema.
- Ingeniería de Prompts: Aunque el modelo puede procesar imágenes independientemente, combinarlas con prompts de texto bien elaborados a menudo produce mejores resultados. Puedes:
- Hacer preguntas específicas sobre la imagen: Formular consultas precisas que apunten a la información exacta que necesitas, como "¿De qué color es el auto en primer plano?" o "¿Cuántas personas llevan sombreros?"
- Solicitar tipos particulares de análisis: Especificar el tipo de análisis necesario, ya sea técnico (medición, conteo), descriptivo (colores, formas), o interpretativo (emociones, estilo).
- Guiar la atención del modelo a aspectos o regiones específicas: Dirigir al modelo para que se enfoque en áreas o elementos particulares dentro de la imagen para un análisis más detallado, como "Mira la esquina superior derecha" o "Concéntrate en el texto en el centro."
Ejemplo: Analizar un Gráfico desde una Imagen
Veamos paso a paso cómo enviar una imagen (por ejemplo, un gráfico de barras o captura de pantalla) a GPT-4o y hacerle una pregunta específica.
Ejemplo Paso a Paso en Python
Paso 1: Cargar la Imagen a OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Analicemos este código:
- Declaraciones de Importación
openai: Biblioteca principal para interactuar con la API de OpenAIos: Para manejar variables de entornodotenv: Carga variables de entorno desde un archivo .env
- Configuración del Entorno
- Carga las variables de entorno usando
load_dotenv() - Establece la clave API de OpenAI desde las variables de entorno para la autenticación
- Carga de Imagen
- Crea una nueva carga de archivo usando
openai.files.create() - Abre 'sales_chart.png' en modo de lectura binaria (
'rb') - Especifica el propósito como "vision" para el procesamiento de imágenes
Este código representa el primer paso para utilizar las capacidades de visión de GPT-4o, lo cual es necesario antes de poder analizar imágenes con el modelo. El identificador del archivo de imagen devuelto por esta carga puede usarse posteriormente en llamadas a la API.
Paso 2: Enviar Imagen + Prompt de Texto a GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Analicemos este código:
- Estructura de la Llamada API:
- Utiliza el método ChatCompletion.create() de OpenAI
- Especifica "gpt-4o" como el modelo, lo cual es necesario para las capacidades de visión
- Formato del Mensaje:
- Crea un array de mensajes con un único mensaje de usuario
- El contenido es un array que contiene dos elementos:
- Un elemento de texto con el prompt solicitando el análisis del gráfico
- Un elemento image_url que hace referencia al archivo previamente cargado
- Parámetros:
- Establece max_tokens en 300 para limitar la longitud de la respuesta
- Utiliza el ID del archivo del paso de carga previo
- Manejo de la Salida:
- Imprime "GPT-4o Vision Response:"
- Extrae y muestra la respuesta del modelo desde el array de opciones
Este código demuestra cómo combinar entradas tanto de texto como de imagen en un único prompt, permitiendo que GPT-4o analice contenido visual y proporcione información basada en la pregunta específica realizada.
En este ejemplo, estás enviando tanto un prompt de texto como una imagen en el mismo mensaje. GPT-4o analiza la entrada visual y la combina con tus instrucciones.
1.3.2 Casos de Uso para Visión en GPT-4o
Las capacidades de visión de GPT-4o abren un amplio rango de aplicaciones prácticas a través de varias industrias y casos de uso. Desde mejorar la accesibilidad hasta automatizar tareas complejas de análisis visual, la capacidad del modelo para entender e interpretar imágenes ha transformado cómo interactuamos con datos visuales. Esta sección explora las diversas aplicaciones de las capacidades de visión de GPT-4o, demostrando cómo las organizaciones y desarrolladores pueden aprovechar esta tecnología para resolver problemas del mundo real y crear soluciones innovadoras.
Al examinar casos de uso específicos y ejemplos de implementación, veremos cómo las capacidades de comprensión visual de GPT-4o pueden aplicarse a tareas que van desde la simple descripción de imágenes hasta el análisis técnico complejo. Estas aplicaciones muestran la versatilidad del modelo y su potencial para revolucionar los flujos de trabajo en campos como la salud, educación, diseño y documentación técnica.
Análisis Detallado de Imágenes
La conversión de contenido visual en descripciones en lenguaje natural es una de las capacidades más poderosas y sofisticadas de GPT-4o. El modelo demuestra una notable habilidad en el análisis integral de escenas, descomponiendo metódicamente las imágenes en sus componentes fundamentales con excepcional precisión y detalle. A través del procesamiento neural avanzado, puede realizar múltiples niveles de análisis simultáneamente:
- Identificar objetos individuales y sus características - desde elementos simples como forma y tamaño hasta características complejas como nombres de marca, condiciones y variaciones específicas de objetos
- Describir relaciones espaciales entre elementos - analizando con precisión cómo los objetos están posicionados entre sí, incluyendo percepción de profundidad, superposición y disposiciones jerárquicas en el espacio tridimensional
- Reconocer colores, texturas y patrones con alta precisión - distinguiendo entre variaciones sutiles de tonos, propiedades complejas de materiales y repeticiones o irregularidades intrincadas de patrones
- Detectar detalles visuales sutiles que podrían pasar desapercibidos por sistemas convencionales de visión por computadora - incluyendo sombras, reflejos, oclusiones parciales y efectos ambientales que afectan la apariencia de los objetos
- Comprender relaciones contextuales entre objetos en una escena - interpretando cómo diferentes elementos interactúan entre sí, su probable propósito o función, y el contexto general del entorno
Estas capacidades sofisticadas permiten una amplia gama de aplicaciones prácticas. En la catalogación automatizada de imágenes, el sistema puede crear descripciones detalladas y buscables de grandes bases de datos de imágenes. Para usuarios con discapacidad visual, proporciona descripciones ricas y contextuales que pintan una imagen completa de la escena visual. La versatilidad del modelo se extiende al procesamiento de varios tipos de contenido visual:
- Fotos de productos - descripciones detalladas de características, materiales y elementos de diseño
- Dibujos arquitectónicos - interpretación de detalles técnicos, medidas y relaciones espaciales
- Escenas naturales - análisis exhaustivo de paisajes, condiciones climáticas y características ambientales
- Situaciones sociales - comprensión de interacciones humanas, expresiones y lenguaje corporal
Esta capacidad permite aplicaciones que van desde la catalogación automatizada de imágenes hasta la descripción detallada de escenas para usuarios con discapacidad visual. El modelo puede procesar desde simples fotos de productos hasta complejos dibujos arquitectónicos, proporcionando descripciones ricas y contextuales que capturan elementos visuales tanto obvios como sutiles.
Ejemplo: Sistemas Interactivos de Preguntas y Respuestas Visuales
Este código enviará una imagen (desde un archivo local) y un prompt multi-parte al modelo GPT-4o para mostrar estos diferentes tipos de análisis en una sola respuesta.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para realizar análisis detallados de imágenes, combinando varios casos de uso discutidos: generación de descripciones de accesibilidad, reconocimiento de objetos y respuesta a preguntas contextuales sobre el contenido visual.
- Requisitos previos: Enumera la biblioteca necesaria (
openai,python-dotenv), cómo manejar la clave API de forma segura (usando un archivo.env), y la necesidad de un archivo de imagen de muestra. - Codificación de imagen: Incluye una función auxiliar
encode_image_to_base64para convertir un archivo de imagen local al formato URI de datos base64 requerido por la API cuando no se usa una URL pública directa. También realiza verificaciones básicas del tipo de archivo. - Cliente API: Inicializa el cliente estándar de OpenAI, cargando la clave API desde las variables de entorno. Incluye manejo de errores para claves faltantes o problemas de inicialización.
- Prompt Multi-Modal: El núcleo de la solicitud es la estructura de
messages.- Contiene un único mensaje de usuario.
- El
contentde este mensaje es una lista que contiene múltiples partes:- Una parte de
textque contiene las instrucciones (el prompt que solicita descripción, lista de objetos y contexto). - Una parte de
image_url. Crucialmente, el campourldentro deimage_urlse establece como el URIdata:[media_type];base64,[encoded_string]generado por la función auxiliar. El parámetrodetailpuede ajustarse (low,high,auto) para influir en la profundidad del análisis y el costo de tokens.
- Una parte de
- Llamada a la API (
client.chat.completions.create):- Especifica
model="gpt-4o". - Pasa la lista estructurada de
messages. - Establece
max_tokenspara controlar la longitud de la respuesta.
- Especifica
- Manejo de Respuesta: Extrae el contenido de texto del campo
choices[0].message.contentde la respuesta de la API y lo imprime. También muestra cómo acceder a la información de uso de tokens. - Manejo de Errores: Incluye bloques
try...exceptpara errores de API (OpenAIError) y excepciones generales, proporcionando sugerencias para problemas comunes como marcadores de política de contenido o imágenes inválidas. - Capacidades Demostradas: Esta única llamada a la API muestra efectivamente:
- Accesibilidad: El modelo genera una descripción textual adecuada para lectores de pantalla.
- Reconocimiento de Objetos: Identifica y enumera los objetos presentes en la imagen.
- Preguntas y Respuestas Visuales/Inferencia: Responde preguntas sobre el contexto y posibles actividades basándose en evidencia visual.
Este ejemplo proporciona una demostración práctica y completa de las capacidades de visión de GPT-4o para la comprensión detallada de imágenes en el contexto de tu capítulo del libro. Recuerda reemplazar "sample_scene.jpg" con un archivo de imagen real para realizar pruebas.
Interpretación Técnica y Análisis de Datos
El procesamiento de visualizaciones complejas como gráficos, diagramas y esquemas requiere una comprensión sofisticada para extraer insights y tendencias significativas. El sistema demuestra capacidades notables en la traducción de datos visuales a información procesable.
Esto incluye la capacidad de:
- Analizar datos cuantitativos presentados en varios formatos de gráficos (gráficos de barras, gráficos de líneas, diagramas de dispersión) e identificar patrones clave, valores atípicos y correlaciones. Por ejemplo, puede detectar tendencias estacionales en gráficos de líneas, identificar puntos de datos inusuales en diagramas de dispersión y comparar proporciones en gráficos de barras.
- Interpretar diagramas técnicos complejos como planos arquitectónicos, esquemas de ingeniería e ilustraciones científicas con precisión detallada. Esto incluye la comprensión de dibujos a escala, diagramas de circuitos eléctricos, estructuras moleculares e instrucciones de ensamblaje mecánico.
- Extraer valores numéricos, etiquetas y leyendas de visualizaciones manteniendo la precisión contextual. El sistema puede leer e interpretar etiquetas de ejes, valores de puntos de datos, entradas de leyendas y notas al pie, asegurando que toda la información cuantitativa se capture con precisión.
- Comparar múltiples puntos de datos o tendencias a través de diferentes períodos de tiempo o categorías para proporcionar insights analíticos completos. Esto incluye comparaciones año tras año, análisis entre categorías e identificación de tendencias multivariables.
- Traducir información estadística visual en explicaciones escritas claras que los usuarios no técnicos puedan entender, desglosando relaciones de datos complejas en un lenguaje accesible mientras preserva la precisión de la información subyacente.
Ejemplo:
Este código enviará un archivo de imagen (por ejemplo, un gráfico de barras) y prompts específicos a GPT-4o, solicitándole identificar el tipo de gráfico, comprender los datos presentados y extraer insights o tendencias clave.
Descarga una muestra del archivo "sales_chart.png" https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para la interpretación técnica, específicamente para analizar representaciones visuales de datos como gráficos y diagramas. En lugar de simplemente describir la imagen, el objetivo es extraer insights significativos y comprender los datos presentados.
- Requisitos previos: Requisitos de configuración similares: bibliotecas
openai,python-dotenv, clave API en.env, y lo más importante, un archivo de imagen que contenga un gráfico o diagrama (sales_chart.pngusado como ejemplo). - Codificación de imagen: Utiliza la misma función
encode_image_to_base64para preparar el archivo de imagen local para la API. - Diseño del prompt para interpretación: El prompt está cuidadosamente elaborado para guiar a GPT-4o hacia el análisis en lugar de una simple descripción. Hace preguntas específicas sobre:
- Tipo de gráfico: Identificación básica.
- Representación de datos: Comprensión de ejes, unidades y categorías.
- Insights y tendencias clave: La tarea analítica principal – resumir patrones, máximos/mínimos.
- Puntos de datos específicos: Probando la capacidad de leer valores aproximados del gráfico.
- Resumen general: Un mensaje conciso de conclusiones.
- Información contextual: Incluye la fecha actual y nombre del archivo como referencia dentro del prompt.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multipartes que contiene el prompt analítico de texto y la imagen del gráfico codificada en base64.
- Establece
detailcomo"high"en la parte deimage_url, sugiriendo al modelo que use más recursos para un análisis potencialmente más preciso de los detalles visuales en el gráfico (esto puede aumentar el costo de tokens). - Asigna potencialmente más
max_tokens(por ejemplo, 700) anticipando una respuesta analítica más detallada en comparación con una descripción simple.
- Apunta al modelo
- Manejo de respuesta: Extrae e imprime el análisis textual proporcionado por GPT-4o. Incluye detalles de uso de tokens.
- Manejo de errores: Verificaciones estándar para errores de API y problemas de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Interpretación Técnica" al mostrar cómo GPT-4o puede procesar visualizaciones complejas, extraer puntos de datos, identificar tendencias y proporcionar resúmenes, convirtiendo datos visuales en insights accionables. Esto es valioso para flujos de trabajo de análisis de datos, generación de informes y comprensión de documentos técnicos.
Recuerda usar una imagen clara y de alta resolución de un gráfico o diagrama para obtener mejores resultados al probar este código. Reemplaza "sales_chart.png" con la ruta correcta a tu archivo de imagen.
Procesamiento de Documentos
GPT-4o demuestra capacidades excepcionales en el procesamiento y análisis de diversos formatos de documentos, sirviendo como una solución integral para el análisis de documentos y la extracción de información. Este sistema avanzado aprovecha la sofisticada visión por computadora y el procesamiento del lenguaje natural para manejar una amplia gama de tipos de documentos con notable precisión. Aquí hay un desglose detallado de sus capacidades de procesamiento de documentos:
- Documentos manuscritos: El sistema sobresale en la interpretación de contenido manuscrito a través de múltiples estilos y formatos. Puede:
- Reconocer con precisión diferentes estilos de escritura a mano, desde cursiva pulcra hasta garabatos apresurados
- Procesar tanto documentos formales como notas informales con alta precisión
- Manejar múltiples idiomas y caracteres especiales en forma manuscrita
- Formularios estructurados: Demuestra una capacidad superior en el procesamiento de documentación estandarizada con:
- Extracción precisa de campos de datos clave de formularios complejos
- Organización automática de la información extraída en formatos estructurados
- Validación de la consistencia de datos a través de múltiples campos del formulario
- Documentación técnica: Muestra comprensión avanzada de materiales técnicos especializados a través de:
- Interpretación detallada de notaciones y símbolos técnicos complejos
- Comprensión de información de escala y dimensiones en dibujos
- Reconocimiento de especificaciones técnicas y terminología estándar de la industria
- Documentos de formato mixto: Demuestra capacidades versátiles de procesamiento mediante:
- Integración perfecta de información de texto, imágenes y elementos gráficos
- Mantenimiento del contexto a través de diferentes tipos de contenido dentro del mismo documento
- Procesamiento de diseños complejos con múltiples jerarquías de información
- Documentos antiguos: Ofrece un manejo sofisticado de materiales históricos mediante:
- Adaptación a varios niveles de degradación y envejecimiento de documentos
- Procesamiento de estilos de formato y tipografía obsoletos
- Mantenimiento del contexto histórico mientras hace el contenido accesible en formatos modernos
Ejemplo:
Este código enviará una imagen de un documento (como una factura o recibo) a GPT-4o y le solicitará identificar el tipo de documento y extraer información específica, como nombre del vendedor, fecha, monto total y elementos detallados.
Descarga una muestra del archivo "sample_invoice.png" https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o en el procesamiento de documentos, un caso de uso clave que implica la comprensión y extracción de información de imágenes de documentos como facturas, recibos, formularios o notas.
- Requisitos previos: Requiere la configuración estándar: bibliotecas
openai,python-dotenv, clave API y un archivo de imagen del documento a procesar (sample_invoice.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64convierte la imagen local del documento al formato requerido para la API. - Diseño del prompt para extracción: El prompt es crucial para el procesamiento de documentos. Solicita explícitamente al modelo:
- Identificar el tipo de documento.
- Extraer una lista predefinida de campos específicos (Vendedor, Fecha, Total, Artículos, etc.). Solicitar "No encontrado" para campos faltantes fomenta una salida estructurada.
- Proporcionar un resumen.
- Incluir el nombre del archivo y la marca de tiempo actual proporciona contexto.
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o. - Envía el mensaje multipartes con el prompt de texto y la imagen del documento codificada en base64.
- Utiliza
detail: "high"para la imagen, lo cual puede ser beneficioso para mejorar la precisión del Reconocimiento Óptico de Caracteres (OCR) y la comprensión del texto dentro de la imagen del documento, aunque utiliza más tokens. - Establece
max_tokenspara acomodar información potencialmente extensa, especialmente líneas de artículos.
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta de texto de GPT-4o, que debe contener el tipo de documento identificado y los campos extraídos según lo solicitado por el prompt. También se muestra el uso de tokens.
- Manejo de errores: Incluye verificaciones para errores de API y problemas del sistema de archivos, con sugerencias específicas para posibles problemas de procesamiento de imágenes.
- Relevancia del caso de uso: Aborda directamente el caso de uso de "Procesamiento de Documentos". Demuestra cómo la visión de GPT-4o puede automatizar tareas como la entrada de datos de facturas/recibos, el resumen de correspondencia o incluso la interpretación de notas manuscritas, agilizando significativamente los flujos de trabajo que involucran el procesamiento de documentos visuales.
Para pruebas, use una imagen clara de un documento. La precisión de la extracción dependerá de la calidad de la imagen, la claridad del diseño del documento y la legibilidad del texto. Recuerde reemplazar "sample_invoice.png" con la ruta a su imagen de documento real.
Detección de Problemas Visuales
La Detección de Problemas Visuales es una capacidad sofisticada de IA que revoluciona la forma en que identificamos y analizamos problemas visuales en activos digitales. Esta tecnología avanzada aprovecha algoritmos de visión por computadora y aprendizaje automático para escanear y evaluar automáticamente elementos visuales, detectando problemas que podrían pasar desapercibidos para los revisores humanos. Examina sistemáticamente varios aspectos del contenido visual, encontrando inconsistencias, errores y problemas de usabilidad en:
- Interfaces de usuario: Detectando elementos mal alineados, diseños rotos, estilos inconsistentes y problemas de accesibilidad. Esta capacidad realiza un análisis integral de elementos de UI, incluyendo:
- Colocación de botones y zonas de interacción para garantizar una experiencia de usuario óptima
- Alineación y validación de campos de formulario para mantener la armonía visual
- Consistencia del menú de navegación a través de diferentes páginas y estados
- Relaciones de contraste de color para cumplimiento WCAG y estándares de accesibilidad
- Espaciado de elementos interactivos y dimensionamiento de puntos de contacto para compatibilidad móvil
- Maquetas de diseño: Identificando problemas de espaciado, problemas de contraste de color y desviaciones de las pautas de diseño. El sistema realiza análisis detallados incluyendo:
- Mediciones de relleno y margen según especificaciones establecidas
- Verificación de consistencia del esquema de color en todos los elementos de diseño
- Verificación de jerarquía tipográfica para legibilidad y consistencia de marca
- Cumplimiento de biblioteca de componentes y adherencia al sistema de diseño
- Evaluación de ritmo visual y balance en diseños
- Diseños visuales: Detectando errores tipográficos, problemas de alineación de cuadrícula y fallos de diseño responsivo. Esto implica un análisis sofisticado de:
- Patrones de uso de fuentes a través de diferentes tipos y secciones de contenido
- Optimización de espaciado de texto y altura de línea para legibilidad
- Cumplimiento del sistema de cuadrícula en varios tamaños de viewport
- Pruebas de comportamiento responsivo en puntos de quiebre estándar
- Consistencia de diseño a través de diferentes dispositivos y orientaciones
Esta capacidad se ha vuelto indispensable para los equipos de control de calidad y diseñadores en el mantenimiento de altos estándares en productos digitales. Al implementar la Detección de Problemas Visuales:
- Los equipos pueden automatizar hasta el 80% de los procesos de control de calidad visual
- La precisión de detección alcanza el 95% para problemas visuales comunes
- Los ciclos de revisión se reducen en un promedio del 60%
La tecnología acelera significativamente el proceso de revisión al marcar automáticamente posibles problemas antes de que lleguen a producción. Este enfoque proactivo no solo reduce la necesidad de inspección manual que consume tiempo, sino que también mejora la calidad general del producto al garantizar estándares visuales consistentes en todos los activos digitales. El resultado son ciclos de desarrollo más rápidos, costos reducidos y entregables de mayor calidad que cumplen tanto con estándares técnicos como estéticos.
Ejemplo:
Este código envía una imagen de una interfaz de usuario (UI) o una captura de pantalla de diseño a GPT-4o y le solicita identificar posibles defectos de diseño, problemas de usabilidad, inconsistencias y otros problemas visuales.
Descarga una muestra del archivo "ui_mockup.png" https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este ejemplo de código muestra la capacidad de GPT-4o para la detección de problemas visuales, particularmente útil en revisiones de diseño UI/UX, control de calidad (QA) e identificación de posibles problemas en diseños visuales o maquetas.
- Requisitos previos: Configuración estándar que involucra
openai,python-dotenv, configuración de la clave API y un archivo de imagen de entrada que representa un diseño UI o maqueta (ui_mockup.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64se utiliza para preparar el archivo de imagen local para la solicitud API. - Diseño del prompt para revisión: El prompt está específicamente estructurado para guiar a GPT-4o a actuar como revisor de UI/UX. Solicita al modelo buscar problemas dentro de categorías definidas comunes en críticas de diseño:
- Diseño y Alineación
- Tipografía
- Color y Contraste (mencionando accesibilidad/WCAG como punto clave)
- Consistencia
- Usabilidad y Claridad
- Principios Generales de Diseño
De manera crucial, pregunta el por qué algo es un problema, solicitando justificación más allá de la simple identificación.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multi-parte que contiene el prompt detallado de revisión y la imagen codificada en base64.
- Utiliza
detail: "high"para la imagen, potencialmente mejorando la capacidad del modelo para percibir detalles visuales sutiles como ligeras desalineaciones o problemas de renderizado de texto. - Establece
max_tokenspara permitir una lista completa de posibles problemas y explicaciones.
- Apunta al modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener una lista estructurada de problemas visuales identificados basados en las categorías del prompt. También se proporciona el uso de tokens.
- Manejo de errores: Incluye verificaciones estándar para errores de API y problemas del sistema de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Detección de Problemas Visuales". Demuestra cómo la IA puede ayudar a diseñadores y desarrolladores al escanear automáticamente interfaces en busca de fallos comunes, potencialmente acelerando el proceso de revisión, detectando problemas temprano y mejorando la calidad general y usabilidad de los productos digitales.
Para pruebas efectivas, use una imagen de UI que incluya fallos de diseño intencional o no intencionalmente. Recuerde reemplazar "ui_mockup.png" con la ruta a su archivo de imagen real.
1.3.3 Casos de Uso Compatibles para Visión en GPT-4o
Las capacidades de visión de GPT-4o van mucho más allá del simple reconocimiento de imágenes, ofreciendo una amplia gama de aplicaciones que pueden transformar la manera en que interactuamos con el contenido visual. Esta sección explora los diversos casos de uso donde se puede aprovechar la comprensión visual de GPT-4o para crear aplicaciones más inteligentes y receptivas.
Desde el análisis de diagramas complejos hasta la provisión de descripciones detalladas de imágenes, las características de visión de GPT-4o permiten a los desarrolladores construir soluciones que cierran la brecha entre la comprensión visual y textual. Estas capacidades pueden ser particularmente valiosas en campos como la educación, la accesibilidad, la moderación de contenido y el análisis automatizado.
Exploremos los casos de uso clave donde brillan las capacidades de visión de GPT-4o, junto con ejemplos prácticos y estrategias de implementación que demuestran su versatilidad en aplicaciones del mundo real.
| Caso de Uso | Ejemplo | Explicación |
| Generación de pies de foto | "Describe esta imagen en detalle." | Convierte contenido visual en descripciones textuales detalladas, útil para catalogación de contenido, accesibilidad e indexación automatizada de imágenes. |
| Análisis de interfaz de usuario | "¿Hay errores visuales en esta captura de pantalla de la página web?" | Examina interfaces de usuario en busca de inconsistencias de diseño, problemas de alineación y de usabilidad, ayudando a agilizar los procesos de control de calidad. |
| Lectura de documentos | "Extrae el número de factura y la fecha de este escaneo." | Procesa documentos escaneados para extraer información específica, automatizando flujos de trabajo de entrada de datos y procesamiento de documentos. |
| Interpretación de visualización de datos | "Resume este gráfico circular en lenguaje sencillo." | Traduce representaciones visuales complejas de datos en descripciones narrativas claras, haciendo los datos más accesibles para todos los usuarios. |
| Preguntas y respuestas educativas | "¿Qué figura geométrica es esta? ¿Cuáles son sus propiedades?" | Proporciona apoyo al aprendizaje interactivo mediante el análisis y explicación de contenido educativo visual, ayudando a los estudiantes a comprender conceptos complejos. |
| Soporte de accesibilidad | "Lee en voz alta el contenido de esta imagen." | Mejora la accesibilidad digital proporcionando descripciones detalladas del contenido visual para usuarios con discapacidades visuales. |
1.3.4 Mejores Prácticas para Prompts de Visión
La creación de prompts efectivos para modelos de IA habilitados para visión requiere un enfoque diferente en comparación con las interacciones solo de texto. Si bien los principios fundamentales de comunicación clara siguen siendo importantes, los prompts visuales necesitan tener en cuenta la naturaleza espacial, contextual y multimodal del análisis de imágenes. Esta sección explora estrategias clave y mejores prácticas para ayudarte a crear prompts basados en visión más efectivos que maximicen las capacidades de comprensión visual de GPT-4o.
Ya sea que estés construyendo aplicaciones para análisis de imágenes, procesamiento de documentos o control de calidad visual, entender estas mejores prácticas te ayudará a:
- Obtener respuestas más precisas y relevantes del modelo
- Reducir la ambigüedad en tus solicitudes
- Estructurar tus prompts para tareas complejas de análisis visual
- Optimizar la interacción entre elementos textuales y visuales
Exploremos los principios fundamentales que te ayudarán a crear prompts más efectivos basados en visión:
Sé directo con tu solicitud:
Ejemplo 1 (Prompt Inefectivo):
"¿Cuáles son las características principales en esta habitación?"
Este prompt tiene varios problemas:
- Es demasiado amplio y poco enfocado
- Carece de criterios específicos sobre qué constituye una "característica principal"
- Puede resultar en respuestas inconsistentes o superficiales
- No guía a la IA hacia ningún aspecto particular de análisis
Ejemplo 2 (Prompt Efectivo):
"Identifica todos los dispositivos electrónicos en esta sala de estar y describe su posición."
Este prompt es superior porque:
- Define claramente qué buscar (dispositivos electrónicos)
- Especifica el alcance (sala de estar)
- Solicita información específica (posición/ubicación)
- Generará información estructurada y procesable
- Facilita verificar si la IA omitió algo
La diferencia clave es que el segundo prompt proporciona parámetros claros para el análisis y un tipo específico de salida, lo que hace mucho más probable recibir información útil y relevante que sirva a tu propósito previsto.
Combina con texto cuando sea necesario
Una imagen por sí sola puede ser suficiente para una descripción básica, pero combinarla con un prompt bien elaborado mejora significativamente las capacidades analíticas del modelo y la precisión de la salida. La clave es proporcionar un contexto claro y específico que guíe la atención del modelo hacia los aspectos más relevantes para tus necesidades.
Por ejemplo, en lugar de solo subir una imagen, añade prompts contextuales detallados como:
- "Analiza este plano arquitectónico enfocándote en posibles riesgos de seguridad, particularmente en áreas de escaleras y salidas"
- "Revisa esta gráfica y explica la tendencia entre 2020-2023, destacando cualquier patrón estacional y anomalía"
- "Examina esta maqueta de interfaz de usuario e identifica problemas de accesibilidad para usuarios con discapacidades visuales"
Este enfoque ofrece varias ventajas:
- Enfoca el análisis del modelo en características o preocupaciones específicas
- Reduce observaciones irrelevantes o superficiales
- Asegura respuestas más consistentes y estructuradas
- Permite un análisis más profundo y matizado de elementos visuales complejos
- Ayuda a generar perspectivas y recomendaciones más procesables
La combinación de entrada visual con guía textual precisa ayuda al modelo a entender exactamente qué aspectos de la imagen son más importantes para tu caso de uso, resultando en respuestas más valiosas y dirigidas.
Utiliza seguimientos estructurados
Después de completar un análisis visual inicial, puedes aprovechar el hilo de conversación para realizar una investigación más exhaustiva mediante preguntas de seguimiento estructuradas. Este enfoque te permite construir sobre las observaciones iniciales del modelo y extraer información más detallada y específica. Las preguntas de seguimiento ayudan a crear un proceso de análisis más interactivo y completo.
Así es como usar efectivamente los seguimientos estructurados:
- Profundizar en detalles específicos
- Ejemplo: "¿Puedes describir las luminarias en más detalle?"
- Esto ayuda a enfocar la atención del modelo en elementos particulares que necesitan un examen más cercano
- Útil para análisis técnico o documentación detallada
- Comparar elementos
- Ejemplo: "¿Cómo se compara la distribución de la habitación A con la habitación B?"
- Permite la comparación sistemática de diferentes componentes o áreas
- Ayuda a identificar patrones, inconsistencias o relaciones
- Obtener recomendaciones
- Ejemplo: "Basado en este plano, ¿qué mejoras sugerirías?"
- Aprovecha la comprensión del modelo para generar perspectivas prácticas
- Puede llevar a retroalimentación procesable para mejoras
Al usar seguimientos estructurados, creas una interacción más dinámica que puede descubrir perspectivas más profundas y una comprensión más matizada del contenido visual que estás analizando.
1.3.5 Entrada de Múltiples Imágenes
Puedes enviar múltiples imágenes en un solo mensaje si tu caso de uso requiere comparación entre imágenes. Esta potente función te permite analizar relaciones entre imágenes, comparar diferentes versiones de diseños o evaluar cambios a lo largo del tiempo. El modelo procesa todas las imágenes simultáneamente, permitiendo un análisis sofisticado de múltiples imágenes que típicamente requeriría varias solicitudes separadas.
Esto es lo que puedes hacer con la entrada de múltiples imágenes:
- Comparar Iteraciones de Diseño
- Analizar cambios de UI/UX entre versiones
- Seguir la progresión de implementaciones de diseño
- Identificar consistencia entre diferentes pantallas
- Análisis de Documentos
- Comparar múltiples versiones de documentos
- Hacer referencias cruzadas de documentación relacionada
- Verificar la autenticidad de documentos
- Análisis Temporal
- Revisar escenarios de antes y después
- Rastrear cambios en datos visuales a lo largo del tiempo
- Monitorear el progreso en proyectos visuales
El modelo procesa estas imágenes contextualmente, comprendiendo sus relaciones y proporcionando un análisis integral. Puede identificar patrones, inconsistencias, mejoras y relaciones entre todas las imágenes proporcionadas, ofreciendo perspectivas detalladas que serían difíciles de obtener mediante el análisis de una sola imagen.
Ejemplo:
Este código envía dos imágenes (por ejemplo, dos versiones de una maqueta de UI) junto con un prompt de texto en una sola llamada a la API, pidiendo al modelo que las compare e identifique diferencias.
Descarga una muestra del archivo "image_path_1.png" https://files.cuantum.tech/images/image_path_1.png
Descarga una muestra del archivo "image_path_2.png" https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Desglose del código:
- Contexto: Este código demuestra la capacidad de entrada múltiple de imágenes de GPT-4o, permitiendo a los usuarios enviar varias imágenes en una sola solicitud de API para tareas como comparación, análisis de relaciones o síntesis de información entre elementos visuales. El ejemplo se centra en comparar dos maquetas de interfaz de usuario para identificar diferencias.
- Requisitos previos: Requiere la configuración estándar (
openai,python-dotenv, clave API) pero específicamente necesita dos archivos de imagen de entrada para la tarea de comparación (ui_mockup_v1.pngyui_mockup_v2.pngusados como marcadores de posición). - Codificación de imágenes: La función
encode_image_to_base64se utiliza dos veces, una vez para cada imagen de entrada. El manejo de errores asegura que ambas imágenes se procesen correctamente antes de continuar. - Estructura de la solicitud API: La diferencia clave está en la lista
messages[0]["content"]. Ahora contiene:- Un diccionario de
type: "text"para el prompt. - Múltiples diccionarios de
type: "image_url", uno para cada imagen que se envía. Las imágenes se incluyen secuencialmente después del prompt de texto.
- Un diccionario de
- Diseño del prompt para tareas multi-imagen: El prompt hace referencia explícita a las dos imágenes (por ejemplo, "la primera imagen", "la segunda imagen", o por nombre de archivo como se hace aquí) y establece claramente la tarea que involucra ambas imágenes (por ejemplo, "Compara la Versión 1 y la Versión 2", "enumera las diferencias").
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o, que admite entradas múltiples de imágenes. - Envía la lista estructurada de
messagesque contiene el prompt de texto y múltiples imágenes codificadas en base64. - Establece
max_tokensapropiado para la salida esperada (una lista de diferencias).
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener los resultados de la comparación basados en el prompt y las dos imágenes proporcionadas. El uso de tokens refleja el procesamiento del texto y todas las imágenes.
- Manejo de errores: Incluye verificaciones estándar, enfatizando posibles problemas con cualquiera de los archivos de imagen.
- Relevancia de casos de uso: Esto aborda directamente la capacidad de "Entrada Multi-Imagen". Es útil para comparación de versiones (diseños, documentos), análisis de secuencias (fotos de antes/después), combinación de información de diferentes fuentes visuales (por ejemplo, fotos de productos + tabla de tallas), o cualquier tarea donde se requiera entender la relación o diferencias entre múltiples imágenes.
Recuerda proporcionar dos archivos de imagen distintos (por ejemplo, dos versiones diferentes de una maqueta de UI) al probar este código, y actualizar las variables image_path_1 y image_path_2 según corresponda.
1.3.6 Privacidad y Seguridad
A medida que los sistemas de IA procesan y analizan cada vez más datos visuales, entender las implicaciones de privacidad y seguridad se vuelve fundamental. Esta sección explora los aspectos críticos de la protección de datos de imagen al trabajar con modelos de IA habilitados para visión, cubriendo todo desde protocolos básicos de seguridad hasta mejores prácticas para el manejo responsable de datos.
Examinaremos las medidas técnicas de seguridad implementadas, las estrategias de gestión de datos y las consideraciones esenciales de privacidad que los desarrolladores deben abordar al construir aplicaciones que procesan imágenes enviadas por usuarios. Entender estos principios es crucial para mantener la confianza del usuario y asegurar el cumplimiento de las regulaciones de protección de datos.
Las áreas clave que cubriremos incluyen:
- Protocolos de seguridad para la transmisión y almacenamiento de datos de imagen
- Mejores prácticas para gestionar contenido visual enviado por usuarios
- Consideraciones de privacidad y requisitos de cumplimiento
- Estrategias de implementación para procesamiento seguro de imágenes
Exploremos en detalle las medidas de seguridad integrales y consideraciones de privacidad que son esenciales para proteger datos visuales:
- Carga segura de imágenes y autenticación API:
- Los datos de imagen están protegidos mediante encriptación avanzada durante el tránsito utilizando protocolos TLS estándar de la industria, asegurando la seguridad de extremo a extremo
- Un sistema robusto de autenticación asegura que el acceso esté estrictamente limitado a solicitudes verificadas con tus credenciales API específicas, previniendo accesos no autorizados
- El sistema implementa aislamiento estricto - las imágenes asociadas con tu clave API permanecen completamente separadas e inaccesibles para otros usuarios o claves API, manteniendo la soberanía de datos
- Estrategias efectivas de gestión de datos de imagen:
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
openai.files.delete(file_id), dándote control completo sobre la retención de datos - Las mejores prácticas incluyen implementar sistemas automatizados de limpieza que eliminen regularmente las cargas temporales de imágenes, reduciendo riesgos de seguridad y sobrecarga de almacenamiento
- Las auditorías sistemáticas regulares de archivos almacenados son cruciales para mantener una organización óptima de datos y cumplimiento de seguridad
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
- Protección integral de privacidad del usuario:
- Implementar mecanismos explícitos de consentimiento del usuario antes de que comience cualquier análisis de imagen, asegurando transparencia y confianza
- Desarrollar e integrar flujos claros de consentimiento dentro de tu aplicación que informen a los usuarios sobre cómo se procesarán sus imágenes
- Crear políticas de privacidad detalladas que explícitamente describan los procedimientos de procesamiento de imágenes, limitaciones de uso y medidas de protección de datos
- Establecer y comunicar claramente políticas específicas de retención de datos, incluyendo cuánto tiempo se almacenan las imágenes y cuándo se eliminan automáticamente
Resumen
En esta sección, has adquirido conocimientos exhaustivos sobre las revolucionarias capacidades de visión de GPT-4o, que transforman fundamentalmente cómo los sistemas de IA procesan y comprenden el contenido visual. Esta característica revolucionaria va mucho más allá del procesamiento tradicional de texto, permitiendo a la IA realizar análisis detallados de imágenes con una comprensión similar a la humana. A través de redes neuronales avanzadas y sofisticados algoritmos de visión por computadora, el sistema puede identificar objetos, interpretar escenas, comprender el contexto e incluso reconocer detalles sutiles dentro de las imágenes. Con una eficiencia y facilidad de implementación notables, puedes aprovechar estas potentes capacidades a través de una API simplificada que procesa simultáneamente tanto imágenes como comandos en lenguaje natural.
Esta tecnología innovadora representa un cambio de paradigma en las aplicaciones de IA, abriendo una amplia gama de implementaciones prácticas en numerosos dominios:
- Educación: Crear experiencias de aprendizaje dinámicas e interactivas con explicaciones visuales y tutoría automatizada basada en imágenes
- Generar ayudas visuales personalizadas para conceptos complejos
- Proporcionar retroalimentación en tiempo real sobre dibujos o diagramas de estudiantes
- Accesibilidad: Desarrollar herramientas sofisticadas que proporcionen descripciones detalladas de imágenes para usuarios con discapacidad visual
- Generar descripciones contextuales de imágenes con detalles relevantes
- Crear narrativas de audio a partir de contenido visual
- Análisis: Realizar análisis sofisticados de datos visuales para inteligencia empresarial e investigación
- Extraer información de gráficos, diagramas y esquemas técnicos
- Analizar tendencias en datos visuales a través de grandes conjuntos de datos
- Automatización: Optimizar flujos de trabajo con procesamiento y categorización automatizada de imágenes
- Clasificar y etiquetar automáticamente contenido visual
- Procesar documentos con contenido mixto de texto e imágenes
A lo largo de esta exploración exhaustiva, has dominado varias capacidades esenciales que forman la base de la implementación de IA visual:
- Cargar e interpretar imágenes: Domina los fundamentos técnicos de integrar la API en tus aplicaciones, incluyendo el formato adecuado de imágenes, procedimientos eficientes de carga y comprensión de los diversos parámetros que afectan la precisión de interpretación. Aprende a recibir y analizar interpretaciones detalladas y contextualizadas que pueden impulsar el procesamiento posterior.
- Usar prompts multimodales con texto + imagen: Desarrolla experiencia en la creación de prompts efectivos que combinen perfectamente instrucciones textuales con entradas visuales. Comprende cómo estructurar consultas que aprovechen ambas modalidades para obtener resultados más precisos y matizados. Aprende técnicas avanzadas de prompting que pueden guiar la atención de la IA hacia aspectos específicos de las imágenes.
- Construir asistentes que ven antes de hablar: Crea aplicaciones sofisticadas de IA que procesan información visual como parte fundamental de su proceso de toma de decisiones. Aprende a desarrollar sistemas que pueden entender el contexto tanto de entradas visuales como textuales, lo que lleva a interacciones más inteligentes, naturales y conscientes del contexto que verdaderamente conectan la brecha entre la comprensión humana y la máquina.
1.3 Capacidades de Visión de GPT-4o
Con el lanzamiento de GPT-4o, OpenAI logró un avance significativo en inteligencia artificial al introducir soporte de visión multimodal nativo. Esta capacidad revolucionaria permite al modelo procesar simultáneamente información visual y textual, permitiéndole interpretar, analizar y razonar sobre imágenes con la misma sofisticación que aplica al procesamiento de texto. La comprensión visual del modelo es integral y versátil, siendo capaz de:
- Análisis Detallado de Imágenes: Convertir contenido visual en descripciones en lenguaje natural, identificando objetos, colores, patrones y relaciones espaciales.
- Interpretación Técnica: Procesar visualizaciones complejas como gráficos, diagramas y esquemas, extrayendo perspectivas y tendencias significativas.
- Procesamiento de Documentos: Leer y comprender varios formatos de documentos, desde notas manuscritas hasta formularios estructurados y dibujos técnicos.
- Detección de Problemas Visuales: Identificar problemas en interfaces de usuario, maquetas de diseño y layouts visuales, haciéndolo valioso para procesos de control de calidad y revisión de diseño.
En esta sección, obtendrás conocimiento práctico sobre la integración de las capacidades visuales de GPT-4o en tus aplicaciones. Cubriremos los aspectos técnicos de enviar imágenes como entrada, explorando tanto la extracción de datos estructurados como enfoques de procesamiento de lenguaje natural. Aprenderás a implementar aplicaciones del mundo real como:
- Sistemas interactivos de preguntas y respuestas visuales que pueden responder preguntas sobre el contenido de imágenes
Soluciones automatizadas de procesamiento de formularios para gestión documental
Sistemas avanzados de reconocimiento de objetos para diversas industrias
Herramientas de accesibilidad que pueden describir imágenes para usuarios con discapacidad visual
1.3.1 ¿Qué es GPT-4o Vision?
GPT-4o ("o" de "omni") representa un salto revolucionario en la tecnología de inteligencia artificial al lograr una integración perfecta de las capacidades de procesamiento de lenguaje y visual en un único modelo unificado. Esta integración es particularmente innovadora porque refleja la capacidad natural del cerebro humano para procesar múltiples tipos de información simultáneamente. Así como los humanos pueden combinar sin esfuerzo señales visuales con información verbal para entender su entorno, GPT-4o puede procesar e interpretar tanto texto como imágenes de manera unificada e inteligente.
La arquitectura técnica de GPT-4o representa una desviación significativa de los modelos tradicionales de IA. Los sistemas anteriores típicamente requerían una cadena compleja de modelos separados - uno para procesamiento de imágenes, otro para análisis de texto, y componentes adicionales para conectar estos sistemas separados. Estos enfoques más antiguos no solo eran computacionalmente intensivos, sino que a menudo resultaban en pérdida de información entre pasos de procesamiento. GPT-4o elimina estas ineficiencias al manejar todo el procesamiento dentro de un sistema único y optimizado. Los usuarios ahora pueden enviar tanto imágenes como texto a través de una simple llamada API, haciendo la tecnología más accesible y fácil de implementar.
Lo que verdaderamente distingue a GPT-4o es su sofisticada arquitectura neural que permite una verdadera comprensión multimodal. En lugar de tratar el texto y las imágenes como entradas separadas que se procesan independientemente, el modelo crea un espacio semántico unificado donde la información visual y textual pueden interactuar e informarse mutuamente.
Esto significa que al analizar un gráfico, por ejemplo, GPT-4o no solo realiza reconocimiento óptico de caracteres o reconocimiento básico de patrones - realmente comprende la relación entre elementos visuales, datos numéricos y contexto textual. Esta integración profunda le permite proporcionar respuestas matizadas y conscientes del contexto que extraen tanto de los elementos visuales como textuales de la entrada, muy similar a como lo haría un experto humano al analizar información compleja.
Requisitos Clave para la Integración de Visión
- Selección del Modelo: GPT-4o debe ser especificado explícitamente como tu elección de modelo. Esto es crucial ya que las versiones anteriores de GPT no soportan capacidades de visión. La designación 'o' indica la versión omni-modal con capacidades de procesamiento visual. Al implementar características de visión, asegurarse de usar GPT-4o es esencial para acceder al rango completo de capacidades de análisis visual y lograr un rendimiento óptimo.
- Proceso de Carga de Imágenes: Tu implementación debe manejar adecuadamente las cargas de archivos de imagen a través del endpoint dedicado de carga de imágenes de OpenAI. Esto implica:
- Convertir la imagen a un formato apropiado: Asegurar que las imágenes estén en formatos soportados (PNG, JPEG) y cumplan con las limitaciones de tamaño. El sistema acepta imágenes de hasta 20MB de tamaño.
- Generar un identificador de archivo seguro: La API crea un identificador único para cada imagen cargada, permitiendo referencias seguras en llamadas API subsecuentes mientras mantiene la privacidad de los datos.
- Gestionar adecuadamente el ciclo de vida del archivo cargado: Implementar procedimientos apropiados de limpieza para eliminar archivos cargados cuando ya no se necesiten, ayudando a mantener la eficiencia y seguridad del sistema.
- Ingeniería de Prompts: Aunque el modelo puede procesar imágenes independientemente, combinarlas con prompts de texto bien elaborados a menudo produce mejores resultados. Puedes:
- Hacer preguntas específicas sobre la imagen: Formular consultas precisas que apunten a la información exacta que necesitas, como "¿De qué color es el auto en primer plano?" o "¿Cuántas personas llevan sombreros?"
- Solicitar tipos particulares de análisis: Especificar el tipo de análisis necesario, ya sea técnico (medición, conteo), descriptivo (colores, formas), o interpretativo (emociones, estilo).
- Guiar la atención del modelo a aspectos o regiones específicas: Dirigir al modelo para que se enfoque en áreas o elementos particulares dentro de la imagen para un análisis más detallado, como "Mira la esquina superior derecha" o "Concéntrate en el texto en el centro."
Ejemplo: Analizar un Gráfico desde una Imagen
Veamos paso a paso cómo enviar una imagen (por ejemplo, un gráfico de barras o captura de pantalla) a GPT-4o y hacerle una pregunta específica.
Ejemplo Paso a Paso en Python
Paso 1: Cargar la Imagen a OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Analicemos este código:
- Declaraciones de Importación
openai: Biblioteca principal para interactuar con la API de OpenAIos: Para manejar variables de entornodotenv: Carga variables de entorno desde un archivo .env
- Configuración del Entorno
- Carga las variables de entorno usando
load_dotenv() - Establece la clave API de OpenAI desde las variables de entorno para la autenticación
- Carga de Imagen
- Crea una nueva carga de archivo usando
openai.files.create() - Abre 'sales_chart.png' en modo de lectura binaria (
'rb') - Especifica el propósito como "vision" para el procesamiento de imágenes
Este código representa el primer paso para utilizar las capacidades de visión de GPT-4o, lo cual es necesario antes de poder analizar imágenes con el modelo. El identificador del archivo de imagen devuelto por esta carga puede usarse posteriormente en llamadas a la API.
Paso 2: Enviar Imagen + Prompt de Texto a GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Analicemos este código:
- Estructura de la Llamada API:
- Utiliza el método ChatCompletion.create() de OpenAI
- Especifica "gpt-4o" como el modelo, lo cual es necesario para las capacidades de visión
- Formato del Mensaje:
- Crea un array de mensajes con un único mensaje de usuario
- El contenido es un array que contiene dos elementos:
- Un elemento de texto con el prompt solicitando el análisis del gráfico
- Un elemento image_url que hace referencia al archivo previamente cargado
- Parámetros:
- Establece max_tokens en 300 para limitar la longitud de la respuesta
- Utiliza el ID del archivo del paso de carga previo
- Manejo de la Salida:
- Imprime "GPT-4o Vision Response:"
- Extrae y muestra la respuesta del modelo desde el array de opciones
Este código demuestra cómo combinar entradas tanto de texto como de imagen en un único prompt, permitiendo que GPT-4o analice contenido visual y proporcione información basada en la pregunta específica realizada.
En este ejemplo, estás enviando tanto un prompt de texto como una imagen en el mismo mensaje. GPT-4o analiza la entrada visual y la combina con tus instrucciones.
1.3.2 Casos de Uso para Visión en GPT-4o
Las capacidades de visión de GPT-4o abren un amplio rango de aplicaciones prácticas a través de varias industrias y casos de uso. Desde mejorar la accesibilidad hasta automatizar tareas complejas de análisis visual, la capacidad del modelo para entender e interpretar imágenes ha transformado cómo interactuamos con datos visuales. Esta sección explora las diversas aplicaciones de las capacidades de visión de GPT-4o, demostrando cómo las organizaciones y desarrolladores pueden aprovechar esta tecnología para resolver problemas del mundo real y crear soluciones innovadoras.
Al examinar casos de uso específicos y ejemplos de implementación, veremos cómo las capacidades de comprensión visual de GPT-4o pueden aplicarse a tareas que van desde la simple descripción de imágenes hasta el análisis técnico complejo. Estas aplicaciones muestran la versatilidad del modelo y su potencial para revolucionar los flujos de trabajo en campos como la salud, educación, diseño y documentación técnica.
Análisis Detallado de Imágenes
La conversión de contenido visual en descripciones en lenguaje natural es una de las capacidades más poderosas y sofisticadas de GPT-4o. El modelo demuestra una notable habilidad en el análisis integral de escenas, descomponiendo metódicamente las imágenes en sus componentes fundamentales con excepcional precisión y detalle. A través del procesamiento neural avanzado, puede realizar múltiples niveles de análisis simultáneamente:
- Identificar objetos individuales y sus características - desde elementos simples como forma y tamaño hasta características complejas como nombres de marca, condiciones y variaciones específicas de objetos
- Describir relaciones espaciales entre elementos - analizando con precisión cómo los objetos están posicionados entre sí, incluyendo percepción de profundidad, superposición y disposiciones jerárquicas en el espacio tridimensional
- Reconocer colores, texturas y patrones con alta precisión - distinguiendo entre variaciones sutiles de tonos, propiedades complejas de materiales y repeticiones o irregularidades intrincadas de patrones
- Detectar detalles visuales sutiles que podrían pasar desapercibidos por sistemas convencionales de visión por computadora - incluyendo sombras, reflejos, oclusiones parciales y efectos ambientales que afectan la apariencia de los objetos
- Comprender relaciones contextuales entre objetos en una escena - interpretando cómo diferentes elementos interactúan entre sí, su probable propósito o función, y el contexto general del entorno
Estas capacidades sofisticadas permiten una amplia gama de aplicaciones prácticas. En la catalogación automatizada de imágenes, el sistema puede crear descripciones detalladas y buscables de grandes bases de datos de imágenes. Para usuarios con discapacidad visual, proporciona descripciones ricas y contextuales que pintan una imagen completa de la escena visual. La versatilidad del modelo se extiende al procesamiento de varios tipos de contenido visual:
- Fotos de productos - descripciones detalladas de características, materiales y elementos de diseño
- Dibujos arquitectónicos - interpretación de detalles técnicos, medidas y relaciones espaciales
- Escenas naturales - análisis exhaustivo de paisajes, condiciones climáticas y características ambientales
- Situaciones sociales - comprensión de interacciones humanas, expresiones y lenguaje corporal
Esta capacidad permite aplicaciones que van desde la catalogación automatizada de imágenes hasta la descripción detallada de escenas para usuarios con discapacidad visual. El modelo puede procesar desde simples fotos de productos hasta complejos dibujos arquitectónicos, proporcionando descripciones ricas y contextuales que capturan elementos visuales tanto obvios como sutiles.
Ejemplo: Sistemas Interactivos de Preguntas y Respuestas Visuales
Este código enviará una imagen (desde un archivo local) y un prompt multi-parte al modelo GPT-4o para mostrar estos diferentes tipos de análisis en una sola respuesta.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para realizar análisis detallados de imágenes, combinando varios casos de uso discutidos: generación de descripciones de accesibilidad, reconocimiento de objetos y respuesta a preguntas contextuales sobre el contenido visual.
- Requisitos previos: Enumera la biblioteca necesaria (
openai,python-dotenv), cómo manejar la clave API de forma segura (usando un archivo.env), y la necesidad de un archivo de imagen de muestra. - Codificación de imagen: Incluye una función auxiliar
encode_image_to_base64para convertir un archivo de imagen local al formato URI de datos base64 requerido por la API cuando no se usa una URL pública directa. También realiza verificaciones básicas del tipo de archivo. - Cliente API: Inicializa el cliente estándar de OpenAI, cargando la clave API desde las variables de entorno. Incluye manejo de errores para claves faltantes o problemas de inicialización.
- Prompt Multi-Modal: El núcleo de la solicitud es la estructura de
messages.- Contiene un único mensaje de usuario.
- El
contentde este mensaje es una lista que contiene múltiples partes:- Una parte de
textque contiene las instrucciones (el prompt que solicita descripción, lista de objetos y contexto). - Una parte de
image_url. Crucialmente, el campourldentro deimage_urlse establece como el URIdata:[media_type];base64,[encoded_string]generado por la función auxiliar. El parámetrodetailpuede ajustarse (low,high,auto) para influir en la profundidad del análisis y el costo de tokens.
- Una parte de
- Llamada a la API (
client.chat.completions.create):- Especifica
model="gpt-4o". - Pasa la lista estructurada de
messages. - Establece
max_tokenspara controlar la longitud de la respuesta.
- Especifica
- Manejo de Respuesta: Extrae el contenido de texto del campo
choices[0].message.contentde la respuesta de la API y lo imprime. También muestra cómo acceder a la información de uso de tokens. - Manejo de Errores: Incluye bloques
try...exceptpara errores de API (OpenAIError) y excepciones generales, proporcionando sugerencias para problemas comunes como marcadores de política de contenido o imágenes inválidas. - Capacidades Demostradas: Esta única llamada a la API muestra efectivamente:
- Accesibilidad: El modelo genera una descripción textual adecuada para lectores de pantalla.
- Reconocimiento de Objetos: Identifica y enumera los objetos presentes en la imagen.
- Preguntas y Respuestas Visuales/Inferencia: Responde preguntas sobre el contexto y posibles actividades basándose en evidencia visual.
Este ejemplo proporciona una demostración práctica y completa de las capacidades de visión de GPT-4o para la comprensión detallada de imágenes en el contexto de tu capítulo del libro. Recuerda reemplazar "sample_scene.jpg" con un archivo de imagen real para realizar pruebas.
Interpretación Técnica y Análisis de Datos
El procesamiento de visualizaciones complejas como gráficos, diagramas y esquemas requiere una comprensión sofisticada para extraer insights y tendencias significativas. El sistema demuestra capacidades notables en la traducción de datos visuales a información procesable.
Esto incluye la capacidad de:
- Analizar datos cuantitativos presentados en varios formatos de gráficos (gráficos de barras, gráficos de líneas, diagramas de dispersión) e identificar patrones clave, valores atípicos y correlaciones. Por ejemplo, puede detectar tendencias estacionales en gráficos de líneas, identificar puntos de datos inusuales en diagramas de dispersión y comparar proporciones en gráficos de barras.
- Interpretar diagramas técnicos complejos como planos arquitectónicos, esquemas de ingeniería e ilustraciones científicas con precisión detallada. Esto incluye la comprensión de dibujos a escala, diagramas de circuitos eléctricos, estructuras moleculares e instrucciones de ensamblaje mecánico.
- Extraer valores numéricos, etiquetas y leyendas de visualizaciones manteniendo la precisión contextual. El sistema puede leer e interpretar etiquetas de ejes, valores de puntos de datos, entradas de leyendas y notas al pie, asegurando que toda la información cuantitativa se capture con precisión.
- Comparar múltiples puntos de datos o tendencias a través de diferentes períodos de tiempo o categorías para proporcionar insights analíticos completos. Esto incluye comparaciones año tras año, análisis entre categorías e identificación de tendencias multivariables.
- Traducir información estadística visual en explicaciones escritas claras que los usuarios no técnicos puedan entender, desglosando relaciones de datos complejas en un lenguaje accesible mientras preserva la precisión de la información subyacente.
Ejemplo:
Este código enviará un archivo de imagen (por ejemplo, un gráfico de barras) y prompts específicos a GPT-4o, solicitándole identificar el tipo de gráfico, comprender los datos presentados y extraer insights o tendencias clave.
Descarga una muestra del archivo "sales_chart.png" https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para la interpretación técnica, específicamente para analizar representaciones visuales de datos como gráficos y diagramas. En lugar de simplemente describir la imagen, el objetivo es extraer insights significativos y comprender los datos presentados.
- Requisitos previos: Requisitos de configuración similares: bibliotecas
openai,python-dotenv, clave API en.env, y lo más importante, un archivo de imagen que contenga un gráfico o diagrama (sales_chart.pngusado como ejemplo). - Codificación de imagen: Utiliza la misma función
encode_image_to_base64para preparar el archivo de imagen local para la API. - Diseño del prompt para interpretación: El prompt está cuidadosamente elaborado para guiar a GPT-4o hacia el análisis en lugar de una simple descripción. Hace preguntas específicas sobre:
- Tipo de gráfico: Identificación básica.
- Representación de datos: Comprensión de ejes, unidades y categorías.
- Insights y tendencias clave: La tarea analítica principal – resumir patrones, máximos/mínimos.
- Puntos de datos específicos: Probando la capacidad de leer valores aproximados del gráfico.
- Resumen general: Un mensaje conciso de conclusiones.
- Información contextual: Incluye la fecha actual y nombre del archivo como referencia dentro del prompt.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multipartes que contiene el prompt analítico de texto y la imagen del gráfico codificada en base64.
- Establece
detailcomo"high"en la parte deimage_url, sugiriendo al modelo que use más recursos para un análisis potencialmente más preciso de los detalles visuales en el gráfico (esto puede aumentar el costo de tokens). - Asigna potencialmente más
max_tokens(por ejemplo, 700) anticipando una respuesta analítica más detallada en comparación con una descripción simple.
- Apunta al modelo
- Manejo de respuesta: Extrae e imprime el análisis textual proporcionado por GPT-4o. Incluye detalles de uso de tokens.
- Manejo de errores: Verificaciones estándar para errores de API y problemas de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Interpretación Técnica" al mostrar cómo GPT-4o puede procesar visualizaciones complejas, extraer puntos de datos, identificar tendencias y proporcionar resúmenes, convirtiendo datos visuales en insights accionables. Esto es valioso para flujos de trabajo de análisis de datos, generación de informes y comprensión de documentos técnicos.
Recuerda usar una imagen clara y de alta resolución de un gráfico o diagrama para obtener mejores resultados al probar este código. Reemplaza "sales_chart.png" con la ruta correcta a tu archivo de imagen.
Procesamiento de Documentos
GPT-4o demuestra capacidades excepcionales en el procesamiento y análisis de diversos formatos de documentos, sirviendo como una solución integral para el análisis de documentos y la extracción de información. Este sistema avanzado aprovecha la sofisticada visión por computadora y el procesamiento del lenguaje natural para manejar una amplia gama de tipos de documentos con notable precisión. Aquí hay un desglose detallado de sus capacidades de procesamiento de documentos:
- Documentos manuscritos: El sistema sobresale en la interpretación de contenido manuscrito a través de múltiples estilos y formatos. Puede:
- Reconocer con precisión diferentes estilos de escritura a mano, desde cursiva pulcra hasta garabatos apresurados
- Procesar tanto documentos formales como notas informales con alta precisión
- Manejar múltiples idiomas y caracteres especiales en forma manuscrita
- Formularios estructurados: Demuestra una capacidad superior en el procesamiento de documentación estandarizada con:
- Extracción precisa de campos de datos clave de formularios complejos
- Organización automática de la información extraída en formatos estructurados
- Validación de la consistencia de datos a través de múltiples campos del formulario
- Documentación técnica: Muestra comprensión avanzada de materiales técnicos especializados a través de:
- Interpretación detallada de notaciones y símbolos técnicos complejos
- Comprensión de información de escala y dimensiones en dibujos
- Reconocimiento de especificaciones técnicas y terminología estándar de la industria
- Documentos de formato mixto: Demuestra capacidades versátiles de procesamiento mediante:
- Integración perfecta de información de texto, imágenes y elementos gráficos
- Mantenimiento del contexto a través de diferentes tipos de contenido dentro del mismo documento
- Procesamiento de diseños complejos con múltiples jerarquías de información
- Documentos antiguos: Ofrece un manejo sofisticado de materiales históricos mediante:
- Adaptación a varios niveles de degradación y envejecimiento de documentos
- Procesamiento de estilos de formato y tipografía obsoletos
- Mantenimiento del contexto histórico mientras hace el contenido accesible en formatos modernos
Ejemplo:
Este código enviará una imagen de un documento (como una factura o recibo) a GPT-4o y le solicitará identificar el tipo de documento y extraer información específica, como nombre del vendedor, fecha, monto total y elementos detallados.
Descarga una muestra del archivo "sample_invoice.png" https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o en el procesamiento de documentos, un caso de uso clave que implica la comprensión y extracción de información de imágenes de documentos como facturas, recibos, formularios o notas.
- Requisitos previos: Requiere la configuración estándar: bibliotecas
openai,python-dotenv, clave API y un archivo de imagen del documento a procesar (sample_invoice.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64convierte la imagen local del documento al formato requerido para la API. - Diseño del prompt para extracción: El prompt es crucial para el procesamiento de documentos. Solicita explícitamente al modelo:
- Identificar el tipo de documento.
- Extraer una lista predefinida de campos específicos (Vendedor, Fecha, Total, Artículos, etc.). Solicitar "No encontrado" para campos faltantes fomenta una salida estructurada.
- Proporcionar un resumen.
- Incluir el nombre del archivo y la marca de tiempo actual proporciona contexto.
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o. - Envía el mensaje multipartes con el prompt de texto y la imagen del documento codificada en base64.
- Utiliza
detail: "high"para la imagen, lo cual puede ser beneficioso para mejorar la precisión del Reconocimiento Óptico de Caracteres (OCR) y la comprensión del texto dentro de la imagen del documento, aunque utiliza más tokens. - Establece
max_tokenspara acomodar información potencialmente extensa, especialmente líneas de artículos.
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta de texto de GPT-4o, que debe contener el tipo de documento identificado y los campos extraídos según lo solicitado por el prompt. También se muestra el uso de tokens.
- Manejo de errores: Incluye verificaciones para errores de API y problemas del sistema de archivos, con sugerencias específicas para posibles problemas de procesamiento de imágenes.
- Relevancia del caso de uso: Aborda directamente el caso de uso de "Procesamiento de Documentos". Demuestra cómo la visión de GPT-4o puede automatizar tareas como la entrada de datos de facturas/recibos, el resumen de correspondencia o incluso la interpretación de notas manuscritas, agilizando significativamente los flujos de trabajo que involucran el procesamiento de documentos visuales.
Para pruebas, use una imagen clara de un documento. La precisión de la extracción dependerá de la calidad de la imagen, la claridad del diseño del documento y la legibilidad del texto. Recuerde reemplazar "sample_invoice.png" con la ruta a su imagen de documento real.
Detección de Problemas Visuales
La Detección de Problemas Visuales es una capacidad sofisticada de IA que revoluciona la forma en que identificamos y analizamos problemas visuales en activos digitales. Esta tecnología avanzada aprovecha algoritmos de visión por computadora y aprendizaje automático para escanear y evaluar automáticamente elementos visuales, detectando problemas que podrían pasar desapercibidos para los revisores humanos. Examina sistemáticamente varios aspectos del contenido visual, encontrando inconsistencias, errores y problemas de usabilidad en:
- Interfaces de usuario: Detectando elementos mal alineados, diseños rotos, estilos inconsistentes y problemas de accesibilidad. Esta capacidad realiza un análisis integral de elementos de UI, incluyendo:
- Colocación de botones y zonas de interacción para garantizar una experiencia de usuario óptima
- Alineación y validación de campos de formulario para mantener la armonía visual
- Consistencia del menú de navegación a través de diferentes páginas y estados
- Relaciones de contraste de color para cumplimiento WCAG y estándares de accesibilidad
- Espaciado de elementos interactivos y dimensionamiento de puntos de contacto para compatibilidad móvil
- Maquetas de diseño: Identificando problemas de espaciado, problemas de contraste de color y desviaciones de las pautas de diseño. El sistema realiza análisis detallados incluyendo:
- Mediciones de relleno y margen según especificaciones establecidas
- Verificación de consistencia del esquema de color en todos los elementos de diseño
- Verificación de jerarquía tipográfica para legibilidad y consistencia de marca
- Cumplimiento de biblioteca de componentes y adherencia al sistema de diseño
- Evaluación de ritmo visual y balance en diseños
- Diseños visuales: Detectando errores tipográficos, problemas de alineación de cuadrícula y fallos de diseño responsivo. Esto implica un análisis sofisticado de:
- Patrones de uso de fuentes a través de diferentes tipos y secciones de contenido
- Optimización de espaciado de texto y altura de línea para legibilidad
- Cumplimiento del sistema de cuadrícula en varios tamaños de viewport
- Pruebas de comportamiento responsivo en puntos de quiebre estándar
- Consistencia de diseño a través de diferentes dispositivos y orientaciones
Esta capacidad se ha vuelto indispensable para los equipos de control de calidad y diseñadores en el mantenimiento de altos estándares en productos digitales. Al implementar la Detección de Problemas Visuales:
- Los equipos pueden automatizar hasta el 80% de los procesos de control de calidad visual
- La precisión de detección alcanza el 95% para problemas visuales comunes
- Los ciclos de revisión se reducen en un promedio del 60%
La tecnología acelera significativamente el proceso de revisión al marcar automáticamente posibles problemas antes de que lleguen a producción. Este enfoque proactivo no solo reduce la necesidad de inspección manual que consume tiempo, sino que también mejora la calidad general del producto al garantizar estándares visuales consistentes en todos los activos digitales. El resultado son ciclos de desarrollo más rápidos, costos reducidos y entregables de mayor calidad que cumplen tanto con estándares técnicos como estéticos.
Ejemplo:
Este código envía una imagen de una interfaz de usuario (UI) o una captura de pantalla de diseño a GPT-4o y le solicita identificar posibles defectos de diseño, problemas de usabilidad, inconsistencias y otros problemas visuales.
Descarga una muestra del archivo "ui_mockup.png" https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este ejemplo de código muestra la capacidad de GPT-4o para la detección de problemas visuales, particularmente útil en revisiones de diseño UI/UX, control de calidad (QA) e identificación de posibles problemas en diseños visuales o maquetas.
- Requisitos previos: Configuración estándar que involucra
openai,python-dotenv, configuración de la clave API y un archivo de imagen de entrada que representa un diseño UI o maqueta (ui_mockup.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64se utiliza para preparar el archivo de imagen local para la solicitud API. - Diseño del prompt para revisión: El prompt está específicamente estructurado para guiar a GPT-4o a actuar como revisor de UI/UX. Solicita al modelo buscar problemas dentro de categorías definidas comunes en críticas de diseño:
- Diseño y Alineación
- Tipografía
- Color y Contraste (mencionando accesibilidad/WCAG como punto clave)
- Consistencia
- Usabilidad y Claridad
- Principios Generales de Diseño
De manera crucial, pregunta el por qué algo es un problema, solicitando justificación más allá de la simple identificación.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multi-parte que contiene el prompt detallado de revisión y la imagen codificada en base64.
- Utiliza
detail: "high"para la imagen, potencialmente mejorando la capacidad del modelo para percibir detalles visuales sutiles como ligeras desalineaciones o problemas de renderizado de texto. - Establece
max_tokenspara permitir una lista completa de posibles problemas y explicaciones.
- Apunta al modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener una lista estructurada de problemas visuales identificados basados en las categorías del prompt. También se proporciona el uso de tokens.
- Manejo de errores: Incluye verificaciones estándar para errores de API y problemas del sistema de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Detección de Problemas Visuales". Demuestra cómo la IA puede ayudar a diseñadores y desarrolladores al escanear automáticamente interfaces en busca de fallos comunes, potencialmente acelerando el proceso de revisión, detectando problemas temprano y mejorando la calidad general y usabilidad de los productos digitales.
Para pruebas efectivas, use una imagen de UI que incluya fallos de diseño intencional o no intencionalmente. Recuerde reemplazar "ui_mockup.png" con la ruta a su archivo de imagen real.
1.3.3 Casos de Uso Compatibles para Visión en GPT-4o
Las capacidades de visión de GPT-4o van mucho más allá del simple reconocimiento de imágenes, ofreciendo una amplia gama de aplicaciones que pueden transformar la manera en que interactuamos con el contenido visual. Esta sección explora los diversos casos de uso donde se puede aprovechar la comprensión visual de GPT-4o para crear aplicaciones más inteligentes y receptivas.
Desde el análisis de diagramas complejos hasta la provisión de descripciones detalladas de imágenes, las características de visión de GPT-4o permiten a los desarrolladores construir soluciones que cierran la brecha entre la comprensión visual y textual. Estas capacidades pueden ser particularmente valiosas en campos como la educación, la accesibilidad, la moderación de contenido y el análisis automatizado.
Exploremos los casos de uso clave donde brillan las capacidades de visión de GPT-4o, junto con ejemplos prácticos y estrategias de implementación que demuestran su versatilidad en aplicaciones del mundo real.
| Caso de Uso | Ejemplo | Explicación |
| Generación de pies de foto | "Describe esta imagen en detalle." | Convierte contenido visual en descripciones textuales detalladas, útil para catalogación de contenido, accesibilidad e indexación automatizada de imágenes. |
| Análisis de interfaz de usuario | "¿Hay errores visuales en esta captura de pantalla de la página web?" | Examina interfaces de usuario en busca de inconsistencias de diseño, problemas de alineación y de usabilidad, ayudando a agilizar los procesos de control de calidad. |
| Lectura de documentos | "Extrae el número de factura y la fecha de este escaneo." | Procesa documentos escaneados para extraer información específica, automatizando flujos de trabajo de entrada de datos y procesamiento de documentos. |
| Interpretación de visualización de datos | "Resume este gráfico circular en lenguaje sencillo." | Traduce representaciones visuales complejas de datos en descripciones narrativas claras, haciendo los datos más accesibles para todos los usuarios. |
| Preguntas y respuestas educativas | "¿Qué figura geométrica es esta? ¿Cuáles son sus propiedades?" | Proporciona apoyo al aprendizaje interactivo mediante el análisis y explicación de contenido educativo visual, ayudando a los estudiantes a comprender conceptos complejos. |
| Soporte de accesibilidad | "Lee en voz alta el contenido de esta imagen." | Mejora la accesibilidad digital proporcionando descripciones detalladas del contenido visual para usuarios con discapacidades visuales. |
1.3.4 Mejores Prácticas para Prompts de Visión
La creación de prompts efectivos para modelos de IA habilitados para visión requiere un enfoque diferente en comparación con las interacciones solo de texto. Si bien los principios fundamentales de comunicación clara siguen siendo importantes, los prompts visuales necesitan tener en cuenta la naturaleza espacial, contextual y multimodal del análisis de imágenes. Esta sección explora estrategias clave y mejores prácticas para ayudarte a crear prompts basados en visión más efectivos que maximicen las capacidades de comprensión visual de GPT-4o.
Ya sea que estés construyendo aplicaciones para análisis de imágenes, procesamiento de documentos o control de calidad visual, entender estas mejores prácticas te ayudará a:
- Obtener respuestas más precisas y relevantes del modelo
- Reducir la ambigüedad en tus solicitudes
- Estructurar tus prompts para tareas complejas de análisis visual
- Optimizar la interacción entre elementos textuales y visuales
Exploremos los principios fundamentales que te ayudarán a crear prompts más efectivos basados en visión:
Sé directo con tu solicitud:
Ejemplo 1 (Prompt Inefectivo):
"¿Cuáles son las características principales en esta habitación?"
Este prompt tiene varios problemas:
- Es demasiado amplio y poco enfocado
- Carece de criterios específicos sobre qué constituye una "característica principal"
- Puede resultar en respuestas inconsistentes o superficiales
- No guía a la IA hacia ningún aspecto particular de análisis
Ejemplo 2 (Prompt Efectivo):
"Identifica todos los dispositivos electrónicos en esta sala de estar y describe su posición."
Este prompt es superior porque:
- Define claramente qué buscar (dispositivos electrónicos)
- Especifica el alcance (sala de estar)
- Solicita información específica (posición/ubicación)
- Generará información estructurada y procesable
- Facilita verificar si la IA omitió algo
La diferencia clave es que el segundo prompt proporciona parámetros claros para el análisis y un tipo específico de salida, lo que hace mucho más probable recibir información útil y relevante que sirva a tu propósito previsto.
Combina con texto cuando sea necesario
Una imagen por sí sola puede ser suficiente para una descripción básica, pero combinarla con un prompt bien elaborado mejora significativamente las capacidades analíticas del modelo y la precisión de la salida. La clave es proporcionar un contexto claro y específico que guíe la atención del modelo hacia los aspectos más relevantes para tus necesidades.
Por ejemplo, en lugar de solo subir una imagen, añade prompts contextuales detallados como:
- "Analiza este plano arquitectónico enfocándote en posibles riesgos de seguridad, particularmente en áreas de escaleras y salidas"
- "Revisa esta gráfica y explica la tendencia entre 2020-2023, destacando cualquier patrón estacional y anomalía"
- "Examina esta maqueta de interfaz de usuario e identifica problemas de accesibilidad para usuarios con discapacidades visuales"
Este enfoque ofrece varias ventajas:
- Enfoca el análisis del modelo en características o preocupaciones específicas
- Reduce observaciones irrelevantes o superficiales
- Asegura respuestas más consistentes y estructuradas
- Permite un análisis más profundo y matizado de elementos visuales complejos
- Ayuda a generar perspectivas y recomendaciones más procesables
La combinación de entrada visual con guía textual precisa ayuda al modelo a entender exactamente qué aspectos de la imagen son más importantes para tu caso de uso, resultando en respuestas más valiosas y dirigidas.
Utiliza seguimientos estructurados
Después de completar un análisis visual inicial, puedes aprovechar el hilo de conversación para realizar una investigación más exhaustiva mediante preguntas de seguimiento estructuradas. Este enfoque te permite construir sobre las observaciones iniciales del modelo y extraer información más detallada y específica. Las preguntas de seguimiento ayudan a crear un proceso de análisis más interactivo y completo.
Así es como usar efectivamente los seguimientos estructurados:
- Profundizar en detalles específicos
- Ejemplo: "¿Puedes describir las luminarias en más detalle?"
- Esto ayuda a enfocar la atención del modelo en elementos particulares que necesitan un examen más cercano
- Útil para análisis técnico o documentación detallada
- Comparar elementos
- Ejemplo: "¿Cómo se compara la distribución de la habitación A con la habitación B?"
- Permite la comparación sistemática de diferentes componentes o áreas
- Ayuda a identificar patrones, inconsistencias o relaciones
- Obtener recomendaciones
- Ejemplo: "Basado en este plano, ¿qué mejoras sugerirías?"
- Aprovecha la comprensión del modelo para generar perspectivas prácticas
- Puede llevar a retroalimentación procesable para mejoras
Al usar seguimientos estructurados, creas una interacción más dinámica que puede descubrir perspectivas más profundas y una comprensión más matizada del contenido visual que estás analizando.
1.3.5 Entrada de Múltiples Imágenes
Puedes enviar múltiples imágenes en un solo mensaje si tu caso de uso requiere comparación entre imágenes. Esta potente función te permite analizar relaciones entre imágenes, comparar diferentes versiones de diseños o evaluar cambios a lo largo del tiempo. El modelo procesa todas las imágenes simultáneamente, permitiendo un análisis sofisticado de múltiples imágenes que típicamente requeriría varias solicitudes separadas.
Esto es lo que puedes hacer con la entrada de múltiples imágenes:
- Comparar Iteraciones de Diseño
- Analizar cambios de UI/UX entre versiones
- Seguir la progresión de implementaciones de diseño
- Identificar consistencia entre diferentes pantallas
- Análisis de Documentos
- Comparar múltiples versiones de documentos
- Hacer referencias cruzadas de documentación relacionada
- Verificar la autenticidad de documentos
- Análisis Temporal
- Revisar escenarios de antes y después
- Rastrear cambios en datos visuales a lo largo del tiempo
- Monitorear el progreso en proyectos visuales
El modelo procesa estas imágenes contextualmente, comprendiendo sus relaciones y proporcionando un análisis integral. Puede identificar patrones, inconsistencias, mejoras y relaciones entre todas las imágenes proporcionadas, ofreciendo perspectivas detalladas que serían difíciles de obtener mediante el análisis de una sola imagen.
Ejemplo:
Este código envía dos imágenes (por ejemplo, dos versiones de una maqueta de UI) junto con un prompt de texto en una sola llamada a la API, pidiendo al modelo que las compare e identifique diferencias.
Descarga una muestra del archivo "image_path_1.png" https://files.cuantum.tech/images/image_path_1.png
Descarga una muestra del archivo "image_path_2.png" https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Desglose del código:
- Contexto: Este código demuestra la capacidad de entrada múltiple de imágenes de GPT-4o, permitiendo a los usuarios enviar varias imágenes en una sola solicitud de API para tareas como comparación, análisis de relaciones o síntesis de información entre elementos visuales. El ejemplo se centra en comparar dos maquetas de interfaz de usuario para identificar diferencias.
- Requisitos previos: Requiere la configuración estándar (
openai,python-dotenv, clave API) pero específicamente necesita dos archivos de imagen de entrada para la tarea de comparación (ui_mockup_v1.pngyui_mockup_v2.pngusados como marcadores de posición). - Codificación de imágenes: La función
encode_image_to_base64se utiliza dos veces, una vez para cada imagen de entrada. El manejo de errores asegura que ambas imágenes se procesen correctamente antes de continuar. - Estructura de la solicitud API: La diferencia clave está en la lista
messages[0]["content"]. Ahora contiene:- Un diccionario de
type: "text"para el prompt. - Múltiples diccionarios de
type: "image_url", uno para cada imagen que se envía. Las imágenes se incluyen secuencialmente después del prompt de texto.
- Un diccionario de
- Diseño del prompt para tareas multi-imagen: El prompt hace referencia explícita a las dos imágenes (por ejemplo, "la primera imagen", "la segunda imagen", o por nombre de archivo como se hace aquí) y establece claramente la tarea que involucra ambas imágenes (por ejemplo, "Compara la Versión 1 y la Versión 2", "enumera las diferencias").
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o, que admite entradas múltiples de imágenes. - Envía la lista estructurada de
messagesque contiene el prompt de texto y múltiples imágenes codificadas en base64. - Establece
max_tokensapropiado para la salida esperada (una lista de diferencias).
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener los resultados de la comparación basados en el prompt y las dos imágenes proporcionadas. El uso de tokens refleja el procesamiento del texto y todas las imágenes.
- Manejo de errores: Incluye verificaciones estándar, enfatizando posibles problemas con cualquiera de los archivos de imagen.
- Relevancia de casos de uso: Esto aborda directamente la capacidad de "Entrada Multi-Imagen". Es útil para comparación de versiones (diseños, documentos), análisis de secuencias (fotos de antes/después), combinación de información de diferentes fuentes visuales (por ejemplo, fotos de productos + tabla de tallas), o cualquier tarea donde se requiera entender la relación o diferencias entre múltiples imágenes.
Recuerda proporcionar dos archivos de imagen distintos (por ejemplo, dos versiones diferentes de una maqueta de UI) al probar este código, y actualizar las variables image_path_1 y image_path_2 según corresponda.
1.3.6 Privacidad y Seguridad
A medida que los sistemas de IA procesan y analizan cada vez más datos visuales, entender las implicaciones de privacidad y seguridad se vuelve fundamental. Esta sección explora los aspectos críticos de la protección de datos de imagen al trabajar con modelos de IA habilitados para visión, cubriendo todo desde protocolos básicos de seguridad hasta mejores prácticas para el manejo responsable de datos.
Examinaremos las medidas técnicas de seguridad implementadas, las estrategias de gestión de datos y las consideraciones esenciales de privacidad que los desarrolladores deben abordar al construir aplicaciones que procesan imágenes enviadas por usuarios. Entender estos principios es crucial para mantener la confianza del usuario y asegurar el cumplimiento de las regulaciones de protección de datos.
Las áreas clave que cubriremos incluyen:
- Protocolos de seguridad para la transmisión y almacenamiento de datos de imagen
- Mejores prácticas para gestionar contenido visual enviado por usuarios
- Consideraciones de privacidad y requisitos de cumplimiento
- Estrategias de implementación para procesamiento seguro de imágenes
Exploremos en detalle las medidas de seguridad integrales y consideraciones de privacidad que son esenciales para proteger datos visuales:
- Carga segura de imágenes y autenticación API:
- Los datos de imagen están protegidos mediante encriptación avanzada durante el tránsito utilizando protocolos TLS estándar de la industria, asegurando la seguridad de extremo a extremo
- Un sistema robusto de autenticación asegura que el acceso esté estrictamente limitado a solicitudes verificadas con tus credenciales API específicas, previniendo accesos no autorizados
- El sistema implementa aislamiento estricto - las imágenes asociadas con tu clave API permanecen completamente separadas e inaccesibles para otros usuarios o claves API, manteniendo la soberanía de datos
- Estrategias efectivas de gestión de datos de imagen:
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
openai.files.delete(file_id), dándote control completo sobre la retención de datos - Las mejores prácticas incluyen implementar sistemas automatizados de limpieza que eliminen regularmente las cargas temporales de imágenes, reduciendo riesgos de seguridad y sobrecarga de almacenamiento
- Las auditorías sistemáticas regulares de archivos almacenados son cruciales para mantener una organización óptima de datos y cumplimiento de seguridad
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
- Protección integral de privacidad del usuario:
- Implementar mecanismos explícitos de consentimiento del usuario antes de que comience cualquier análisis de imagen, asegurando transparencia y confianza
- Desarrollar e integrar flujos claros de consentimiento dentro de tu aplicación que informen a los usuarios sobre cómo se procesarán sus imágenes
- Crear políticas de privacidad detalladas que explícitamente describan los procedimientos de procesamiento de imágenes, limitaciones de uso y medidas de protección de datos
- Establecer y comunicar claramente políticas específicas de retención de datos, incluyendo cuánto tiempo se almacenan las imágenes y cuándo se eliminan automáticamente
Resumen
En esta sección, has adquirido conocimientos exhaustivos sobre las revolucionarias capacidades de visión de GPT-4o, que transforman fundamentalmente cómo los sistemas de IA procesan y comprenden el contenido visual. Esta característica revolucionaria va mucho más allá del procesamiento tradicional de texto, permitiendo a la IA realizar análisis detallados de imágenes con una comprensión similar a la humana. A través de redes neuronales avanzadas y sofisticados algoritmos de visión por computadora, el sistema puede identificar objetos, interpretar escenas, comprender el contexto e incluso reconocer detalles sutiles dentro de las imágenes. Con una eficiencia y facilidad de implementación notables, puedes aprovechar estas potentes capacidades a través de una API simplificada que procesa simultáneamente tanto imágenes como comandos en lenguaje natural.
Esta tecnología innovadora representa un cambio de paradigma en las aplicaciones de IA, abriendo una amplia gama de implementaciones prácticas en numerosos dominios:
- Educación: Crear experiencias de aprendizaje dinámicas e interactivas con explicaciones visuales y tutoría automatizada basada en imágenes
- Generar ayudas visuales personalizadas para conceptos complejos
- Proporcionar retroalimentación en tiempo real sobre dibujos o diagramas de estudiantes
- Accesibilidad: Desarrollar herramientas sofisticadas que proporcionen descripciones detalladas de imágenes para usuarios con discapacidad visual
- Generar descripciones contextuales de imágenes con detalles relevantes
- Crear narrativas de audio a partir de contenido visual
- Análisis: Realizar análisis sofisticados de datos visuales para inteligencia empresarial e investigación
- Extraer información de gráficos, diagramas y esquemas técnicos
- Analizar tendencias en datos visuales a través de grandes conjuntos de datos
- Automatización: Optimizar flujos de trabajo con procesamiento y categorización automatizada de imágenes
- Clasificar y etiquetar automáticamente contenido visual
- Procesar documentos con contenido mixto de texto e imágenes
A lo largo de esta exploración exhaustiva, has dominado varias capacidades esenciales que forman la base de la implementación de IA visual:
- Cargar e interpretar imágenes: Domina los fundamentos técnicos de integrar la API en tus aplicaciones, incluyendo el formato adecuado de imágenes, procedimientos eficientes de carga y comprensión de los diversos parámetros que afectan la precisión de interpretación. Aprende a recibir y analizar interpretaciones detalladas y contextualizadas que pueden impulsar el procesamiento posterior.
- Usar prompts multimodales con texto + imagen: Desarrolla experiencia en la creación de prompts efectivos que combinen perfectamente instrucciones textuales con entradas visuales. Comprende cómo estructurar consultas que aprovechen ambas modalidades para obtener resultados más precisos y matizados. Aprende técnicas avanzadas de prompting que pueden guiar la atención de la IA hacia aspectos específicos de las imágenes.
- Construir asistentes que ven antes de hablar: Crea aplicaciones sofisticadas de IA que procesan información visual como parte fundamental de su proceso de toma de decisiones. Aprende a desarrollar sistemas que pueden entender el contexto tanto de entradas visuales como textuales, lo que lleva a interacciones más inteligentes, naturales y conscientes del contexto que verdaderamente conectan la brecha entre la comprensión humana y la máquina.
1.3 Capacidades de Visión de GPT-4o
Con el lanzamiento de GPT-4o, OpenAI logró un avance significativo en inteligencia artificial al introducir soporte de visión multimodal nativo. Esta capacidad revolucionaria permite al modelo procesar simultáneamente información visual y textual, permitiéndole interpretar, analizar y razonar sobre imágenes con la misma sofisticación que aplica al procesamiento de texto. La comprensión visual del modelo es integral y versátil, siendo capaz de:
- Análisis Detallado de Imágenes: Convertir contenido visual en descripciones en lenguaje natural, identificando objetos, colores, patrones y relaciones espaciales.
- Interpretación Técnica: Procesar visualizaciones complejas como gráficos, diagramas y esquemas, extrayendo perspectivas y tendencias significativas.
- Procesamiento de Documentos: Leer y comprender varios formatos de documentos, desde notas manuscritas hasta formularios estructurados y dibujos técnicos.
- Detección de Problemas Visuales: Identificar problemas en interfaces de usuario, maquetas de diseño y layouts visuales, haciéndolo valioso para procesos de control de calidad y revisión de diseño.
En esta sección, obtendrás conocimiento práctico sobre la integración de las capacidades visuales de GPT-4o en tus aplicaciones. Cubriremos los aspectos técnicos de enviar imágenes como entrada, explorando tanto la extracción de datos estructurados como enfoques de procesamiento de lenguaje natural. Aprenderás a implementar aplicaciones del mundo real como:
- Sistemas interactivos de preguntas y respuestas visuales que pueden responder preguntas sobre el contenido de imágenes
Soluciones automatizadas de procesamiento de formularios para gestión documental
Sistemas avanzados de reconocimiento de objetos para diversas industrias
Herramientas de accesibilidad que pueden describir imágenes para usuarios con discapacidad visual
1.3.1 ¿Qué es GPT-4o Vision?
GPT-4o ("o" de "omni") representa un salto revolucionario en la tecnología de inteligencia artificial al lograr una integración perfecta de las capacidades de procesamiento de lenguaje y visual en un único modelo unificado. Esta integración es particularmente innovadora porque refleja la capacidad natural del cerebro humano para procesar múltiples tipos de información simultáneamente. Así como los humanos pueden combinar sin esfuerzo señales visuales con información verbal para entender su entorno, GPT-4o puede procesar e interpretar tanto texto como imágenes de manera unificada e inteligente.
La arquitectura técnica de GPT-4o representa una desviación significativa de los modelos tradicionales de IA. Los sistemas anteriores típicamente requerían una cadena compleja de modelos separados - uno para procesamiento de imágenes, otro para análisis de texto, y componentes adicionales para conectar estos sistemas separados. Estos enfoques más antiguos no solo eran computacionalmente intensivos, sino que a menudo resultaban en pérdida de información entre pasos de procesamiento. GPT-4o elimina estas ineficiencias al manejar todo el procesamiento dentro de un sistema único y optimizado. Los usuarios ahora pueden enviar tanto imágenes como texto a través de una simple llamada API, haciendo la tecnología más accesible y fácil de implementar.
Lo que verdaderamente distingue a GPT-4o es su sofisticada arquitectura neural que permite una verdadera comprensión multimodal. En lugar de tratar el texto y las imágenes como entradas separadas que se procesan independientemente, el modelo crea un espacio semántico unificado donde la información visual y textual pueden interactuar e informarse mutuamente.
Esto significa que al analizar un gráfico, por ejemplo, GPT-4o no solo realiza reconocimiento óptico de caracteres o reconocimiento básico de patrones - realmente comprende la relación entre elementos visuales, datos numéricos y contexto textual. Esta integración profunda le permite proporcionar respuestas matizadas y conscientes del contexto que extraen tanto de los elementos visuales como textuales de la entrada, muy similar a como lo haría un experto humano al analizar información compleja.
Requisitos Clave para la Integración de Visión
- Selección del Modelo: GPT-4o debe ser especificado explícitamente como tu elección de modelo. Esto es crucial ya que las versiones anteriores de GPT no soportan capacidades de visión. La designación 'o' indica la versión omni-modal con capacidades de procesamiento visual. Al implementar características de visión, asegurarse de usar GPT-4o es esencial para acceder al rango completo de capacidades de análisis visual y lograr un rendimiento óptimo.
- Proceso de Carga de Imágenes: Tu implementación debe manejar adecuadamente las cargas de archivos de imagen a través del endpoint dedicado de carga de imágenes de OpenAI. Esto implica:
- Convertir la imagen a un formato apropiado: Asegurar que las imágenes estén en formatos soportados (PNG, JPEG) y cumplan con las limitaciones de tamaño. El sistema acepta imágenes de hasta 20MB de tamaño.
- Generar un identificador de archivo seguro: La API crea un identificador único para cada imagen cargada, permitiendo referencias seguras en llamadas API subsecuentes mientras mantiene la privacidad de los datos.
- Gestionar adecuadamente el ciclo de vida del archivo cargado: Implementar procedimientos apropiados de limpieza para eliminar archivos cargados cuando ya no se necesiten, ayudando a mantener la eficiencia y seguridad del sistema.
- Ingeniería de Prompts: Aunque el modelo puede procesar imágenes independientemente, combinarlas con prompts de texto bien elaborados a menudo produce mejores resultados. Puedes:
- Hacer preguntas específicas sobre la imagen: Formular consultas precisas que apunten a la información exacta que necesitas, como "¿De qué color es el auto en primer plano?" o "¿Cuántas personas llevan sombreros?"
- Solicitar tipos particulares de análisis: Especificar el tipo de análisis necesario, ya sea técnico (medición, conteo), descriptivo (colores, formas), o interpretativo (emociones, estilo).
- Guiar la atención del modelo a aspectos o regiones específicas: Dirigir al modelo para que se enfoque en áreas o elementos particulares dentro de la imagen para un análisis más detallado, como "Mira la esquina superior derecha" o "Concéntrate en el texto en el centro."
Ejemplo: Analizar un Gráfico desde una Imagen
Veamos paso a paso cómo enviar una imagen (por ejemplo, un gráfico de barras o captura de pantalla) a GPT-4o y hacerle una pregunta específica.
Ejemplo Paso a Paso en Python
Paso 1: Cargar la Imagen a OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Analicemos este código:
- Declaraciones de Importación
openai: Biblioteca principal para interactuar con la API de OpenAIos: Para manejar variables de entornodotenv: Carga variables de entorno desde un archivo .env
- Configuración del Entorno
- Carga las variables de entorno usando
load_dotenv() - Establece la clave API de OpenAI desde las variables de entorno para la autenticación
- Carga de Imagen
- Crea una nueva carga de archivo usando
openai.files.create() - Abre 'sales_chart.png' en modo de lectura binaria (
'rb') - Especifica el propósito como "vision" para el procesamiento de imágenes
Este código representa el primer paso para utilizar las capacidades de visión de GPT-4o, lo cual es necesario antes de poder analizar imágenes con el modelo. El identificador del archivo de imagen devuelto por esta carga puede usarse posteriormente en llamadas a la API.
Paso 2: Enviar Imagen + Prompt de Texto a GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Analicemos este código:
- Estructura de la Llamada API:
- Utiliza el método ChatCompletion.create() de OpenAI
- Especifica "gpt-4o" como el modelo, lo cual es necesario para las capacidades de visión
- Formato del Mensaje:
- Crea un array de mensajes con un único mensaje de usuario
- El contenido es un array que contiene dos elementos:
- Un elemento de texto con el prompt solicitando el análisis del gráfico
- Un elemento image_url que hace referencia al archivo previamente cargado
- Parámetros:
- Establece max_tokens en 300 para limitar la longitud de la respuesta
- Utiliza el ID del archivo del paso de carga previo
- Manejo de la Salida:
- Imprime "GPT-4o Vision Response:"
- Extrae y muestra la respuesta del modelo desde el array de opciones
Este código demuestra cómo combinar entradas tanto de texto como de imagen en un único prompt, permitiendo que GPT-4o analice contenido visual y proporcione información basada en la pregunta específica realizada.
En este ejemplo, estás enviando tanto un prompt de texto como una imagen en el mismo mensaje. GPT-4o analiza la entrada visual y la combina con tus instrucciones.
1.3.2 Casos de Uso para Visión en GPT-4o
Las capacidades de visión de GPT-4o abren un amplio rango de aplicaciones prácticas a través de varias industrias y casos de uso. Desde mejorar la accesibilidad hasta automatizar tareas complejas de análisis visual, la capacidad del modelo para entender e interpretar imágenes ha transformado cómo interactuamos con datos visuales. Esta sección explora las diversas aplicaciones de las capacidades de visión de GPT-4o, demostrando cómo las organizaciones y desarrolladores pueden aprovechar esta tecnología para resolver problemas del mundo real y crear soluciones innovadoras.
Al examinar casos de uso específicos y ejemplos de implementación, veremos cómo las capacidades de comprensión visual de GPT-4o pueden aplicarse a tareas que van desde la simple descripción de imágenes hasta el análisis técnico complejo. Estas aplicaciones muestran la versatilidad del modelo y su potencial para revolucionar los flujos de trabajo en campos como la salud, educación, diseño y documentación técnica.
Análisis Detallado de Imágenes
La conversión de contenido visual en descripciones en lenguaje natural es una de las capacidades más poderosas y sofisticadas de GPT-4o. El modelo demuestra una notable habilidad en el análisis integral de escenas, descomponiendo metódicamente las imágenes en sus componentes fundamentales con excepcional precisión y detalle. A través del procesamiento neural avanzado, puede realizar múltiples niveles de análisis simultáneamente:
- Identificar objetos individuales y sus características - desde elementos simples como forma y tamaño hasta características complejas como nombres de marca, condiciones y variaciones específicas de objetos
- Describir relaciones espaciales entre elementos - analizando con precisión cómo los objetos están posicionados entre sí, incluyendo percepción de profundidad, superposición y disposiciones jerárquicas en el espacio tridimensional
- Reconocer colores, texturas y patrones con alta precisión - distinguiendo entre variaciones sutiles de tonos, propiedades complejas de materiales y repeticiones o irregularidades intrincadas de patrones
- Detectar detalles visuales sutiles que podrían pasar desapercibidos por sistemas convencionales de visión por computadora - incluyendo sombras, reflejos, oclusiones parciales y efectos ambientales que afectan la apariencia de los objetos
- Comprender relaciones contextuales entre objetos en una escena - interpretando cómo diferentes elementos interactúan entre sí, su probable propósito o función, y el contexto general del entorno
Estas capacidades sofisticadas permiten una amplia gama de aplicaciones prácticas. En la catalogación automatizada de imágenes, el sistema puede crear descripciones detalladas y buscables de grandes bases de datos de imágenes. Para usuarios con discapacidad visual, proporciona descripciones ricas y contextuales que pintan una imagen completa de la escena visual. La versatilidad del modelo se extiende al procesamiento de varios tipos de contenido visual:
- Fotos de productos - descripciones detalladas de características, materiales y elementos de diseño
- Dibujos arquitectónicos - interpretación de detalles técnicos, medidas y relaciones espaciales
- Escenas naturales - análisis exhaustivo de paisajes, condiciones climáticas y características ambientales
- Situaciones sociales - comprensión de interacciones humanas, expresiones y lenguaje corporal
Esta capacidad permite aplicaciones que van desde la catalogación automatizada de imágenes hasta la descripción detallada de escenas para usuarios con discapacidad visual. El modelo puede procesar desde simples fotos de productos hasta complejos dibujos arquitectónicos, proporcionando descripciones ricas y contextuales que capturan elementos visuales tanto obvios como sutiles.
Ejemplo: Sistemas Interactivos de Preguntas y Respuestas Visuales
Este código enviará una imagen (desde un archivo local) y un prompt multi-parte al modelo GPT-4o para mostrar estos diferentes tipos de análisis en una sola respuesta.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para realizar análisis detallados de imágenes, combinando varios casos de uso discutidos: generación de descripciones de accesibilidad, reconocimiento de objetos y respuesta a preguntas contextuales sobre el contenido visual.
- Requisitos previos: Enumera la biblioteca necesaria (
openai,python-dotenv), cómo manejar la clave API de forma segura (usando un archivo.env), y la necesidad de un archivo de imagen de muestra. - Codificación de imagen: Incluye una función auxiliar
encode_image_to_base64para convertir un archivo de imagen local al formato URI de datos base64 requerido por la API cuando no se usa una URL pública directa. También realiza verificaciones básicas del tipo de archivo. - Cliente API: Inicializa el cliente estándar de OpenAI, cargando la clave API desde las variables de entorno. Incluye manejo de errores para claves faltantes o problemas de inicialización.
- Prompt Multi-Modal: El núcleo de la solicitud es la estructura de
messages.- Contiene un único mensaje de usuario.
- El
contentde este mensaje es una lista que contiene múltiples partes:- Una parte de
textque contiene las instrucciones (el prompt que solicita descripción, lista de objetos y contexto). - Una parte de
image_url. Crucialmente, el campourldentro deimage_urlse establece como el URIdata:[media_type];base64,[encoded_string]generado por la función auxiliar. El parámetrodetailpuede ajustarse (low,high,auto) para influir en la profundidad del análisis y el costo de tokens.
- Una parte de
- Llamada a la API (
client.chat.completions.create):- Especifica
model="gpt-4o". - Pasa la lista estructurada de
messages. - Establece
max_tokenspara controlar la longitud de la respuesta.
- Especifica
- Manejo de Respuesta: Extrae el contenido de texto del campo
choices[0].message.contentde la respuesta de la API y lo imprime. También muestra cómo acceder a la información de uso de tokens. - Manejo de Errores: Incluye bloques
try...exceptpara errores de API (OpenAIError) y excepciones generales, proporcionando sugerencias para problemas comunes como marcadores de política de contenido o imágenes inválidas. - Capacidades Demostradas: Esta única llamada a la API muestra efectivamente:
- Accesibilidad: El modelo genera una descripción textual adecuada para lectores de pantalla.
- Reconocimiento de Objetos: Identifica y enumera los objetos presentes en la imagen.
- Preguntas y Respuestas Visuales/Inferencia: Responde preguntas sobre el contexto y posibles actividades basándose en evidencia visual.
Este ejemplo proporciona una demostración práctica y completa de las capacidades de visión de GPT-4o para la comprensión detallada de imágenes en el contexto de tu capítulo del libro. Recuerda reemplazar "sample_scene.jpg" con un archivo de imagen real para realizar pruebas.
Interpretación Técnica y Análisis de Datos
El procesamiento de visualizaciones complejas como gráficos, diagramas y esquemas requiere una comprensión sofisticada para extraer insights y tendencias significativas. El sistema demuestra capacidades notables en la traducción de datos visuales a información procesable.
Esto incluye la capacidad de:
- Analizar datos cuantitativos presentados en varios formatos de gráficos (gráficos de barras, gráficos de líneas, diagramas de dispersión) e identificar patrones clave, valores atípicos y correlaciones. Por ejemplo, puede detectar tendencias estacionales en gráficos de líneas, identificar puntos de datos inusuales en diagramas de dispersión y comparar proporciones en gráficos de barras.
- Interpretar diagramas técnicos complejos como planos arquitectónicos, esquemas de ingeniería e ilustraciones científicas con precisión detallada. Esto incluye la comprensión de dibujos a escala, diagramas de circuitos eléctricos, estructuras moleculares e instrucciones de ensamblaje mecánico.
- Extraer valores numéricos, etiquetas y leyendas de visualizaciones manteniendo la precisión contextual. El sistema puede leer e interpretar etiquetas de ejes, valores de puntos de datos, entradas de leyendas y notas al pie, asegurando que toda la información cuantitativa se capture con precisión.
- Comparar múltiples puntos de datos o tendencias a través de diferentes períodos de tiempo o categorías para proporcionar insights analíticos completos. Esto incluye comparaciones año tras año, análisis entre categorías e identificación de tendencias multivariables.
- Traducir información estadística visual en explicaciones escritas claras que los usuarios no técnicos puedan entender, desglosando relaciones de datos complejas en un lenguaje accesible mientras preserva la precisión de la información subyacente.
Ejemplo:
Este código enviará un archivo de imagen (por ejemplo, un gráfico de barras) y prompts específicos a GPT-4o, solicitándole identificar el tipo de gráfico, comprender los datos presentados y extraer insights o tendencias clave.
Descarga una muestra del archivo "sales_chart.png" https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o para la interpretación técnica, específicamente para analizar representaciones visuales de datos como gráficos y diagramas. En lugar de simplemente describir la imagen, el objetivo es extraer insights significativos y comprender los datos presentados.
- Requisitos previos: Requisitos de configuración similares: bibliotecas
openai,python-dotenv, clave API en.env, y lo más importante, un archivo de imagen que contenga un gráfico o diagrama (sales_chart.pngusado como ejemplo). - Codificación de imagen: Utiliza la misma función
encode_image_to_base64para preparar el archivo de imagen local para la API. - Diseño del prompt para interpretación: El prompt está cuidadosamente elaborado para guiar a GPT-4o hacia el análisis en lugar de una simple descripción. Hace preguntas específicas sobre:
- Tipo de gráfico: Identificación básica.
- Representación de datos: Comprensión de ejes, unidades y categorías.
- Insights y tendencias clave: La tarea analítica principal – resumir patrones, máximos/mínimos.
- Puntos de datos específicos: Probando la capacidad de leer valores aproximados del gráfico.
- Resumen general: Un mensaje conciso de conclusiones.
- Información contextual: Incluye la fecha actual y nombre del archivo como referencia dentro del prompt.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multipartes que contiene el prompt analítico de texto y la imagen del gráfico codificada en base64.
- Establece
detailcomo"high"en la parte deimage_url, sugiriendo al modelo que use más recursos para un análisis potencialmente más preciso de los detalles visuales en el gráfico (esto puede aumentar el costo de tokens). - Asigna potencialmente más
max_tokens(por ejemplo, 700) anticipando una respuesta analítica más detallada en comparación con una descripción simple.
- Apunta al modelo
- Manejo de respuesta: Extrae e imprime el análisis textual proporcionado por GPT-4o. Incluye detalles de uso de tokens.
- Manejo de errores: Verificaciones estándar para errores de API y problemas de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Interpretación Técnica" al mostrar cómo GPT-4o puede procesar visualizaciones complejas, extraer puntos de datos, identificar tendencias y proporcionar resúmenes, convirtiendo datos visuales en insights accionables. Esto es valioso para flujos de trabajo de análisis de datos, generación de informes y comprensión de documentos técnicos.
Recuerda usar una imagen clara y de alta resolución de un gráfico o diagrama para obtener mejores resultados al probar este código. Reemplaza "sales_chart.png" con la ruta correcta a tu archivo de imagen.
Procesamiento de Documentos
GPT-4o demuestra capacidades excepcionales en el procesamiento y análisis de diversos formatos de documentos, sirviendo como una solución integral para el análisis de documentos y la extracción de información. Este sistema avanzado aprovecha la sofisticada visión por computadora y el procesamiento del lenguaje natural para manejar una amplia gama de tipos de documentos con notable precisión. Aquí hay un desglose detallado de sus capacidades de procesamiento de documentos:
- Documentos manuscritos: El sistema sobresale en la interpretación de contenido manuscrito a través de múltiples estilos y formatos. Puede:
- Reconocer con precisión diferentes estilos de escritura a mano, desde cursiva pulcra hasta garabatos apresurados
- Procesar tanto documentos formales como notas informales con alta precisión
- Manejar múltiples idiomas y caracteres especiales en forma manuscrita
- Formularios estructurados: Demuestra una capacidad superior en el procesamiento de documentación estandarizada con:
- Extracción precisa de campos de datos clave de formularios complejos
- Organización automática de la información extraída en formatos estructurados
- Validación de la consistencia de datos a través de múltiples campos del formulario
- Documentación técnica: Muestra comprensión avanzada de materiales técnicos especializados a través de:
- Interpretación detallada de notaciones y símbolos técnicos complejos
- Comprensión de información de escala y dimensiones en dibujos
- Reconocimiento de especificaciones técnicas y terminología estándar de la industria
- Documentos de formato mixto: Demuestra capacidades versátiles de procesamiento mediante:
- Integración perfecta de información de texto, imágenes y elementos gráficos
- Mantenimiento del contexto a través de diferentes tipos de contenido dentro del mismo documento
- Procesamiento de diseños complejos con múltiples jerarquías de información
- Documentos antiguos: Ofrece un manejo sofisticado de materiales históricos mediante:
- Adaptación a varios niveles de degradación y envejecimiento de documentos
- Procesamiento de estilos de formato y tipografía obsoletos
- Mantenimiento del contexto histórico mientras hace el contenido accesible en formatos modernos
Ejemplo:
Este código enviará una imagen de un documento (como una factura o recibo) a GPT-4o y le solicitará identificar el tipo de documento y extraer información específica, como nombre del vendedor, fecha, monto total y elementos detallados.
Descarga una muestra del archivo "sample_invoice.png" https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este código demuestra la capacidad de GPT-4o en el procesamiento de documentos, un caso de uso clave que implica la comprensión y extracción de información de imágenes de documentos como facturas, recibos, formularios o notas.
- Requisitos previos: Requiere la configuración estándar: bibliotecas
openai,python-dotenv, clave API y un archivo de imagen del documento a procesar (sample_invoice.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64convierte la imagen local del documento al formato requerido para la API. - Diseño del prompt para extracción: El prompt es crucial para el procesamiento de documentos. Solicita explícitamente al modelo:
- Identificar el tipo de documento.
- Extraer una lista predefinida de campos específicos (Vendedor, Fecha, Total, Artículos, etc.). Solicitar "No encontrado" para campos faltantes fomenta una salida estructurada.
- Proporcionar un resumen.
- Incluir el nombre del archivo y la marca de tiempo actual proporciona contexto.
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o. - Envía el mensaje multipartes con el prompt de texto y la imagen del documento codificada en base64.
- Utiliza
detail: "high"para la imagen, lo cual puede ser beneficioso para mejorar la precisión del Reconocimiento Óptico de Caracteres (OCR) y la comprensión del texto dentro de la imagen del documento, aunque utiliza más tokens. - Establece
max_tokenspara acomodar información potencialmente extensa, especialmente líneas de artículos.
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta de texto de GPT-4o, que debe contener el tipo de documento identificado y los campos extraídos según lo solicitado por el prompt. También se muestra el uso de tokens.
- Manejo de errores: Incluye verificaciones para errores de API y problemas del sistema de archivos, con sugerencias específicas para posibles problemas de procesamiento de imágenes.
- Relevancia del caso de uso: Aborda directamente el caso de uso de "Procesamiento de Documentos". Demuestra cómo la visión de GPT-4o puede automatizar tareas como la entrada de datos de facturas/recibos, el resumen de correspondencia o incluso la interpretación de notas manuscritas, agilizando significativamente los flujos de trabajo que involucran el procesamiento de documentos visuales.
Para pruebas, use una imagen clara de un documento. La precisión de la extracción dependerá de la calidad de la imagen, la claridad del diseño del documento y la legibilidad del texto. Recuerde reemplazar "sample_invoice.png" con la ruta a su imagen de documento real.
Detección de Problemas Visuales
La Detección de Problemas Visuales es una capacidad sofisticada de IA que revoluciona la forma en que identificamos y analizamos problemas visuales en activos digitales. Esta tecnología avanzada aprovecha algoritmos de visión por computadora y aprendizaje automático para escanear y evaluar automáticamente elementos visuales, detectando problemas que podrían pasar desapercibidos para los revisores humanos. Examina sistemáticamente varios aspectos del contenido visual, encontrando inconsistencias, errores y problemas de usabilidad en:
- Interfaces de usuario: Detectando elementos mal alineados, diseños rotos, estilos inconsistentes y problemas de accesibilidad. Esta capacidad realiza un análisis integral de elementos de UI, incluyendo:
- Colocación de botones y zonas de interacción para garantizar una experiencia de usuario óptima
- Alineación y validación de campos de formulario para mantener la armonía visual
- Consistencia del menú de navegación a través de diferentes páginas y estados
- Relaciones de contraste de color para cumplimiento WCAG y estándares de accesibilidad
- Espaciado de elementos interactivos y dimensionamiento de puntos de contacto para compatibilidad móvil
- Maquetas de diseño: Identificando problemas de espaciado, problemas de contraste de color y desviaciones de las pautas de diseño. El sistema realiza análisis detallados incluyendo:
- Mediciones de relleno y margen según especificaciones establecidas
- Verificación de consistencia del esquema de color en todos los elementos de diseño
- Verificación de jerarquía tipográfica para legibilidad y consistencia de marca
- Cumplimiento de biblioteca de componentes y adherencia al sistema de diseño
- Evaluación de ritmo visual y balance en diseños
- Diseños visuales: Detectando errores tipográficos, problemas de alineación de cuadrícula y fallos de diseño responsivo. Esto implica un análisis sofisticado de:
- Patrones de uso de fuentes a través de diferentes tipos y secciones de contenido
- Optimización de espaciado de texto y altura de línea para legibilidad
- Cumplimiento del sistema de cuadrícula en varios tamaños de viewport
- Pruebas de comportamiento responsivo en puntos de quiebre estándar
- Consistencia de diseño a través de diferentes dispositivos y orientaciones
Esta capacidad se ha vuelto indispensable para los equipos de control de calidad y diseñadores en el mantenimiento de altos estándares en productos digitales. Al implementar la Detección de Problemas Visuales:
- Los equipos pueden automatizar hasta el 80% de los procesos de control de calidad visual
- La precisión de detección alcanza el 95% para problemas visuales comunes
- Los ciclos de revisión se reducen en un promedio del 60%
La tecnología acelera significativamente el proceso de revisión al marcar automáticamente posibles problemas antes de que lleguen a producción. Este enfoque proactivo no solo reduce la necesidad de inspección manual que consume tiempo, sino que también mejora la calidad general del producto al garantizar estándares visuales consistentes en todos los activos digitales. El resultado son ciclos de desarrollo más rápidos, costos reducidos y entregables de mayor calidad que cumplen tanto con estándares técnicos como estéticos.
Ejemplo:
Este código envía una imagen de una interfaz de usuario (UI) o una captura de pantalla de diseño a GPT-4o y le solicita identificar posibles defectos de diseño, problemas de usabilidad, inconsistencias y otros problemas visuales.
Descarga una muestra del archivo "ui_mockup.png" https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Desglose del código:
- Contexto: Este ejemplo de código muestra la capacidad de GPT-4o para la detección de problemas visuales, particularmente útil en revisiones de diseño UI/UX, control de calidad (QA) e identificación de posibles problemas en diseños visuales o maquetas.
- Requisitos previos: Configuración estándar que involucra
openai,python-dotenv, configuración de la clave API y un archivo de imagen de entrada que representa un diseño UI o maqueta (ui_mockup.pngcomo marcador de posición). - Codificación de imagen: La función
encode_image_to_base64se utiliza para preparar el archivo de imagen local para la solicitud API. - Diseño del prompt para revisión: El prompt está específicamente estructurado para guiar a GPT-4o a actuar como revisor de UI/UX. Solicita al modelo buscar problemas dentro de categorías definidas comunes en críticas de diseño:
- Diseño y Alineación
- Tipografía
- Color y Contraste (mencionando accesibilidad/WCAG como punto clave)
- Consistencia
- Usabilidad y Claridad
- Principios Generales de Diseño
De manera crucial, pregunta el por qué algo es un problema, solicitando justificación más allá de la simple identificación.
- Llamada a la API (
client.chat.completions.create):- Apunta al modelo
gpt-4o. - Envía el mensaje multi-parte que contiene el prompt detallado de revisión y la imagen codificada en base64.
- Utiliza
detail: "high"para la imagen, potencialmente mejorando la capacidad del modelo para percibir detalles visuales sutiles como ligeras desalineaciones o problemas de renderizado de texto. - Establece
max_tokenspara permitir una lista completa de posibles problemas y explicaciones.
- Apunta al modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener una lista estructurada de problemas visuales identificados basados en las categorías del prompt. También se proporciona el uso de tokens.
- Manejo de errores: Incluye verificaciones estándar para errores de API y problemas del sistema de archivos.
- Relevancia del caso de uso: Esto aborda directamente el caso de uso de "Detección de Problemas Visuales". Demuestra cómo la IA puede ayudar a diseñadores y desarrolladores al escanear automáticamente interfaces en busca de fallos comunes, potencialmente acelerando el proceso de revisión, detectando problemas temprano y mejorando la calidad general y usabilidad de los productos digitales.
Para pruebas efectivas, use una imagen de UI que incluya fallos de diseño intencional o no intencionalmente. Recuerde reemplazar "ui_mockup.png" con la ruta a su archivo de imagen real.
1.3.3 Casos de Uso Compatibles para Visión en GPT-4o
Las capacidades de visión de GPT-4o van mucho más allá del simple reconocimiento de imágenes, ofreciendo una amplia gama de aplicaciones que pueden transformar la manera en que interactuamos con el contenido visual. Esta sección explora los diversos casos de uso donde se puede aprovechar la comprensión visual de GPT-4o para crear aplicaciones más inteligentes y receptivas.
Desde el análisis de diagramas complejos hasta la provisión de descripciones detalladas de imágenes, las características de visión de GPT-4o permiten a los desarrolladores construir soluciones que cierran la brecha entre la comprensión visual y textual. Estas capacidades pueden ser particularmente valiosas en campos como la educación, la accesibilidad, la moderación de contenido y el análisis automatizado.
Exploremos los casos de uso clave donde brillan las capacidades de visión de GPT-4o, junto con ejemplos prácticos y estrategias de implementación que demuestran su versatilidad en aplicaciones del mundo real.
| Caso de Uso | Ejemplo | Explicación |
| Generación de pies de foto | "Describe esta imagen en detalle." | Convierte contenido visual en descripciones textuales detalladas, útil para catalogación de contenido, accesibilidad e indexación automatizada de imágenes. |
| Análisis de interfaz de usuario | "¿Hay errores visuales en esta captura de pantalla de la página web?" | Examina interfaces de usuario en busca de inconsistencias de diseño, problemas de alineación y de usabilidad, ayudando a agilizar los procesos de control de calidad. |
| Lectura de documentos | "Extrae el número de factura y la fecha de este escaneo." | Procesa documentos escaneados para extraer información específica, automatizando flujos de trabajo de entrada de datos y procesamiento de documentos. |
| Interpretación de visualización de datos | "Resume este gráfico circular en lenguaje sencillo." | Traduce representaciones visuales complejas de datos en descripciones narrativas claras, haciendo los datos más accesibles para todos los usuarios. |
| Preguntas y respuestas educativas | "¿Qué figura geométrica es esta? ¿Cuáles son sus propiedades?" | Proporciona apoyo al aprendizaje interactivo mediante el análisis y explicación de contenido educativo visual, ayudando a los estudiantes a comprender conceptos complejos. |
| Soporte de accesibilidad | "Lee en voz alta el contenido de esta imagen." | Mejora la accesibilidad digital proporcionando descripciones detalladas del contenido visual para usuarios con discapacidades visuales. |
1.3.4 Mejores Prácticas para Prompts de Visión
La creación de prompts efectivos para modelos de IA habilitados para visión requiere un enfoque diferente en comparación con las interacciones solo de texto. Si bien los principios fundamentales de comunicación clara siguen siendo importantes, los prompts visuales necesitan tener en cuenta la naturaleza espacial, contextual y multimodal del análisis de imágenes. Esta sección explora estrategias clave y mejores prácticas para ayudarte a crear prompts basados en visión más efectivos que maximicen las capacidades de comprensión visual de GPT-4o.
Ya sea que estés construyendo aplicaciones para análisis de imágenes, procesamiento de documentos o control de calidad visual, entender estas mejores prácticas te ayudará a:
- Obtener respuestas más precisas y relevantes del modelo
- Reducir la ambigüedad en tus solicitudes
- Estructurar tus prompts para tareas complejas de análisis visual
- Optimizar la interacción entre elementos textuales y visuales
Exploremos los principios fundamentales que te ayudarán a crear prompts más efectivos basados en visión:
Sé directo con tu solicitud:
Ejemplo 1 (Prompt Inefectivo):
"¿Cuáles son las características principales en esta habitación?"
Este prompt tiene varios problemas:
- Es demasiado amplio y poco enfocado
- Carece de criterios específicos sobre qué constituye una "característica principal"
- Puede resultar en respuestas inconsistentes o superficiales
- No guía a la IA hacia ningún aspecto particular de análisis
Ejemplo 2 (Prompt Efectivo):
"Identifica todos los dispositivos electrónicos en esta sala de estar y describe su posición."
Este prompt es superior porque:
- Define claramente qué buscar (dispositivos electrónicos)
- Especifica el alcance (sala de estar)
- Solicita información específica (posición/ubicación)
- Generará información estructurada y procesable
- Facilita verificar si la IA omitió algo
La diferencia clave es que el segundo prompt proporciona parámetros claros para el análisis y un tipo específico de salida, lo que hace mucho más probable recibir información útil y relevante que sirva a tu propósito previsto.
Combina con texto cuando sea necesario
Una imagen por sí sola puede ser suficiente para una descripción básica, pero combinarla con un prompt bien elaborado mejora significativamente las capacidades analíticas del modelo y la precisión de la salida. La clave es proporcionar un contexto claro y específico que guíe la atención del modelo hacia los aspectos más relevantes para tus necesidades.
Por ejemplo, en lugar de solo subir una imagen, añade prompts contextuales detallados como:
- "Analiza este plano arquitectónico enfocándote en posibles riesgos de seguridad, particularmente en áreas de escaleras y salidas"
- "Revisa esta gráfica y explica la tendencia entre 2020-2023, destacando cualquier patrón estacional y anomalía"
- "Examina esta maqueta de interfaz de usuario e identifica problemas de accesibilidad para usuarios con discapacidades visuales"
Este enfoque ofrece varias ventajas:
- Enfoca el análisis del modelo en características o preocupaciones específicas
- Reduce observaciones irrelevantes o superficiales
- Asegura respuestas más consistentes y estructuradas
- Permite un análisis más profundo y matizado de elementos visuales complejos
- Ayuda a generar perspectivas y recomendaciones más procesables
La combinación de entrada visual con guía textual precisa ayuda al modelo a entender exactamente qué aspectos de la imagen son más importantes para tu caso de uso, resultando en respuestas más valiosas y dirigidas.
Utiliza seguimientos estructurados
Después de completar un análisis visual inicial, puedes aprovechar el hilo de conversación para realizar una investigación más exhaustiva mediante preguntas de seguimiento estructuradas. Este enfoque te permite construir sobre las observaciones iniciales del modelo y extraer información más detallada y específica. Las preguntas de seguimiento ayudan a crear un proceso de análisis más interactivo y completo.
Así es como usar efectivamente los seguimientos estructurados:
- Profundizar en detalles específicos
- Ejemplo: "¿Puedes describir las luminarias en más detalle?"
- Esto ayuda a enfocar la atención del modelo en elementos particulares que necesitan un examen más cercano
- Útil para análisis técnico o documentación detallada
- Comparar elementos
- Ejemplo: "¿Cómo se compara la distribución de la habitación A con la habitación B?"
- Permite la comparación sistemática de diferentes componentes o áreas
- Ayuda a identificar patrones, inconsistencias o relaciones
- Obtener recomendaciones
- Ejemplo: "Basado en este plano, ¿qué mejoras sugerirías?"
- Aprovecha la comprensión del modelo para generar perspectivas prácticas
- Puede llevar a retroalimentación procesable para mejoras
Al usar seguimientos estructurados, creas una interacción más dinámica que puede descubrir perspectivas más profundas y una comprensión más matizada del contenido visual que estás analizando.
1.3.5 Entrada de Múltiples Imágenes
Puedes enviar múltiples imágenes en un solo mensaje si tu caso de uso requiere comparación entre imágenes. Esta potente función te permite analizar relaciones entre imágenes, comparar diferentes versiones de diseños o evaluar cambios a lo largo del tiempo. El modelo procesa todas las imágenes simultáneamente, permitiendo un análisis sofisticado de múltiples imágenes que típicamente requeriría varias solicitudes separadas.
Esto es lo que puedes hacer con la entrada de múltiples imágenes:
- Comparar Iteraciones de Diseño
- Analizar cambios de UI/UX entre versiones
- Seguir la progresión de implementaciones de diseño
- Identificar consistencia entre diferentes pantallas
- Análisis de Documentos
- Comparar múltiples versiones de documentos
- Hacer referencias cruzadas de documentación relacionada
- Verificar la autenticidad de documentos
- Análisis Temporal
- Revisar escenarios de antes y después
- Rastrear cambios en datos visuales a lo largo del tiempo
- Monitorear el progreso en proyectos visuales
El modelo procesa estas imágenes contextualmente, comprendiendo sus relaciones y proporcionando un análisis integral. Puede identificar patrones, inconsistencias, mejoras y relaciones entre todas las imágenes proporcionadas, ofreciendo perspectivas detalladas que serían difíciles de obtener mediante el análisis de una sola imagen.
Ejemplo:
Este código envía dos imágenes (por ejemplo, dos versiones de una maqueta de UI) junto con un prompt de texto en una sola llamada a la API, pidiendo al modelo que las compare e identifique diferencias.
Descarga una muestra del archivo "image_path_1.png" https://files.cuantum.tech/images/image_path_1.png
Descarga una muestra del archivo "image_path_2.png" https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Desglose del código:
- Contexto: Este código demuestra la capacidad de entrada múltiple de imágenes de GPT-4o, permitiendo a los usuarios enviar varias imágenes en una sola solicitud de API para tareas como comparación, análisis de relaciones o síntesis de información entre elementos visuales. El ejemplo se centra en comparar dos maquetas de interfaz de usuario para identificar diferencias.
- Requisitos previos: Requiere la configuración estándar (
openai,python-dotenv, clave API) pero específicamente necesita dos archivos de imagen de entrada para la tarea de comparación (ui_mockup_v1.pngyui_mockup_v2.pngusados como marcadores de posición). - Codificación de imágenes: La función
encode_image_to_base64se utiliza dos veces, una vez para cada imagen de entrada. El manejo de errores asegura que ambas imágenes se procesen correctamente antes de continuar. - Estructura de la solicitud API: La diferencia clave está en la lista
messages[0]["content"]. Ahora contiene:- Un diccionario de
type: "text"para el prompt. - Múltiples diccionarios de
type: "image_url", uno para cada imagen que se envía. Las imágenes se incluyen secuencialmente después del prompt de texto.
- Un diccionario de
- Diseño del prompt para tareas multi-imagen: El prompt hace referencia explícita a las dos imágenes (por ejemplo, "la primera imagen", "la segunda imagen", o por nombre de archivo como se hace aquí) y establece claramente la tarea que involucra ambas imágenes (por ejemplo, "Compara la Versión 1 y la Versión 2", "enumera las diferencias").
- Llamada a la API (
client.chat.completions.create):- Especifica el modelo
gpt-4o, que admite entradas múltiples de imágenes. - Envía la lista estructurada de
messagesque contiene el prompt de texto y múltiples imágenes codificadas en base64. - Establece
max_tokensapropiado para la salida esperada (una lista de diferencias).
- Especifica el modelo
- Manejo de respuesta: Imprime la respuesta textual de GPT-4o, que debe contener los resultados de la comparación basados en el prompt y las dos imágenes proporcionadas. El uso de tokens refleja el procesamiento del texto y todas las imágenes.
- Manejo de errores: Incluye verificaciones estándar, enfatizando posibles problemas con cualquiera de los archivos de imagen.
- Relevancia de casos de uso: Esto aborda directamente la capacidad de "Entrada Multi-Imagen". Es útil para comparación de versiones (diseños, documentos), análisis de secuencias (fotos de antes/después), combinación de información de diferentes fuentes visuales (por ejemplo, fotos de productos + tabla de tallas), o cualquier tarea donde se requiera entender la relación o diferencias entre múltiples imágenes.
Recuerda proporcionar dos archivos de imagen distintos (por ejemplo, dos versiones diferentes de una maqueta de UI) al probar este código, y actualizar las variables image_path_1 y image_path_2 según corresponda.
1.3.6 Privacidad y Seguridad
A medida que los sistemas de IA procesan y analizan cada vez más datos visuales, entender las implicaciones de privacidad y seguridad se vuelve fundamental. Esta sección explora los aspectos críticos de la protección de datos de imagen al trabajar con modelos de IA habilitados para visión, cubriendo todo desde protocolos básicos de seguridad hasta mejores prácticas para el manejo responsable de datos.
Examinaremos las medidas técnicas de seguridad implementadas, las estrategias de gestión de datos y las consideraciones esenciales de privacidad que los desarrolladores deben abordar al construir aplicaciones que procesan imágenes enviadas por usuarios. Entender estos principios es crucial para mantener la confianza del usuario y asegurar el cumplimiento de las regulaciones de protección de datos.
Las áreas clave que cubriremos incluyen:
- Protocolos de seguridad para la transmisión y almacenamiento de datos de imagen
- Mejores prácticas para gestionar contenido visual enviado por usuarios
- Consideraciones de privacidad y requisitos de cumplimiento
- Estrategias de implementación para procesamiento seguro de imágenes
Exploremos en detalle las medidas de seguridad integrales y consideraciones de privacidad que son esenciales para proteger datos visuales:
- Carga segura de imágenes y autenticación API:
- Los datos de imagen están protegidos mediante encriptación avanzada durante el tránsito utilizando protocolos TLS estándar de la industria, asegurando la seguridad de extremo a extremo
- Un sistema robusto de autenticación asegura que el acceso esté estrictamente limitado a solicitudes verificadas con tus credenciales API específicas, previniendo accesos no autorizados
- El sistema implementa aislamiento estricto - las imágenes asociadas con tu clave API permanecen completamente separadas e inaccesibles para otros usuarios o claves API, manteniendo la soberanía de datos
- Estrategias efectivas de gestión de datos de imagen:
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
openai.files.delete(file_id), dándote control completo sobre la retención de datos - Las mejores prácticas incluyen implementar sistemas automatizados de limpieza que eliminen regularmente las cargas temporales de imágenes, reduciendo riesgos de seguridad y sobrecarga de almacenamiento
- Las auditorías sistemáticas regulares de archivos almacenados son cruciales para mantener una organización óptima de datos y cumplimiento de seguridad
- La plataforma proporciona un método sencillo para eliminar archivos innecesarios usando
- Protección integral de privacidad del usuario:
- Implementar mecanismos explícitos de consentimiento del usuario antes de que comience cualquier análisis de imagen, asegurando transparencia y confianza
- Desarrollar e integrar flujos claros de consentimiento dentro de tu aplicación que informen a los usuarios sobre cómo se procesarán sus imágenes
- Crear políticas de privacidad detalladas que explícitamente describan los procedimientos de procesamiento de imágenes, limitaciones de uso y medidas de protección de datos
- Establecer y comunicar claramente políticas específicas de retención de datos, incluyendo cuánto tiempo se almacenan las imágenes y cuándo se eliminan automáticamente
Resumen
En esta sección, has adquirido conocimientos exhaustivos sobre las revolucionarias capacidades de visión de GPT-4o, que transforman fundamentalmente cómo los sistemas de IA procesan y comprenden el contenido visual. Esta característica revolucionaria va mucho más allá del procesamiento tradicional de texto, permitiendo a la IA realizar análisis detallados de imágenes con una comprensión similar a la humana. A través de redes neuronales avanzadas y sofisticados algoritmos de visión por computadora, el sistema puede identificar objetos, interpretar escenas, comprender el contexto e incluso reconocer detalles sutiles dentro de las imágenes. Con una eficiencia y facilidad de implementación notables, puedes aprovechar estas potentes capacidades a través de una API simplificada que procesa simultáneamente tanto imágenes como comandos en lenguaje natural.
Esta tecnología innovadora representa un cambio de paradigma en las aplicaciones de IA, abriendo una amplia gama de implementaciones prácticas en numerosos dominios:
- Educación: Crear experiencias de aprendizaje dinámicas e interactivas con explicaciones visuales y tutoría automatizada basada en imágenes
- Generar ayudas visuales personalizadas para conceptos complejos
- Proporcionar retroalimentación en tiempo real sobre dibujos o diagramas de estudiantes
- Accesibilidad: Desarrollar herramientas sofisticadas que proporcionen descripciones detalladas de imágenes para usuarios con discapacidad visual
- Generar descripciones contextuales de imágenes con detalles relevantes
- Crear narrativas de audio a partir de contenido visual
- Análisis: Realizar análisis sofisticados de datos visuales para inteligencia empresarial e investigación
- Extraer información de gráficos, diagramas y esquemas técnicos
- Analizar tendencias en datos visuales a través de grandes conjuntos de datos
- Automatización: Optimizar flujos de trabajo con procesamiento y categorización automatizada de imágenes
- Clasificar y etiquetar automáticamente contenido visual
- Procesar documentos con contenido mixto de texto e imágenes
A lo largo de esta exploración exhaustiva, has dominado varias capacidades esenciales que forman la base de la implementación de IA visual:
- Cargar e interpretar imágenes: Domina los fundamentos técnicos de integrar la API en tus aplicaciones, incluyendo el formato adecuado de imágenes, procedimientos eficientes de carga y comprensión de los diversos parámetros que afectan la precisión de interpretación. Aprende a recibir y analizar interpretaciones detalladas y contextualizadas que pueden impulsar el procesamiento posterior.
- Usar prompts multimodales con texto + imagen: Desarrolla experiencia en la creación de prompts efectivos que combinen perfectamente instrucciones textuales con entradas visuales. Comprende cómo estructurar consultas que aprovechen ambas modalidades para obtener resultados más precisos y matizados. Aprende técnicas avanzadas de prompting que pueden guiar la atención de la IA hacia aspectos específicos de las imágenes.
- Construir asistentes que ven antes de hablar: Crea aplicaciones sofisticadas de IA que procesan información visual como parte fundamental de su proceso de toma de decisiones. Aprende a desarrollar sistemas que pueden entender el contexto tanto de entradas visuales como textuales, lo que lleva a interacciones más inteligentes, naturales y conscientes del contexto que verdaderamente conectan la brecha entre la comprensión humana y la máquina.