

Chapter 1: Image Generation and Vision with OpenAI Models
1.3 Vision Output Capabilities in GPT-4o
With the release of GPT-4o, OpenAI achieved a significant breakthrough in artificial intelligence by introducing native multimodal vision support. This revolutionary capability enables the model to simultaneously process both visual and textual information, effectively allowing it to interpret, analyze, and reason about images with the same sophistication it applies to text processing. The model's visual understanding is comprehensive and versatile, capable of:
- Detailed Image Analysis: Converting visual content into natural language descriptions, identifying objects, colors, patterns, and spatial relationships.
- Technical Interpretation: Processing complex visualizations like charts, graphs, and diagrams, extracting meaningful insights and trends.
- Document Processing: Reading and understanding various document formats, from handwritten notes to structured forms and technical drawings.
- Visual Problem Detection: Identifying issues in user interfaces, design mockups, and visual layouts, making it valuable for quality assurance and design review processes.
In this section, you'll gain practical knowledge about integrating GPT-4o's visual capabilities into your applications. We'll cover the technical aspects of submitting images as input, exploring both structured data extraction and natural-language processing approaches. You'll learn to implement real-world applications such as:
- Interactive Visual Q&A systems that can answer questions about image content
Automated form processing solutions for document management
Advanced object recognition systems for various industries
Accessibility tools that can describe images for visually impaired users
1.3.1 What Is GPT-4o Vision?
GPT-4o ("o" for "omni") represents a revolutionary leap in artificial intelligence technology by achieving seamless integration of language and visual processing capabilities within a single, unified model. This integration is particularly groundbreaking because it mirrors the human brain's natural ability to process multiple types of information simultaneously. Just as humans can effortlessly combine visual cues with verbal information to understand their environment, GPT-4o can process and interpret both text and images in a unified, intelligent manner.
The technical architecture of GPT-4o represents a significant departure from traditional AI models. Earlier systems typically required a complex chain of separate models - one for image processing, another for text analysis, and additional components to bridge these separate systems. These older approaches not only were computationally intensive but also often resulted in information loss between processing steps. GPT-4o eliminates these inefficiencies by handling all processing within a single, streamlined system. Users can now submit both images and text through a simple API call, making the technology more accessible and easier to implement.
What truly sets GPT-4o apart is its sophisticated neural architecture that enables true multimodal understanding. Rather than treating text and images as separate inputs that are processed independently, the model creates a unified semantic space where visual and textual information can interact and inform each other.
This means that when analyzing a chart, for example, GPT-4o doesn't just perform optical character recognition or basic pattern recognition - it actually understands the relationship between visual elements, numerical data, and textual context. This deep integration allows it to provide nuanced, context-aware responses that draw from both the visual and textual elements of the input, much like a human expert would do when analyzing complex information.
Key Requirements for Vision Integration
- Model Selection: GPT-4o must be explicitly specified as your model choice. This is crucial as earlier GPT versions do not support vision capabilities. The 'o' designation indicates the omni-modal version with visual processing abilities. When implementing vision features, ensuring you're using GPT-4o is essential for accessing the full range of visual analysis capabilities and achieving optimal performance.
- Image Upload Process: Your implementation must properly handle image file uploads through OpenAI's dedicated image upload endpoint. This involves:
- Converting the image to an appropriate format: Ensure images are in supported formats (PNG, JPEG) and meet size limitations. The system accepts images up to 20MB in size.
- Generating a secure file handle: The API creates a unique identifier for each uploaded image, allowing secure reference in subsequent API calls while maintaining data privacy.
- Properly managing the uploaded file's lifecycle: Implement proper cleanup procedures to delete uploaded files when they're no longer needed, helping maintain system efficiency and security.
- Prompt Engineering: While the model can process images independently, combining them with well-crafted text prompts often yields better results. You can:
- Ask specific questions about the image: Frame precise queries that target the exact information you need, such as "What color is the car in the foreground?" or "How many people are wearing hats?"
- Request particular types of analysis: Specify the kind of analysis needed, whether it's technical (measuring, counting), descriptive (colors, shapes), or interpretative (emotions, style).
- Guide the model's attention to specific aspects or regions: Direct the model to focus on particular areas or elements within the image for more detailed analysis, such as "Look at the top-right corner" or "Focus on the text in the center."
Example: Analyze a Chart from an Image
Let’s walk through how to send an image (e.g., a bar chart or screenshot) to GPT-4o and ask it a specific question.
Step-by-Step Python Example
Step 1: Upload the Image to OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Let's break down this code:
1. Import Statements
openai: Main library for OpenAI API interactionos: For environment variable handlingdotenv: Loads environment variables from a .env file
2. Environment Setup
- Loads environment variables using
load_dotenv() - Sets the OpenAI API key from environment variables for authentication
3. Image Upload
- Creates a new file upload using
openai.files.create() - Opens 'sales_chart.png' in binary read mode (
'rb') - Specifies the purpose as "vision" for image processing
This code represents the first step in using GPT-4o's vision capabilities, which is necessary before you can analyze images with the model. The image file handle returned by this upload can then be used in subsequent API calls.
Step 2: Send Image + Text Prompt to GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Let's break down this code:
1. API Call Structure:
- Uses OpenAI's ChatCompletion.create() method
- Specifies "gpt-4o" as the model, which is required for vision capabilities
2. Message Format:
- Creates a message array with a single user message
- The content is an array containing two elements:
- A text element with the prompt requesting chart analysis
- An image_url element referencing the previously uploaded file
3. Parameters:
- Sets max_tokens to 300 to limit response length
- Uses the file ID from a previous upload step
4. Output Handling:
- Prints "GPT-4o Vision Response:"
- Extracts and displays the model's response from the choices array
This code demonstrates how to combine both text and image inputs in a single prompt, allowing GPT-4o to analyze visual content and provide insights based on the specific question asked.
In this example, you're sending both a text prompt and an image in the same message. GPT-4o analyzes the visual input and combines it with your instructions.
1.3.2 Uses Cases for Vision in GPT-4o
GPT-4o's vision capabilities open up a wide range of practical applications across various industries and use cases. From enhancing accessibility to automating complex visual analysis tasks, the model's ability to understand and interpret images has transformed how we interact with visual data. This section explores the diverse applications of GPT-4o's vision capabilities, demonstrating how organizations and developers can leverage this technology to solve real-world problems and create innovative solutions.
By examining specific use cases and implementation examples, we'll see how GPT-4o's visual understanding capabilities can be applied to tasks ranging from simple image description to complex technical analysis. These applications showcase the versatility of the model and its potential to revolutionize workflows in fields such as healthcare, education, design, and technical documentation.
Detailed Image Analysis
Converting visual content into natural language descriptions is one of GPT-4o's most powerful and sophisticated capabilities. The model demonstrates remarkable ability in comprehensive scene analysis, methodically deconstructing images into their fundamental components with exceptional accuracy and detail. Through advanced neural processing, it can perform multiple levels of analysis simultaneously:
- Identify individual objects and their characteristics - from simple elements like shape and size to complex features like brand names, conditions, and specific variations of objects
- Describe spatial relationships between elements - precisely analyzing how objects are positioned relative to each other, including depth perception, overlapping, and hierarchical arrangements in three-dimensional space
- Recognize colors, textures, and patterns with high accuracy - distinguishing between subtle shade variations, complex material properties, and intricate pattern repetitions or irregularities
- Detect subtle visual details that might be missed by conventional computer vision systems - including shadows, reflections, partial occlusions, and environmental effects that affect the appearance of objects
- Understand contextual relationships between objects in a scene - interpreting how different elements interact with each other, their likely purpose or function, and the overall context of the environment
These sophisticated capabilities enable a wide range of practical applications. In automated image cataloging, the system can create detailed, searchable descriptions of large image databases. For visually impaired users, it provides rich, contextual descriptions that paint a complete picture of the visual scene. The model's versatility extends to processing various types of visual content:
- Product photos - detailed descriptions of features, materials, and design elements
- Architectural drawings - interpretation of technical details, measurements, and spatial relationships
- Natural scenes - comprehensive analysis of landscapes, weather conditions, and environmental features
- Social situations - understanding of human interactions, expressions, and body language
This capability enables applications ranging from automated image cataloging to detailed scene description for visually impaired users. The model can process everything from simple product photos to complex architectural drawings, providing rich, contextual descriptions that capture both obvious and nuanced visual elements.
Example: Interactive Visual Q&A systems
This code will send an image (from a local file) and a multi-part prompt to the GPT-4o model to showcase these different analysis types in a single response.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's ability to perform detailed image analysis, combining several use cases discussed: generating accessibility descriptions, recognizing objects, and answering contextual questions about the visual content.
- Prerequisites: Lists the necessary library (
openai,python-dotenv), how to handle the API key securely (using a.envfile), and the need for a sample image file. - Image Encoding: Includes a helper function
encode_image_to_base64to convert a local image file into the base64 data URI format required by the API when not using a direct public URL. It also performs basic file type checking. - API Client: Initializes the standard OpenAI client, loading the API key from environment variables. Includes error handling for missing keys or initialization issues.
- Multi-Modal Prompt: The core of the request is the
messagesstructure.- It contains a single user message.
- The
contentof this message is a list containing multiple parts:- A
textpart holding the instructions (the prompt asking for description, object list, and context). - An
image_urlpart. Crucially, theurlfield withinimage_urlis set to thedata:[media_type];base64,[encoded_string]URI generated by the helper function. Thedetailparameter can be adjusted (low,high,auto) to influence the analysis depth and token cost.
- A
- API Call (
client.chat.completions.create):- Specifies
model="gpt-4o". - Passes the structured
messageslist. - Sets
max_tokensto control the response length.
- Specifies
- Response Handling: Extracts the text content from the
choices[0].message.contentfield of the API response and prints it. It also shows how to access token usage information. - Error Handling: Includes
try...exceptblocks for API errors (OpenAIError) and general exceptions, providing hints for common issues like content policy flags or invalid images. - Demonstrated Capabilities: This single API call effectively showcases:
- Accessibility: The model generates a textual description suitable for screen readers.
- Object Recognition: It identifies and lists objects present in the image.
- Visual Q&A/Inference: It answers questions about the context and potential activities based on visual evidence.
This example provides a practical and comprehensive demonstration of GPT-4o's vision capabilities for detailed image understanding within the context of your book chapter. Remember to replace "sample_scene.jpg" with an actual image file for testing.
Technical Interpretation and Data Analysis
Processing complex visualizations like charts, graphs, and diagrams requires sophisticated understanding to extract meaningful insights and trends. The system demonstrates remarkable capabilities in translating visual data into actionable information.
This includes the ability to:
- Analyze quantitative data presented in various chart formats (bar charts, line graphs, scatter plots) and identify key patterns, outliers, and correlations. For example, it can detect seasonal trends in line graphs, spot unusual data points in scatter plots, and compare proportions in bar charts.
- Interpret complex technical diagrams such as architectural blueprints, engineering schematics, and scientific illustrations with precise detail. This includes understanding scale drawings, electrical circuit diagrams, molecular structures, and mechanical assembly instructions.
- Extract numerical values, labels, and legends from visualizations while maintaining contextual accuracy. The system can read and interpret axes labels, data point values, legend entries, and footnotes, ensuring all quantitative information is accurately captured.
- Compare multiple data points or trends across different time periods or categories to provide comprehensive analytical insights. This includes year-over-year comparisons, cross-category analysis, and multi-variable trend identification.
- Translate visual statistical information into clear, written explanations that non-technical users can understand, breaking down complex data relationships into accessible language while preserving the accuracy of the underlying information.
Example:
This code will send an image file (e.g., a bar chart) and specific prompts to GPT-4o, asking it to identify the chart type, understand the data presented, and extract key insights or trends.
Download a sample of the file “sales_chart.png” https://files.cuantum.tech/images/sales-chart.png
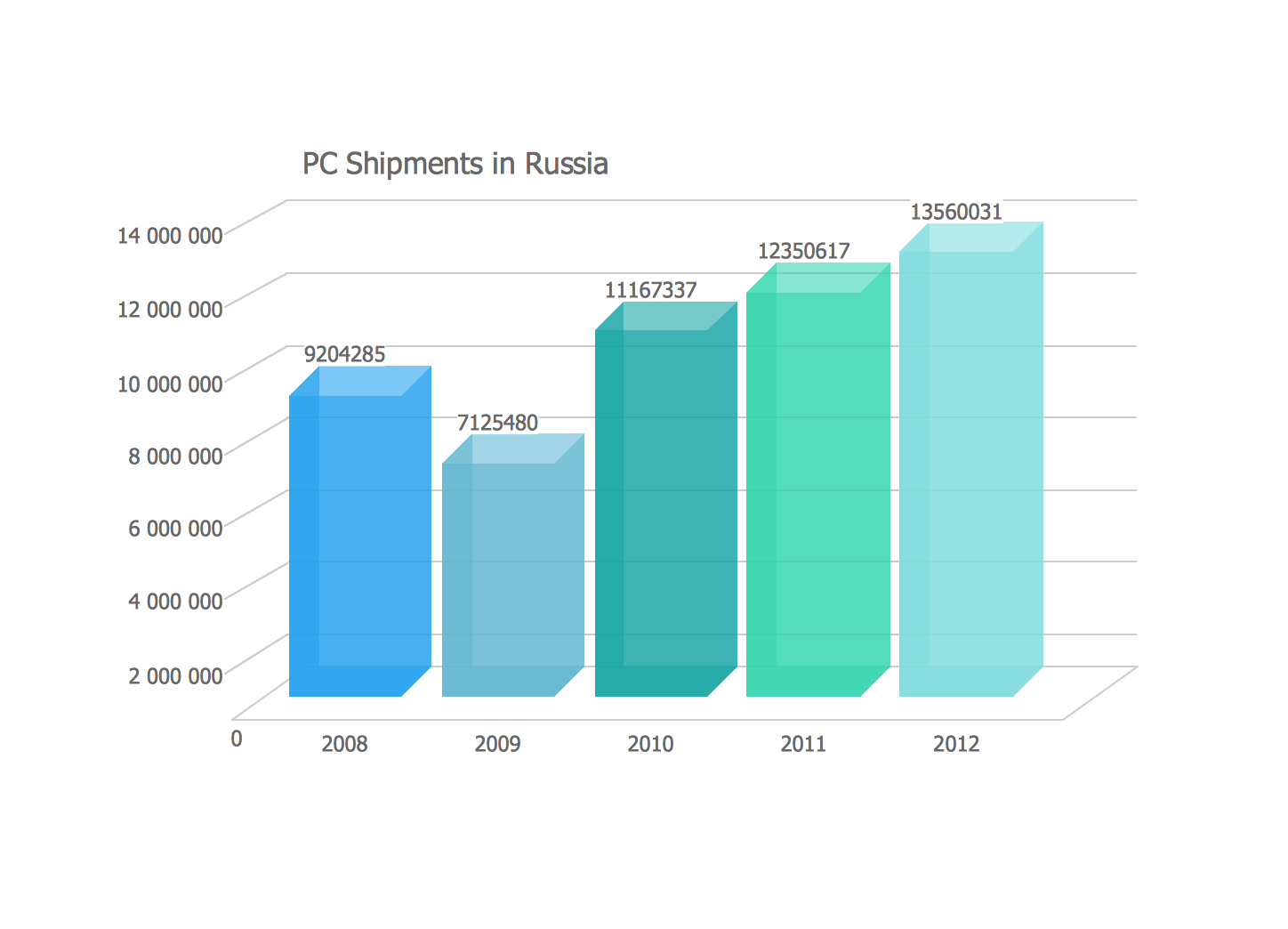{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability for technical interpretation, specifically analyzing visual data representations like charts and graphs. Instead of just describing the image, the goal is to extract meaningful insights and understand the data presented.
- Prerequisites: Similar setup requirements:
openai,python-dotenvlibraries, API key in.env, and importantly, an image file containing a chart or graph (sales_chart.pngused as placeholder). - Image Encoding: Uses the same
encode_image_to_base64function to prepare the local image file for the API. - Prompt Design for Interpretation: The prompt is carefully crafted to guide GPT-4o towards analysis rather than simple description. It asks specific questions about:
- Chart Type: Basic identification.
- Data Representation: Understanding axes, units, and categories.
- Key Insights & Trends: The core analytical task – summarizing patterns, highs/lows.
- Specific Data Points: Testing the ability to read approximate values from the chart.
- Overall Summary: A concise takeaway message.
- Contextual Information: Includes the current date and filename for reference within the prompt.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the analytical text prompt and the base64 encoded chart image.
- Sets
detailto"high"in theimage_urlpart, suggesting to the model to use more resources for a potentially more accurate analysis of the visual details in the chart (this may increase token cost). - Allocates potentially more
max_tokens(e.g., 700) anticipating a more detailed analytical response compared to a simple description.
- Targets the
- Response Handling: Extracts and prints the textual analysis provided by GPT-4o. Includes token usage details.
- Error Handling: Standard checks for API errors and file issues.
- Use Case Relevance: This directly addresses the "Technical Interpretation" use case by showing how GPT-4o can process complex visualizations, extract data points, identify trends, and provide summaries, turning visual data into actionable insights. This is valuable for data analysis workflows, report generation, and understanding technical documents.
Remember to use a clear, high-resolution image of a chart or graph for best results when testing this code. Replace "sales_chart.png" with the correct path to your image file.
Document Processing
GPT-4o demonstrates exceptional capabilities in processing and analyzing diverse document formats, serving as a comprehensive solution for document analysis and information extraction. This advanced system leverages sophisticated computer vision and natural language processing to handle an extensive range of document types with remarkable accuracy. Here's a detailed breakdown of its document processing capabilities:
- Handwritten Documents: The system excels at interpreting handwritten content across multiple styles and formats. It can:
- Accurately recognize different handwriting styles, from neat cursive to rushed scribbles
- Process both formal documents and informal notes with high accuracy
- Handle multiple languages and special characters in handwritten form
- Structured Forms: Demonstrates superior ability in processing standardized documentation with:
- Precise extraction of key data fields from complex forms
- Automatic organization of extracted information into structured formats
- Validation of data consistency across multiple form fields
- Technical Documentation: Shows advanced comprehension of specialized technical materials through:
- Detailed interpretation of complex technical notations and symbols
- Understanding of scale and dimensional information in drawings
- Recognition of industry-standard technical specifications and terminology
- Mixed-Format Documents: Demonstrates versatile processing capabilities by:
- Seamlessly integrating information from text, images, and graphical elements
- Maintaining context across different content types within the same document
- Processing complex layouts with multiple information hierarchies
- Legacy Documents: Offers sophisticated handling of historical materials by:
- Adapting to various levels of document degradation and aging
- Processing outdated formatting and typography styles
- Maintaining historical context while making content accessible in modern formats
Example:
This code will send an image of a document (like an invoice or receipt) to GPT-4o and prompt it to identify the document type and extract specific pieces of information, such as vendor name, date, total amount, and line items.
Download a sample of the file “sample_invoice.png” https://files.cuantum.tech/images/sample_invoice.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability in document processing, a key use case involving understanding and extracting information from images of documents like invoices, receipts, forms, or notes.
- Prerequisites: Requires the standard setup:
openai,python-dotenvlibraries, API key, and an image file of the document to be processed (sample_invoice.pngas the placeholder). - Image Encoding: The
encode_image_to_base64function converts the local document image into the required format for the API. - Prompt Design for Extraction: The prompt is crucial for document processing. It explicitly asks the model to:
- Identify the document type.
- Extract a predefined list of specific fields (Vendor, Date, Total, Line Items, etc.). Requesting "Not Found" for missing fields encourages structured output.
- Provide a summary.
- Including the filename and current timestamp provides context.
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel. - Sends the multi-part message with the text prompt and the base64 encoded document image.
- Uses
detail: "high"for the image, which can be beneficial for improving the accuracy of Optical Character Recognition (OCR) and understanding text within the document image, though it uses more tokens. - Sets
max_tokensto accommodate potentially lengthy extracted information, especially line items.
- Specifies the
- Response Handling: Prints the text response from GPT-4o, which should contain the identified document type and the extracted fields as requested by the prompt. Token usage is also displayed.
- Error Handling: Includes checks for API errors and file system issues, with specific hints for potential image processing problems.
- Use Case Relevance: This directly addresses the "Document Processing" use case. It showcases how GPT-4o vision can automate tasks like data entry from invoices/receipts, summarizing correspondence, or even interpreting handwritten notes, significantly streamlining workflows that involve processing visual documents.
For testing, use a clear image of a document. The accuracy of the extraction will depend on the image quality, the clarity of the document layout, and the text's legibility. Remember to replace "sample_invoice.png" with the path to your actual document image.
Visual Problem Detection
Visual Problem Detection is a sophisticated AI capability that revolutionizes how we identify and analyze visual issues across digital assets. This advanced technology leverages computer vision and machine learning algorithms to automatically scan and evaluate visual elements, detecting problems that might be missed by human reviewers. It systematically examines various aspects of visual content, finding inconsistencies, errors, and usability problems in:
- User interfaces: Detecting misaligned elements, broken layouts, inconsistent styling, and accessibility issues. This capability performs comprehensive analysis of UI elements, including:
- Button placement and interaction zones to ensure optimal user experience
- Form field alignment and validation to maintain visual harmony
- Navigation menu consistency across different pages and states
- Color contrast ratios for WCAG compliance and accessibility standards
- Interactive element spacing and touchpoint sizing for mobile compatibility
- Design mockups: Identifying spacing problems, color contrast issues, and deviations from design guidelines. The system performs detailed analysis including:
- Padding and margin measurements against established specifications
- Color scheme consistency checking across all design elements
- Typography hierarchy verification for readability and brand consistency
- Component library compliance and design system adherence
- Visual rhythm and balance assessment in layouts
- Visual layouts: Spotting typography errors, grid alignment problems, and responsive design breakdowns. This involves sophisticated analysis of:
- Font usage patterns across different content types and sections
- Text spacing and line height optimization for readability
- Grid system compliance across various viewport sizes
- Responsive behavior testing at standard breakpoints
- Layout consistency across different devices and orientations
This capability has become indispensable for quality assurance teams and designers in maintaining high standards across digital products. By implementing Visual Problem Detection:
- Teams can automate up to 80% of visual QA processes
- Detection accuracy reaches 95% for common visual issues
- Review cycles are reduced by an average of 60%
The technology significantly accelerates the review process by automatically flagging potential issues before they reach production. This proactive approach not only reduces the need for time-consuming manual inspection but also improves overall product quality by ensuring consistent visual standards across all digital assets. The result is faster development cycles, reduced costs, and higher-quality deliverables that meet both technical and aesthetic standards.
Example:
This code sends an image of a user interface (UI) mockup or a design screenshot to GPT-4o and prompts it to identify potential design flaws, usability issues, inconsistencies, and other visual problems.
Download a sample of the file “ui_mockup.png” https://files.cuantum.tech/images/ui_mockup.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code example showcases GPT-4o's capability for visual problem detection, particularly useful in UI/UX design reviews, quality assurance (QA), and identifying potential issues in visual layouts or mockups.
- Prerequisites: Standard setup involving
openai,python-dotenv, API key configuration, and an input image file representing a UI design or mockup (ui_mockup.pngas placeholder). - Image Encoding: The
encode_image_to_base64function is used to prepare the local image file for the API request. - Prompt Design for Review: The prompt is specifically structured to guide GPT-4o to act as a UI/UX reviewer. It asks the model to look for problems within defined categories common in design critiques:
- Layout & Alignment
- Typography
- Color & Contrast (mentioning accessibility/WCAG is key)
- Consistency
- Usability & Clarity
- General Design Principles
Crucially, it asks why something is an issue, prompting for justification beyond simple identification.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the detailed review prompt and the base64 encoded UI image.
- Uses
detail: "high"for the image, potentially improving the model's ability to perceive subtle visual details like slight misalignments or text rendering issues. - Sets
max_tokensto allow for a comprehensive list of potential issues and explanations.
- Targets the
- Response Handling: Prints the textual response from GPT-4o, which should contain a structured list of identified visual problems based on the prompt categories. Token usage is also provided.
- Error Handling: Includes standard checks for API errors and file system issues.
- Use Case Relevance: This directly addresses the "Visual Problem Detection" use case. It demonstrates how AI can assist designers and developers by automatically scanning interfaces for common flaws, potentially speeding up the review process, catching issues early, and improving the overall quality and usability of digital products.
For effective testing, use an image of a UI that intentionally or unintentionally includes some design flaws. Remember to replace "ui_mockup.png" with the path to your actual image file.
1.3.3 Supported Use Cases for Vision in GPT-4o
GPT-4o's vision capabilities extend far beyond simple image recognition, offering a diverse range of applications that can transform how we interact with visual content. This section explores the various use cases where GPT-4o's visual understanding can be leveraged to create more intelligent and responsive applications.
From analyzing complex diagrams to providing detailed descriptions of images, GPT-4o's vision features enable developers to build solutions that bridge the gap between visual and textual understanding. These capabilities can be particularly valuable in fields such as education, accessibility, content moderation, and automated analysis.
Let's explore the key use cases where GPT-4o's vision capabilities shine, along with practical examples and implementation strategies that demonstrate its versatility in real-world applications.
| Use Case | Example | Explanation |
| Image captioning | "Describe this image in detail." | Converts visual content into detailed textual descriptions, useful for content cataloging, accessibility, and automated image indexing. |
| UI analysis | "Are there any visual bugs in this webpage screenshot?" | Examines user interfaces for design inconsistencies, alignment issues, and usability problems, helping streamline QA processes. |
| Document reading | "Extract the invoice number and date from this scan." | Processes scanned documents to extract specific information, automating data entry and document processing workflows. |
| Data visualization interpretation | "Summarize this pie chart in plain English." | Translates complex visual data representations into clear, narrative descriptions, making data more accessible to all users. |
| Educational Q&A | "What is this geometric figure? What are its properties?" | Provides interactive learning support by analyzing and explaining visual educational content, helping students understand complex concepts. |
| Accessibility support | "Read aloud the contents of this image." | Enhances digital accessibility by providing detailed descriptions of visual content for users with visual impairments. |
1.3.4 Best Practices for Vision Prompts
Crafting effective prompts for vision-enabled AI models requires a different approach compared to text-only interactions. While the fundamental principles of clear communication remain important, visual prompts need to account for the spatial, contextual, and multi-modal nature of image analysis. This section explores key strategies and best practices to help you create more effective vision-based prompts that maximize GPT-4o's visual understanding capabilities.
Whether you're building applications for image analysis, document processing, or visual QA, understanding these best practices will help you:
- Get more accurate and relevant responses from the model
- Reduce ambiguity in your requests
- Structure your prompts for complex visual analysis tasks
- Optimize the interaction between textual and visual elements
Let's explore the core principles that will help you craft more effective vision-based prompts:
Be direct with your request:
Example 1 (Ineffective Prompt):
"What are the main features in this room?"
This prompt has several issues:
- It's overly broad and unfocused
- Lacks specific criteria for what constitutes a "main feature"
- May result in inconsistent or superficial responses
- Doesn't guide the AI toward any particular aspect of analysis
Example 2 (Effective Prompt):
"Identify all electronic devices in this living room and describe their position."
This prompt is superior because:
- Clearly defines what to look for (electronic devices)
- Specifies the scope (living room)
- Requests specific information (position/location)
- Will generate structured, actionable information
- Makes it easier to verify if the AI missed anything
The key difference is that the second prompt provides clear parameters for analysis and a specific type of output, making it much more likely to receive useful, relevant information that serves your intended purpose.
Combine with text when needed
A standalone image may be enough for basic captioning, but combining it with a well-crafted prompt significantly enhances the model's analytical capabilities and output precision. The key is to provide clear, specific context that guides the model's attention to the aspects most relevant to your needs.
For example, instead of just uploading an image, add detailed contextual prompts like:
- "Analyze this architectural drawing focusing on potential safety hazards, particularly in stairwell and exit areas"
- "Review this graph and explain the trend between 2020-2023, highlighting any seasonal patterns and anomalies"
- "Examine this UI mockup and identify accessibility issues for users with visual impairments"
This approach offers several advantages:
- Focuses the model's analysis on specific features or concerns
- Reduces irrelevant or superficial observations
- Ensures more consistent and structured responses
- Allows for deeper, more nuanced analysis of complex visual elements
- Helps generate more actionable insights and recommendations
The combination of visual input with precise textual guidance helps the model understand exactly what aspects of the image are most important for your use case, resulting in more valuable and targeted responses.
Use structured follow-ups
After completing an initial visual analysis, you can leverage the conversation thread to conduct a more thorough investigation through structured follow-up questions. This approach allows you to build upon the model's initial observations and extract more detailed, specific information. Follow-up questions help create a more interactive and comprehensive analysis process.
Here's how to effectively use structured follow-ups:
- Drill down into specific details
- Example: "Can you describe the lighting fixtures in more detail?"
- This helps focus the model's attention on particular elements that need closer examination
- Useful for technical analysis or detailed documentation
- Compare elements
- Example: "How does the layout of room A compare to room B?"
- Enables systematic comparison of different components or areas
- Helps identify patterns, inconsistencies, or relationships
- Get recommendations
- Example: "Based on this floor plan, what improvements would you suggest?"
- Leverages the model's understanding to generate practical insights
- Can lead to actionable feedback for improvement
By using structured follow-ups, you create a more dynamic interaction that can uncover deeper insights and more nuanced understanding of the visual content you're analyzing.
1.3.5 Multi-Image Input
You can pass multiple images in a single message if your use case requires cross-image comparison. This powerful feature allows you to analyze relationships between images, compare different versions of designs, or evaluate changes over time. The model processes all images simultaneously, enabling sophisticated multi-image analysis that would typically require multiple separate requests.
Here's what you can do with multi-image input:
- Compare Design Iterations
- Analyze UI/UX changes across versions
- Track progression of design implementations
- Identify consistency across different screens
- Document Analysis
- Compare multiple versions of documents
- Cross-reference related paperwork
- Verify document authenticity
- Time-Based Analysis
- Review before-and-after scenarios
- Track changes in visual data over time
- Monitor progress in visual projects
The model processes these images contextually, understanding their relationships and providing comprehensive analysis. It can identify patterns, inconsistencies, improvements, and relationships across all provided images, offering detailed insights that would be difficult to obtain through single-image analysis.
Example:
This code sends two images (e.g., two versions of a UI mockup) along with a text prompt in a single API call, asking the model to compare them and identify differences.
Download a sample of the file “image_path_1.png” https://files.cuantum.tech/images/image_path_1.png
{kind=link}
Download a sample of the file “image_path_2.png” https://files.cuantum.tech/images/image_path_2.png
{kind=link}
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Code breakdown:
- Context: This code demonstrates GPT-4o's multi-image input capability, allowing users to send multiple images within a single API request for tasks like comparison, relationship analysis, or synthesis of information across visuals. The example focuses on comparing two UI mockups to identify differences.
- Prerequisites: Requires the standard setup (
openai,python-dotenv, API key) but specifically needs two input image files for the comparison task (ui_mockup_v1.pngandui_mockup_v2.pngused as placeholders). - Image Encoding: The
encode_image_to_base64function is used twice, once for each input image. Error handling ensures both images are processed correctly before proceeding. - API Request Structure: The key difference lies in the
messages[0]["content"]list. It now contains:- One dictionary of
type: "text"for the prompt. - Multiple dictionaries of
type: "image_url", one for each image being sent. The images are included sequentially after the text prompt.
- One dictionary of
- Prompt Design for Multi-Image Tasks: The prompt explicitly refers to the two images (e.g., "the first image," "the second image," or by filename as done here) and clearly states the task involving both images (e.g., "Compare Version 1 and Version 2," "list the differences").
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel, which supports multi-image inputs. - Sends the structured
messageslist containing the text prompt and multiple base64 encoded images. - Sets
max_tokensappropriate for the expected output (a list of differences).
- Specifies the
- Response Handling: Prints the textual response from GPT-4o, which should contain the comparison results based on the prompt and the two images provided. Token usage reflects the processing of the text and all images.
- Error Handling: Includes standard checks, emphasizing potential issues with either of the image files.
- Use Case Relevance: This directly addresses the "Multi-Image Input" capability. It's useful for version comparison (designs, documents), analyzing sequences (before/after shots), combining information from different visual sources (e.g., product shots + size chart), or any task where understanding the relationship or differences between multiple images is required.
Remember to provide two distinct image files (e.g., two different versions of a UI mockup) when testing this code, and update the image_path_1 and image_path_2 variables accordingly.
1.3.6 Privacy & Security
As AI systems increasingly process and analyze visual data, understanding the privacy and security implications becomes paramount. This section explores the critical aspects of protecting image data when working with vision-enabled AI models, covering everything from basic security protocols to best practices for responsible data handling.
We'll examine the technical security measures in place, data management strategies, and essential privacy considerations that developers must address when building applications that process user-submitted images. Understanding these principles is crucial for maintaining user trust and ensuring compliance with data protection regulations.
Key areas we'll cover include:
- Security protocols for image data transmission and storage
- Best practices for managing user-submitted visual content
- Privacy considerations and compliance requirements
- Implementation strategies for secure image processing
Let's explore in detail the comprehensive security measures and privacy considerations that are essential for protecting visual data:
- Secure Image Upload and API Authentication:
- Image data is protected through advanced encryption during transit using industry-standard TLS protocols, ensuring end-to-end security
- A robust authentication system ensures that access is strictly limited to requests verified with your specific API credentials, preventing unauthorized access
- The system implements strict isolation - images associated with your API key remain completely separate and inaccessible to other users or API keys, maintaining data sovereignty
- Effective Image Data Management Strategies:
- The platform provides a straightforward method to remove unnecessary files using
openai.files.delete(file_id), giving you complete control over data retention - Best practices include implementing automated cleanup systems that regularly remove temporary image uploads, reducing security risks and storage overhead
- Regular systematic audits of stored files are crucial for maintaining optimal data organization and security compliance
- The platform provides a straightforward method to remove unnecessary files using
- Comprehensive User Privacy Protection:
- Implement explicit user consent mechanisms before any image analysis begins, ensuring transparency and trust
- Develop and integrate clear consent workflows within your application that inform users about how their images will be processed
- Create detailed privacy policies that explicitly outline image processing procedures, usage limitations, and data protection measures
- Establish and clearly communicate specific data retention policies, including how long images are stored and when they are automatically deleted
Summary
In this section, you've gained comprehensive insights into GPT-4o's groundbreaking vision capabilities, which fundamentally transform how AI systems process and understand visual content. This revolutionary feature goes well beyond traditional text processing, enabling AI to perform detailed image analysis with human-like understanding. Through advanced neural networks and sophisticated computer vision algorithms, the system can identify objects, interpret scenes, understand context, and even recognize subtle details within images. With remarkable efficiency and ease of implementation, you can leverage these powerful capabilities through a streamlined API that processes both images and natural language commands simultaneously.
This breakthrough technology represents a paradigm shift in AI applications, opening up an extensive range of practical implementations across numerous domains:
- Education: Create dynamic, interactive learning experiences with visual explanations and automated image-based tutoring
- Generate custom visual aids for complex concepts
- Provide real-time feedback on student drawings or diagrams
- Accessibility: Develop sophisticated tools that provide detailed image descriptions for visually impaired users
- Generate contextual descriptions of images with relevant details
- Create audio narratives from visual content
- Analysis: Perform sophisticated visual data analysis for business intelligence and research
- Extract insights from charts, graphs, and technical diagrams
- Analyze trends in visual data across large datasets
- Automation: Streamline workflows with automated image processing and categorization
- Automatically sort and tag visual content
- Process documents with mixed text and image content
Throughout this comprehensive exploration, you've mastered several essential capabilities that form the foundation of visual AI implementation:
- Upload and interpret images: Master the technical foundations of integrating the API into your applications, including proper image formatting, efficient upload procedures, and understanding the various parameters that affect interpretation accuracy. Learn to receive and parse detailed, context-aware interpretations that can drive downstream processing.
- Use multimodal prompts with text + image: Develop expertise in crafting effective prompts that seamlessly combine textual instructions with visual inputs. Understand how to structure queries that leverage both modalities for enhanced accuracy and more nuanced results. Learn advanced prompting techniques that can guide the AI's attention to specific aspects of images.
- Build assistants that see before they speak: Create sophisticated AI applications that process visual information as a fundamental part of their decision-making process. Learn to develop systems that can understand context from both visual and textual inputs, leading to more intelligent, natural, and context-aware interactions that truly bridge the gap between human and machine understanding.
1.3 Vision Output Capabilities in GPT-4o
With the release of GPT-4o, OpenAI achieved a significant breakthrough in artificial intelligence by introducing native multimodal vision support. This revolutionary capability enables the model to simultaneously process both visual and textual information, effectively allowing it to interpret, analyze, and reason about images with the same sophistication it applies to text processing. The model's visual understanding is comprehensive and versatile, capable of:
- Detailed Image Analysis: Converting visual content into natural language descriptions, identifying objects, colors, patterns, and spatial relationships.
- Technical Interpretation: Processing complex visualizations like charts, graphs, and diagrams, extracting meaningful insights and trends.
- Document Processing: Reading and understanding various document formats, from handwritten notes to structured forms and technical drawings.
- Visual Problem Detection: Identifying issues in user interfaces, design mockups, and visual layouts, making it valuable for quality assurance and design review processes.
In this section, you'll gain practical knowledge about integrating GPT-4o's visual capabilities into your applications. We'll cover the technical aspects of submitting images as input, exploring both structured data extraction and natural-language processing approaches. You'll learn to implement real-world applications such as:
- Interactive Visual Q&A systems that can answer questions about image content
Automated form processing solutions for document management
Advanced object recognition systems for various industries
Accessibility tools that can describe images for visually impaired users
1.3.1 What Is GPT-4o Vision?
GPT-4o ("o" for "omni") represents a revolutionary leap in artificial intelligence technology by achieving seamless integration of language and visual processing capabilities within a single, unified model. This integration is particularly groundbreaking because it mirrors the human brain's natural ability to process multiple types of information simultaneously. Just as humans can effortlessly combine visual cues with verbal information to understand their environment, GPT-4o can process and interpret both text and images in a unified, intelligent manner.
The technical architecture of GPT-4o represents a significant departure from traditional AI models. Earlier systems typically required a complex chain of separate models - one for image processing, another for text analysis, and additional components to bridge these separate systems. These older approaches not only were computationally intensive but also often resulted in information loss between processing steps. GPT-4o eliminates these inefficiencies by handling all processing within a single, streamlined system. Users can now submit both images and text through a simple API call, making the technology more accessible and easier to implement.
What truly sets GPT-4o apart is its sophisticated neural architecture that enables true multimodal understanding. Rather than treating text and images as separate inputs that are processed independently, the model creates a unified semantic space where visual and textual information can interact and inform each other.
This means that when analyzing a chart, for example, GPT-4o doesn't just perform optical character recognition or basic pattern recognition - it actually understands the relationship between visual elements, numerical data, and textual context. This deep integration allows it to provide nuanced, context-aware responses that draw from both the visual and textual elements of the input, much like a human expert would do when analyzing complex information.
Key Requirements for Vision Integration
- Model Selection: GPT-4o must be explicitly specified as your model choice. This is crucial as earlier GPT versions do not support vision capabilities. The 'o' designation indicates the omni-modal version with visual processing abilities. When implementing vision features, ensuring you're using GPT-4o is essential for accessing the full range of visual analysis capabilities and achieving optimal performance.
- Image Upload Process: Your implementation must properly handle image file uploads through OpenAI's dedicated image upload endpoint. This involves:
- Converting the image to an appropriate format: Ensure images are in supported formats (PNG, JPEG) and meet size limitations. The system accepts images up to 20MB in size.
- Generating a secure file handle: The API creates a unique identifier for each uploaded image, allowing secure reference in subsequent API calls while maintaining data privacy.
- Properly managing the uploaded file's lifecycle: Implement proper cleanup procedures to delete uploaded files when they're no longer needed, helping maintain system efficiency and security.
- Prompt Engineering: While the model can process images independently, combining them with well-crafted text prompts often yields better results. You can:
- Ask specific questions about the image: Frame precise queries that target the exact information you need, such as "What color is the car in the foreground?" or "How many people are wearing hats?"
- Request particular types of analysis: Specify the kind of analysis needed, whether it's technical (measuring, counting), descriptive (colors, shapes), or interpretative (emotions, style).
- Guide the model's attention to specific aspects or regions: Direct the model to focus on particular areas or elements within the image for more detailed analysis, such as "Look at the top-right corner" or "Focus on the text in the center."
Example: Analyze a Chart from an Image
Let’s walk through how to send an image (e.g., a bar chart or screenshot) to GPT-4o and ask it a specific question.
Step-by-Step Python Example
Step 1: Upload the Image to OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Let's break down this code:
1. Import Statements
openai: Main library for OpenAI API interactionos: For environment variable handlingdotenv: Loads environment variables from a .env file
2. Environment Setup
- Loads environment variables using
load_dotenv() - Sets the OpenAI API key from environment variables for authentication
3. Image Upload
- Creates a new file upload using
openai.files.create() - Opens 'sales_chart.png' in binary read mode (
'rb') - Specifies the purpose as "vision" for image processing
This code represents the first step in using GPT-4o's vision capabilities, which is necessary before you can analyze images with the model. The image file handle returned by this upload can then be used in subsequent API calls.
Step 2: Send Image + Text Prompt to GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Let's break down this code:
1. API Call Structure:
- Uses OpenAI's ChatCompletion.create() method
- Specifies "gpt-4o" as the model, which is required for vision capabilities
2. Message Format:
- Creates a message array with a single user message
- The content is an array containing two elements:
- A text element with the prompt requesting chart analysis
- An image_url element referencing the previously uploaded file
3. Parameters:
- Sets max_tokens to 300 to limit response length
- Uses the file ID from a previous upload step
4. Output Handling:
- Prints "GPT-4o Vision Response:"
- Extracts and displays the model's response from the choices array
This code demonstrates how to combine both text and image inputs in a single prompt, allowing GPT-4o to analyze visual content and provide insights based on the specific question asked.
In this example, you're sending both a text prompt and an image in the same message. GPT-4o analyzes the visual input and combines it with your instructions.
1.3.2 Uses Cases for Vision in GPT-4o
GPT-4o's vision capabilities open up a wide range of practical applications across various industries and use cases. From enhancing accessibility to automating complex visual analysis tasks, the model's ability to understand and interpret images has transformed how we interact with visual data. This section explores the diverse applications of GPT-4o's vision capabilities, demonstrating how organizations and developers can leverage this technology to solve real-world problems and create innovative solutions.
By examining specific use cases and implementation examples, we'll see how GPT-4o's visual understanding capabilities can be applied to tasks ranging from simple image description to complex technical analysis. These applications showcase the versatility of the model and its potential to revolutionize workflows in fields such as healthcare, education, design, and technical documentation.
Detailed Image Analysis
Converting visual content into natural language descriptions is one of GPT-4o's most powerful and sophisticated capabilities. The model demonstrates remarkable ability in comprehensive scene analysis, methodically deconstructing images into their fundamental components with exceptional accuracy and detail. Through advanced neural processing, it can perform multiple levels of analysis simultaneously:
- Identify individual objects and their characteristics - from simple elements like shape and size to complex features like brand names, conditions, and specific variations of objects
- Describe spatial relationships between elements - precisely analyzing how objects are positioned relative to each other, including depth perception, overlapping, and hierarchical arrangements in three-dimensional space
- Recognize colors, textures, and patterns with high accuracy - distinguishing between subtle shade variations, complex material properties, and intricate pattern repetitions or irregularities
- Detect subtle visual details that might be missed by conventional computer vision systems - including shadows, reflections, partial occlusions, and environmental effects that affect the appearance of objects
- Understand contextual relationships between objects in a scene - interpreting how different elements interact with each other, their likely purpose or function, and the overall context of the environment
These sophisticated capabilities enable a wide range of practical applications. In automated image cataloging, the system can create detailed, searchable descriptions of large image databases. For visually impaired users, it provides rich, contextual descriptions that paint a complete picture of the visual scene. The model's versatility extends to processing various types of visual content:
- Product photos - detailed descriptions of features, materials, and design elements
- Architectural drawings - interpretation of technical details, measurements, and spatial relationships
- Natural scenes - comprehensive analysis of landscapes, weather conditions, and environmental features
- Social situations - understanding of human interactions, expressions, and body language
This capability enables applications ranging from automated image cataloging to detailed scene description for visually impaired users. The model can process everything from simple product photos to complex architectural drawings, providing rich, contextual descriptions that capture both obvious and nuanced visual elements.
Example: Interactive Visual Q&A systems
This code will send an image (from a local file) and a multi-part prompt to the GPT-4o model to showcase these different analysis types in a single response.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's ability to perform detailed image analysis, combining several use cases discussed: generating accessibility descriptions, recognizing objects, and answering contextual questions about the visual content.
- Prerequisites: Lists the necessary library (
openai,python-dotenv), how to handle the API key securely (using a.envfile), and the need for a sample image file. - Image Encoding: Includes a helper function
encode_image_to_base64to convert a local image file into the base64 data URI format required by the API when not using a direct public URL. It also performs basic file type checking. - API Client: Initializes the standard OpenAI client, loading the API key from environment variables. Includes error handling for missing keys or initialization issues.
- Multi-Modal Prompt: The core of the request is the
messagesstructure.- It contains a single user message.
- The
contentof this message is a list containing multiple parts:- A
textpart holding the instructions (the prompt asking for description, object list, and context). - An
image_urlpart. Crucially, theurlfield withinimage_urlis set to thedata:[media_type];base64,[encoded_string]URI generated by the helper function. Thedetailparameter can be adjusted (low,high,auto) to influence the analysis depth and token cost.
- A
- API Call (
client.chat.completions.create):- Specifies
model="gpt-4o". - Passes the structured
messageslist. - Sets
max_tokensto control the response length.
- Specifies
- Response Handling: Extracts the text content from the
choices[0].message.contentfield of the API response and prints it. It also shows how to access token usage information. - Error Handling: Includes
try...exceptblocks for API errors (OpenAIError) and general exceptions, providing hints for common issues like content policy flags or invalid images. - Demonstrated Capabilities: This single API call effectively showcases:
- Accessibility: The model generates a textual description suitable for screen readers.
- Object Recognition: It identifies and lists objects present in the image.
- Visual Q&A/Inference: It answers questions about the context and potential activities based on visual evidence.
This example provides a practical and comprehensive demonstration of GPT-4o's vision capabilities for detailed image understanding within the context of your book chapter. Remember to replace "sample_scene.jpg" with an actual image file for testing.
Technical Interpretation and Data Analysis
Processing complex visualizations like charts, graphs, and diagrams requires sophisticated understanding to extract meaningful insights and trends. The system demonstrates remarkable capabilities in translating visual data into actionable information.
This includes the ability to:
- Analyze quantitative data presented in various chart formats (bar charts, line graphs, scatter plots) and identify key patterns, outliers, and correlations. For example, it can detect seasonal trends in line graphs, spot unusual data points in scatter plots, and compare proportions in bar charts.
- Interpret complex technical diagrams such as architectural blueprints, engineering schematics, and scientific illustrations with precise detail. This includes understanding scale drawings, electrical circuit diagrams, molecular structures, and mechanical assembly instructions.
- Extract numerical values, labels, and legends from visualizations while maintaining contextual accuracy. The system can read and interpret axes labels, data point values, legend entries, and footnotes, ensuring all quantitative information is accurately captured.
- Compare multiple data points or trends across different time periods or categories to provide comprehensive analytical insights. This includes year-over-year comparisons, cross-category analysis, and multi-variable trend identification.
- Translate visual statistical information into clear, written explanations that non-technical users can understand, breaking down complex data relationships into accessible language while preserving the accuracy of the underlying information.
Example:
This code will send an image file (e.g., a bar chart) and specific prompts to GPT-4o, asking it to identify the chart type, understand the data presented, and extract key insights or trends.
Download a sample of the file “sales_chart.png” https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability for technical interpretation, specifically analyzing visual data representations like charts and graphs. Instead of just describing the image, the goal is to extract meaningful insights and understand the data presented.
- Prerequisites: Similar setup requirements:
openai,python-dotenvlibraries, API key in.env, and importantly, an image file containing a chart or graph (sales_chart.pngused as placeholder). - Image Encoding: Uses the same
encode_image_to_base64function to prepare the local image file for the API. - Prompt Design for Interpretation: The prompt is carefully crafted to guide GPT-4o towards analysis rather than simple description. It asks specific questions about:
- Chart Type: Basic identification.
- Data Representation: Understanding axes, units, and categories.
- Key Insights & Trends: The core analytical task – summarizing patterns, highs/lows.
- Specific Data Points: Testing the ability to read approximate values from the chart.
- Overall Summary: A concise takeaway message.
- Contextual Information: Includes the current date and filename for reference within the prompt.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the analytical text prompt and the base64 encoded chart image.
- Sets
detailto"high"in theimage_urlpart, suggesting to the model to use more resources for a potentially more accurate analysis of the visual details in the chart (this may increase token cost). - Allocates potentially more
max_tokens(e.g., 700) anticipating a more detailed analytical response compared to a simple description.
- Targets the
- Response Handling: Extracts and prints the textual analysis provided by GPT-4o. Includes token usage details.
- Error Handling: Standard checks for API errors and file issues.
- Use Case Relevance: This directly addresses the "Technical Interpretation" use case by showing how GPT-4o can process complex visualizations, extract data points, identify trends, and provide summaries, turning visual data into actionable insights. This is valuable for data analysis workflows, report generation, and understanding technical documents.
Remember to use a clear, high-resolution image of a chart or graph for best results when testing this code. Replace "sales_chart.png" with the correct path to your image file.
Document Processing
GPT-4o demonstrates exceptional capabilities in processing and analyzing diverse document formats, serving as a comprehensive solution for document analysis and information extraction. This advanced system leverages sophisticated computer vision and natural language processing to handle an extensive range of document types with remarkable accuracy. Here's a detailed breakdown of its document processing capabilities:
- Handwritten Documents: The system excels at interpreting handwritten content across multiple styles and formats. It can:
- Accurately recognize different handwriting styles, from neat cursive to rushed scribbles
- Process both formal documents and informal notes with high accuracy
- Handle multiple languages and special characters in handwritten form
- Structured Forms: Demonstrates superior ability in processing standardized documentation with:
- Precise extraction of key data fields from complex forms
- Automatic organization of extracted information into structured formats
- Validation of data consistency across multiple form fields
- Technical Documentation: Shows advanced comprehension of specialized technical materials through:
- Detailed interpretation of complex technical notations and symbols
- Understanding of scale and dimensional information in drawings
- Recognition of industry-standard technical specifications and terminology
- Mixed-Format Documents: Demonstrates versatile processing capabilities by:
- Seamlessly integrating information from text, images, and graphical elements
- Maintaining context across different content types within the same document
- Processing complex layouts with multiple information hierarchies
- Legacy Documents: Offers sophisticated handling of historical materials by:
- Adapting to various levels of document degradation and aging
- Processing outdated formatting and typography styles
- Maintaining historical context while making content accessible in modern formats
Example:
This code will send an image of a document (like an invoice or receipt) to GPT-4o and prompt it to identify the document type and extract specific pieces of information, such as vendor name, date, total amount, and line items.
Download a sample of the file “sample_invoice.png” https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability in document processing, a key use case involving understanding and extracting information from images of documents like invoices, receipts, forms, or notes.
- Prerequisites: Requires the standard setup:
openai,python-dotenvlibraries, API key, and an image file of the document to be processed (sample_invoice.pngas the placeholder). - Image Encoding: The
encode_image_to_base64function converts the local document image into the required format for the API. - Prompt Design for Extraction: The prompt is crucial for document processing. It explicitly asks the model to:
- Identify the document type.
- Extract a predefined list of specific fields (Vendor, Date, Total, Line Items, etc.). Requesting "Not Found" for missing fields encourages structured output.
- Provide a summary.
- Including the filename and current timestamp provides context.
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel. - Sends the multi-part message with the text prompt and the base64 encoded document image.
- Uses
detail: "high"for the image, which can be beneficial for improving the accuracy of Optical Character Recognition (OCR) and understanding text within the document image, though it uses more tokens. - Sets
max_tokensto accommodate potentially lengthy extracted information, especially line items.
- Specifies the
- Response Handling: Prints the text response from GPT-4o, which should contain the identified document type and the extracted fields as requested by the prompt. Token usage is also displayed.
- Error Handling: Includes checks for API errors and file system issues, with specific hints for potential image processing problems.
- Use Case Relevance: This directly addresses the "Document Processing" use case. It showcases how GPT-4o vision can automate tasks like data entry from invoices/receipts, summarizing correspondence, or even interpreting handwritten notes, significantly streamlining workflows that involve processing visual documents.
For testing, use a clear image of a document. The accuracy of the extraction will depend on the image quality, the clarity of the document layout, and the text's legibility. Remember to replace "sample_invoice.png" with the path to your actual document image.
Visual Problem Detection
Visual Problem Detection is a sophisticated AI capability that revolutionizes how we identify and analyze visual issues across digital assets. This advanced technology leverages computer vision and machine learning algorithms to automatically scan and evaluate visual elements, detecting problems that might be missed by human reviewers. It systematically examines various aspects of visual content, finding inconsistencies, errors, and usability problems in:
- User interfaces: Detecting misaligned elements, broken layouts, inconsistent styling, and accessibility issues. This capability performs comprehensive analysis of UI elements, including:
- Button placement and interaction zones to ensure optimal user experience
- Form field alignment and validation to maintain visual harmony
- Navigation menu consistency across different pages and states
- Color contrast ratios for WCAG compliance and accessibility standards
- Interactive element spacing and touchpoint sizing for mobile compatibility
- Design mockups: Identifying spacing problems, color contrast issues, and deviations from design guidelines. The system performs detailed analysis including:
- Padding and margin measurements against established specifications
- Color scheme consistency checking across all design elements
- Typography hierarchy verification for readability and brand consistency
- Component library compliance and design system adherence
- Visual rhythm and balance assessment in layouts
- Visual layouts: Spotting typography errors, grid alignment problems, and responsive design breakdowns. This involves sophisticated analysis of:
- Font usage patterns across different content types and sections
- Text spacing and line height optimization for readability
- Grid system compliance across various viewport sizes
- Responsive behavior testing at standard breakpoints
- Layout consistency across different devices and orientations
This capability has become indispensable for quality assurance teams and designers in maintaining high standards across digital products. By implementing Visual Problem Detection:
- Teams can automate up to 80% of visual QA processes
- Detection accuracy reaches 95% for common visual issues
- Review cycles are reduced by an average of 60%
The technology significantly accelerates the review process by automatically flagging potential issues before they reach production. This proactive approach not only reduces the need for time-consuming manual inspection but also improves overall product quality by ensuring consistent visual standards across all digital assets. The result is faster development cycles, reduced costs, and higher-quality deliverables that meet both technical and aesthetic standards.
Example:
This code sends an image of a user interface (UI) mockup or a design screenshot to GPT-4o and prompts it to identify potential design flaws, usability issues, inconsistencies, and other visual problems.
Download a sample of the file “ui_mockup.png” https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code example showcases GPT-4o's capability for visual problem detection, particularly useful in UI/UX design reviews, quality assurance (QA), and identifying potential issues in visual layouts or mockups.
- Prerequisites: Standard setup involving
openai,python-dotenv, API key configuration, and an input image file representing a UI design or mockup (ui_mockup.pngas placeholder). - Image Encoding: The
encode_image_to_base64function is used to prepare the local image file for the API request. - Prompt Design for Review: The prompt is specifically structured to guide GPT-4o to act as a UI/UX reviewer. It asks the model to look for problems within defined categories common in design critiques:
- Layout & Alignment
- Typography
- Color & Contrast (mentioning accessibility/WCAG is key)
- Consistency
- Usability & Clarity
- General Design Principles
Crucially, it asks why something is an issue, prompting for justification beyond simple identification.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the detailed review prompt and the base64 encoded UI image.
- Uses
detail: "high"for the image, potentially improving the model's ability to perceive subtle visual details like slight misalignments or text rendering issues. - Sets
max_tokensto allow for a comprehensive list of potential issues and explanations.
- Targets the
- Response Handling: Prints the textual response from GPT-4o, which should contain a structured list of identified visual problems based on the prompt categories. Token usage is also provided.
- Error Handling: Includes standard checks for API errors and file system issues.
- Use Case Relevance: This directly addresses the "Visual Problem Detection" use case. It demonstrates how AI can assist designers and developers by automatically scanning interfaces for common flaws, potentially speeding up the review process, catching issues early, and improving the overall quality and usability of digital products.
For effective testing, use an image of a UI that intentionally or unintentionally includes some design flaws. Remember to replace "ui_mockup.png" with the path to your actual image file.
1.3.3 Supported Use Cases for Vision in GPT-4o
GPT-4o's vision capabilities extend far beyond simple image recognition, offering a diverse range of applications that can transform how we interact with visual content. This section explores the various use cases where GPT-4o's visual understanding can be leveraged to create more intelligent and responsive applications.
From analyzing complex diagrams to providing detailed descriptions of images, GPT-4o's vision features enable developers to build solutions that bridge the gap between visual and textual understanding. These capabilities can be particularly valuable in fields such as education, accessibility, content moderation, and automated analysis.
Let's explore the key use cases where GPT-4o's vision capabilities shine, along with practical examples and implementation strategies that demonstrate its versatility in real-world applications.
| Use Case | Example | Explanation |
| Image captioning | "Describe this image in detail." | Converts visual content into detailed textual descriptions, useful for content cataloging, accessibility, and automated image indexing. |
| UI analysis | "Are there any visual bugs in this webpage screenshot?" | Examines user interfaces for design inconsistencies, alignment issues, and usability problems, helping streamline QA processes. |
| Document reading | "Extract the invoice number and date from this scan." | Processes scanned documents to extract specific information, automating data entry and document processing workflows. |
| Data visualization interpretation | "Summarize this pie chart in plain English." | Translates complex visual data representations into clear, narrative descriptions, making data more accessible to all users. |
| Educational Q&A | "What is this geometric figure? What are its properties?" | Provides interactive learning support by analyzing and explaining visual educational content, helping students understand complex concepts. |
| Accessibility support | "Read aloud the contents of this image." | Enhances digital accessibility by providing detailed descriptions of visual content for users with visual impairments. |
1.3.4 Best Practices for Vision Prompts
Crafting effective prompts for vision-enabled AI models requires a different approach compared to text-only interactions. While the fundamental principles of clear communication remain important, visual prompts need to account for the spatial, contextual, and multi-modal nature of image analysis. This section explores key strategies and best practices to help you create more effective vision-based prompts that maximize GPT-4o's visual understanding capabilities.
Whether you're building applications for image analysis, document processing, or visual QA, understanding these best practices will help you:
- Get more accurate and relevant responses from the model
- Reduce ambiguity in your requests
- Structure your prompts for complex visual analysis tasks
- Optimize the interaction between textual and visual elements
Let's explore the core principles that will help you craft more effective vision-based prompts:
Be direct with your request:
Example 1 (Ineffective Prompt):
"What are the main features in this room?"
This prompt has several issues:
- It's overly broad and unfocused
- Lacks specific criteria for what constitutes a "main feature"
- May result in inconsistent or superficial responses
- Doesn't guide the AI toward any particular aspect of analysis
Example 2 (Effective Prompt):
"Identify all electronic devices in this living room and describe their position."
This prompt is superior because:
- Clearly defines what to look for (electronic devices)
- Specifies the scope (living room)
- Requests specific information (position/location)
- Will generate structured, actionable information
- Makes it easier to verify if the AI missed anything
The key difference is that the second prompt provides clear parameters for analysis and a specific type of output, making it much more likely to receive useful, relevant information that serves your intended purpose.
Combine with text when needed
A standalone image may be enough for basic captioning, but combining it with a well-crafted prompt significantly enhances the model's analytical capabilities and output precision. The key is to provide clear, specific context that guides the model's attention to the aspects most relevant to your needs.
For example, instead of just uploading an image, add detailed contextual prompts like:
- "Analyze this architectural drawing focusing on potential safety hazards, particularly in stairwell and exit areas"
- "Review this graph and explain the trend between 2020-2023, highlighting any seasonal patterns and anomalies"
- "Examine this UI mockup and identify accessibility issues for users with visual impairments"
This approach offers several advantages:
- Focuses the model's analysis on specific features or concerns
- Reduces irrelevant or superficial observations
- Ensures more consistent and structured responses
- Allows for deeper, more nuanced analysis of complex visual elements
- Helps generate more actionable insights and recommendations
The combination of visual input with precise textual guidance helps the model understand exactly what aspects of the image are most important for your use case, resulting in more valuable and targeted responses.
Use structured follow-ups
After completing an initial visual analysis, you can leverage the conversation thread to conduct a more thorough investigation through structured follow-up questions. This approach allows you to build upon the model's initial observations and extract more detailed, specific information. Follow-up questions help create a more interactive and comprehensive analysis process.
Here's how to effectively use structured follow-ups:
- Drill down into specific details
- Example: "Can you describe the lighting fixtures in more detail?"
- This helps focus the model's attention on particular elements that need closer examination
- Useful for technical analysis or detailed documentation
- Compare elements
- Example: "How does the layout of room A compare to room B?"
- Enables systematic comparison of different components or areas
- Helps identify patterns, inconsistencies, or relationships
- Get recommendations
- Example: "Based on this floor plan, what improvements would you suggest?"
- Leverages the model's understanding to generate practical insights
- Can lead to actionable feedback for improvement
By using structured follow-ups, you create a more dynamic interaction that can uncover deeper insights and more nuanced understanding of the visual content you're analyzing.
1.3.5 Multi-Image Input
You can pass multiple images in a single message if your use case requires cross-image comparison. This powerful feature allows you to analyze relationships between images, compare different versions of designs, or evaluate changes over time. The model processes all images simultaneously, enabling sophisticated multi-image analysis that would typically require multiple separate requests.
Here's what you can do with multi-image input:
- Compare Design Iterations
- Analyze UI/UX changes across versions
- Track progression of design implementations
- Identify consistency across different screens
- Document Analysis
- Compare multiple versions of documents
- Cross-reference related paperwork
- Verify document authenticity
- Time-Based Analysis
- Review before-and-after scenarios
- Track changes in visual data over time
- Monitor progress in visual projects
The model processes these images contextually, understanding their relationships and providing comprehensive analysis. It can identify patterns, inconsistencies, improvements, and relationships across all provided images, offering detailed insights that would be difficult to obtain through single-image analysis.
Example:
This code sends two images (e.g., two versions of a UI mockup) along with a text prompt in a single API call, asking the model to compare them and identify differences.
Download a sample of the file “image_path_1.png” https://files.cuantum.tech/images/image_path_1.png
Download a sample of the file “image_path_2.png” https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Code breakdown:
- Context: This code demonstrates GPT-4o's multi-image input capability, allowing users to send multiple images within a single API request for tasks like comparison, relationship analysis, or synthesis of information across visuals. The example focuses on comparing two UI mockups to identify differences.
- Prerequisites: Requires the standard setup (
openai,python-dotenv, API key) but specifically needs two input image files for the comparison task (ui_mockup_v1.pngandui_mockup_v2.pngused as placeholders). - Image Encoding: The
encode_image_to_base64function is used twice, once for each input image. Error handling ensures both images are processed correctly before proceeding. - API Request Structure: The key difference lies in the
messages[0]["content"]list. It now contains:- One dictionary of
type: "text"for the prompt. - Multiple dictionaries of
type: "image_url", one for each image being sent. The images are included sequentially after the text prompt.
- One dictionary of
- Prompt Design for Multi-Image Tasks: The prompt explicitly refers to the two images (e.g., "the first image," "the second image," or by filename as done here) and clearly states the task involving both images (e.g., "Compare Version 1 and Version 2," "list the differences").
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel, which supports multi-image inputs. - Sends the structured
messageslist containing the text prompt and multiple base64 encoded images. - Sets
max_tokensappropriate for the expected output (a list of differences).
- Specifies the
- Response Handling: Prints the textual response from GPT-4o, which should contain the comparison results based on the prompt and the two images provided. Token usage reflects the processing of the text and all images.
- Error Handling: Includes standard checks, emphasizing potential issues with either of the image files.
- Use Case Relevance: This directly addresses the "Multi-Image Input" capability. It's useful for version comparison (designs, documents), analyzing sequences (before/after shots), combining information from different visual sources (e.g., product shots + size chart), or any task where understanding the relationship or differences between multiple images is required.
Remember to provide two distinct image files (e.g., two different versions of a UI mockup) when testing this code, and update the image_path_1 and image_path_2 variables accordingly.
1.3.6 Privacy & Security
As AI systems increasingly process and analyze visual data, understanding the privacy and security implications becomes paramount. This section explores the critical aspects of protecting image data when working with vision-enabled AI models, covering everything from basic security protocols to best practices for responsible data handling.
We'll examine the technical security measures in place, data management strategies, and essential privacy considerations that developers must address when building applications that process user-submitted images. Understanding these principles is crucial for maintaining user trust and ensuring compliance with data protection regulations.
Key areas we'll cover include:
- Security protocols for image data transmission and storage
- Best practices for managing user-submitted visual content
- Privacy considerations and compliance requirements
- Implementation strategies for secure image processing
Let's explore in detail the comprehensive security measures and privacy considerations that are essential for protecting visual data:
- Secure Image Upload and API Authentication:
- Image data is protected through advanced encryption during transit using industry-standard TLS protocols, ensuring end-to-end security
- A robust authentication system ensures that access is strictly limited to requests verified with your specific API credentials, preventing unauthorized access
- The system implements strict isolation - images associated with your API key remain completely separate and inaccessible to other users or API keys, maintaining data sovereignty
- Effective Image Data Management Strategies:
- The platform provides a straightforward method to remove unnecessary files using
openai.files.delete(file_id), giving you complete control over data retention - Best practices include implementing automated cleanup systems that regularly remove temporary image uploads, reducing security risks and storage overhead
- Regular systematic audits of stored files are crucial for maintaining optimal data organization and security compliance
- The platform provides a straightforward method to remove unnecessary files using
- Comprehensive User Privacy Protection:
- Implement explicit user consent mechanisms before any image analysis begins, ensuring transparency and trust
- Develop and integrate clear consent workflows within your application that inform users about how their images will be processed
- Create detailed privacy policies that explicitly outline image processing procedures, usage limitations, and data protection measures
- Establish and clearly communicate specific data retention policies, including how long images are stored and when they are automatically deleted
Summary
In this section, you've gained comprehensive insights into GPT-4o's groundbreaking vision capabilities, which fundamentally transform how AI systems process and understand visual content. This revolutionary feature goes well beyond traditional text processing, enabling AI to perform detailed image analysis with human-like understanding. Through advanced neural networks and sophisticated computer vision algorithms, the system can identify objects, interpret scenes, understand context, and even recognize subtle details within images. With remarkable efficiency and ease of implementation, you can leverage these powerful capabilities through a streamlined API that processes both images and natural language commands simultaneously.
This breakthrough technology represents a paradigm shift in AI applications, opening up an extensive range of practical implementations across numerous domains:
- Education: Create dynamic, interactive learning experiences with visual explanations and automated image-based tutoring
- Generate custom visual aids for complex concepts
- Provide real-time feedback on student drawings or diagrams
- Accessibility: Develop sophisticated tools that provide detailed image descriptions for visually impaired users
- Generate contextual descriptions of images with relevant details
- Create audio narratives from visual content
- Analysis: Perform sophisticated visual data analysis for business intelligence and research
- Extract insights from charts, graphs, and technical diagrams
- Analyze trends in visual data across large datasets
- Automation: Streamline workflows with automated image processing and categorization
- Automatically sort and tag visual content
- Process documents with mixed text and image content
Throughout this comprehensive exploration, you've mastered several essential capabilities that form the foundation of visual AI implementation:
- Upload and interpret images: Master the technical foundations of integrating the API into your applications, including proper image formatting, efficient upload procedures, and understanding the various parameters that affect interpretation accuracy. Learn to receive and parse detailed, context-aware interpretations that can drive downstream processing.
- Use multimodal prompts with text + image: Develop expertise in crafting effective prompts that seamlessly combine textual instructions with visual inputs. Understand how to structure queries that leverage both modalities for enhanced accuracy and more nuanced results. Learn advanced prompting techniques that can guide the AI's attention to specific aspects of images.
- Build assistants that see before they speak: Create sophisticated AI applications that process visual information as a fundamental part of their decision-making process. Learn to develop systems that can understand context from both visual and textual inputs, leading to more intelligent, natural, and context-aware interactions that truly bridge the gap between human and machine understanding.
1.3 Vision Output Capabilities in GPT-4o
With the release of GPT-4o, OpenAI achieved a significant breakthrough in artificial intelligence by introducing native multimodal vision support. This revolutionary capability enables the model to simultaneously process both visual and textual information, effectively allowing it to interpret, analyze, and reason about images with the same sophistication it applies to text processing. The model's visual understanding is comprehensive and versatile, capable of:
- Detailed Image Analysis: Converting visual content into natural language descriptions, identifying objects, colors, patterns, and spatial relationships.
- Technical Interpretation: Processing complex visualizations like charts, graphs, and diagrams, extracting meaningful insights and trends.
- Document Processing: Reading and understanding various document formats, from handwritten notes to structured forms and technical drawings.
- Visual Problem Detection: Identifying issues in user interfaces, design mockups, and visual layouts, making it valuable for quality assurance and design review processes.
In this section, you'll gain practical knowledge about integrating GPT-4o's visual capabilities into your applications. We'll cover the technical aspects of submitting images as input, exploring both structured data extraction and natural-language processing approaches. You'll learn to implement real-world applications such as:
- Interactive Visual Q&A systems that can answer questions about image content
Automated form processing solutions for document management
Advanced object recognition systems for various industries
Accessibility tools that can describe images for visually impaired users
1.3.1 What Is GPT-4o Vision?
GPT-4o ("o" for "omni") represents a revolutionary leap in artificial intelligence technology by achieving seamless integration of language and visual processing capabilities within a single, unified model. This integration is particularly groundbreaking because it mirrors the human brain's natural ability to process multiple types of information simultaneously. Just as humans can effortlessly combine visual cues with verbal information to understand their environment, GPT-4o can process and interpret both text and images in a unified, intelligent manner.
The technical architecture of GPT-4o represents a significant departure from traditional AI models. Earlier systems typically required a complex chain of separate models - one for image processing, another for text analysis, and additional components to bridge these separate systems. These older approaches not only were computationally intensive but also often resulted in information loss between processing steps. GPT-4o eliminates these inefficiencies by handling all processing within a single, streamlined system. Users can now submit both images and text through a simple API call, making the technology more accessible and easier to implement.
What truly sets GPT-4o apart is its sophisticated neural architecture that enables true multimodal understanding. Rather than treating text and images as separate inputs that are processed independently, the model creates a unified semantic space where visual and textual information can interact and inform each other.
This means that when analyzing a chart, for example, GPT-4o doesn't just perform optical character recognition or basic pattern recognition - it actually understands the relationship between visual elements, numerical data, and textual context. This deep integration allows it to provide nuanced, context-aware responses that draw from both the visual and textual elements of the input, much like a human expert would do when analyzing complex information.
Key Requirements for Vision Integration
- Model Selection: GPT-4o must be explicitly specified as your model choice. This is crucial as earlier GPT versions do not support vision capabilities. The 'o' designation indicates the omni-modal version with visual processing abilities. When implementing vision features, ensuring you're using GPT-4o is essential for accessing the full range of visual analysis capabilities and achieving optimal performance.
- Image Upload Process: Your implementation must properly handle image file uploads through OpenAI's dedicated image upload endpoint. This involves:
- Converting the image to an appropriate format: Ensure images are in supported formats (PNG, JPEG) and meet size limitations. The system accepts images up to 20MB in size.
- Generating a secure file handle: The API creates a unique identifier for each uploaded image, allowing secure reference in subsequent API calls while maintaining data privacy.
- Properly managing the uploaded file's lifecycle: Implement proper cleanup procedures to delete uploaded files when they're no longer needed, helping maintain system efficiency and security.
- Prompt Engineering: While the model can process images independently, combining them with well-crafted text prompts often yields better results. You can:
- Ask specific questions about the image: Frame precise queries that target the exact information you need, such as "What color is the car in the foreground?" or "How many people are wearing hats?"
- Request particular types of analysis: Specify the kind of analysis needed, whether it's technical (measuring, counting), descriptive (colors, shapes), or interpretative (emotions, style).
- Guide the model's attention to specific aspects or regions: Direct the model to focus on particular areas or elements within the image for more detailed analysis, such as "Look at the top-right corner" or "Focus on the text in the center."
Example: Analyze a Chart from an Image
Let’s walk through how to send an image (e.g., a bar chart or screenshot) to GPT-4o and ask it a specific question.
Step-by-Step Python Example
Step 1: Upload the Image to OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Let's break down this code:
1. Import Statements
openai: Main library for OpenAI API interactionos: For environment variable handlingdotenv: Loads environment variables from a .env file
2. Environment Setup
- Loads environment variables using
load_dotenv() - Sets the OpenAI API key from environment variables for authentication
3. Image Upload
- Creates a new file upload using
openai.files.create() - Opens 'sales_chart.png' in binary read mode (
'rb') - Specifies the purpose as "vision" for image processing
This code represents the first step in using GPT-4o's vision capabilities, which is necessary before you can analyze images with the model. The image file handle returned by this upload can then be used in subsequent API calls.
Step 2: Send Image + Text Prompt to GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Let's break down this code:
1. API Call Structure:
- Uses OpenAI's ChatCompletion.create() method
- Specifies "gpt-4o" as the model, which is required for vision capabilities
2. Message Format:
- Creates a message array with a single user message
- The content is an array containing two elements:
- A text element with the prompt requesting chart analysis
- An image_url element referencing the previously uploaded file
3. Parameters:
- Sets max_tokens to 300 to limit response length
- Uses the file ID from a previous upload step
4. Output Handling:
- Prints "GPT-4o Vision Response:"
- Extracts and displays the model's response from the choices array
This code demonstrates how to combine both text and image inputs in a single prompt, allowing GPT-4o to analyze visual content and provide insights based on the specific question asked.
In this example, you're sending both a text prompt and an image in the same message. GPT-4o analyzes the visual input and combines it with your instructions.
1.3.2 Uses Cases for Vision in GPT-4o
GPT-4o's vision capabilities open up a wide range of practical applications across various industries and use cases. From enhancing accessibility to automating complex visual analysis tasks, the model's ability to understand and interpret images has transformed how we interact with visual data. This section explores the diverse applications of GPT-4o's vision capabilities, demonstrating how organizations and developers can leverage this technology to solve real-world problems and create innovative solutions.
By examining specific use cases and implementation examples, we'll see how GPT-4o's visual understanding capabilities can be applied to tasks ranging from simple image description to complex technical analysis. These applications showcase the versatility of the model and its potential to revolutionize workflows in fields such as healthcare, education, design, and technical documentation.
Detailed Image Analysis
Converting visual content into natural language descriptions is one of GPT-4o's most powerful and sophisticated capabilities. The model demonstrates remarkable ability in comprehensive scene analysis, methodically deconstructing images into their fundamental components with exceptional accuracy and detail. Through advanced neural processing, it can perform multiple levels of analysis simultaneously:
- Identify individual objects and their characteristics - from simple elements like shape and size to complex features like brand names, conditions, and specific variations of objects
- Describe spatial relationships between elements - precisely analyzing how objects are positioned relative to each other, including depth perception, overlapping, and hierarchical arrangements in three-dimensional space
- Recognize colors, textures, and patterns with high accuracy - distinguishing between subtle shade variations, complex material properties, and intricate pattern repetitions or irregularities
- Detect subtle visual details that might be missed by conventional computer vision systems - including shadows, reflections, partial occlusions, and environmental effects that affect the appearance of objects
- Understand contextual relationships between objects in a scene - interpreting how different elements interact with each other, their likely purpose or function, and the overall context of the environment
These sophisticated capabilities enable a wide range of practical applications. In automated image cataloging, the system can create detailed, searchable descriptions of large image databases. For visually impaired users, it provides rich, contextual descriptions that paint a complete picture of the visual scene. The model's versatility extends to processing various types of visual content:
- Product photos - detailed descriptions of features, materials, and design elements
- Architectural drawings - interpretation of technical details, measurements, and spatial relationships
- Natural scenes - comprehensive analysis of landscapes, weather conditions, and environmental features
- Social situations - understanding of human interactions, expressions, and body language
This capability enables applications ranging from automated image cataloging to detailed scene description for visually impaired users. The model can process everything from simple product photos to complex architectural drawings, providing rich, contextual descriptions that capture both obvious and nuanced visual elements.
Example: Interactive Visual Q&A systems
This code will send an image (from a local file) and a multi-part prompt to the GPT-4o model to showcase these different analysis types in a single response.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's ability to perform detailed image analysis, combining several use cases discussed: generating accessibility descriptions, recognizing objects, and answering contextual questions about the visual content.
- Prerequisites: Lists the necessary library (
openai,python-dotenv), how to handle the API key securely (using a.envfile), and the need for a sample image file. - Image Encoding: Includes a helper function
encode_image_to_base64to convert a local image file into the base64 data URI format required by the API when not using a direct public URL. It also performs basic file type checking. - API Client: Initializes the standard OpenAI client, loading the API key from environment variables. Includes error handling for missing keys or initialization issues.
- Multi-Modal Prompt: The core of the request is the
messagesstructure.- It contains a single user message.
- The
contentof this message is a list containing multiple parts:- A
textpart holding the instructions (the prompt asking for description, object list, and context). - An
image_urlpart. Crucially, theurlfield withinimage_urlis set to thedata:[media_type];base64,[encoded_string]URI generated by the helper function. Thedetailparameter can be adjusted (low,high,auto) to influence the analysis depth and token cost.
- A
- API Call (
client.chat.completions.create):- Specifies
model="gpt-4o". - Passes the structured
messageslist. - Sets
max_tokensto control the response length.
- Specifies
- Response Handling: Extracts the text content from the
choices[0].message.contentfield of the API response and prints it. It also shows how to access token usage information. - Error Handling: Includes
try...exceptblocks for API errors (OpenAIError) and general exceptions, providing hints for common issues like content policy flags or invalid images. - Demonstrated Capabilities: This single API call effectively showcases:
- Accessibility: The model generates a textual description suitable for screen readers.
- Object Recognition: It identifies and lists objects present in the image.
- Visual Q&A/Inference: It answers questions about the context and potential activities based on visual evidence.
This example provides a practical and comprehensive demonstration of GPT-4o's vision capabilities for detailed image understanding within the context of your book chapter. Remember to replace "sample_scene.jpg" with an actual image file for testing.
Technical Interpretation and Data Analysis
Processing complex visualizations like charts, graphs, and diagrams requires sophisticated understanding to extract meaningful insights and trends. The system demonstrates remarkable capabilities in translating visual data into actionable information.
This includes the ability to:
- Analyze quantitative data presented in various chart formats (bar charts, line graphs, scatter plots) and identify key patterns, outliers, and correlations. For example, it can detect seasonal trends in line graphs, spot unusual data points in scatter plots, and compare proportions in bar charts.
- Interpret complex technical diagrams such as architectural blueprints, engineering schematics, and scientific illustrations with precise detail. This includes understanding scale drawings, electrical circuit diagrams, molecular structures, and mechanical assembly instructions.
- Extract numerical values, labels, and legends from visualizations while maintaining contextual accuracy. The system can read and interpret axes labels, data point values, legend entries, and footnotes, ensuring all quantitative information is accurately captured.
- Compare multiple data points or trends across different time periods or categories to provide comprehensive analytical insights. This includes year-over-year comparisons, cross-category analysis, and multi-variable trend identification.
- Translate visual statistical information into clear, written explanations that non-technical users can understand, breaking down complex data relationships into accessible language while preserving the accuracy of the underlying information.
Example:
This code will send an image file (e.g., a bar chart) and specific prompts to GPT-4o, asking it to identify the chart type, understand the data presented, and extract key insights or trends.
Download a sample of the file “sales_chart.png” https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability for technical interpretation, specifically analyzing visual data representations like charts and graphs. Instead of just describing the image, the goal is to extract meaningful insights and understand the data presented.
- Prerequisites: Similar setup requirements:
openai,python-dotenvlibraries, API key in.env, and importantly, an image file containing a chart or graph (sales_chart.pngused as placeholder). - Image Encoding: Uses the same
encode_image_to_base64function to prepare the local image file for the API. - Prompt Design for Interpretation: The prompt is carefully crafted to guide GPT-4o towards analysis rather than simple description. It asks specific questions about:
- Chart Type: Basic identification.
- Data Representation: Understanding axes, units, and categories.
- Key Insights & Trends: The core analytical task – summarizing patterns, highs/lows.
- Specific Data Points: Testing the ability to read approximate values from the chart.
- Overall Summary: A concise takeaway message.
- Contextual Information: Includes the current date and filename for reference within the prompt.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the analytical text prompt and the base64 encoded chart image.
- Sets
detailto"high"in theimage_urlpart, suggesting to the model to use more resources for a potentially more accurate analysis of the visual details in the chart (this may increase token cost). - Allocates potentially more
max_tokens(e.g., 700) anticipating a more detailed analytical response compared to a simple description.
- Targets the
- Response Handling: Extracts and prints the textual analysis provided by GPT-4o. Includes token usage details.
- Error Handling: Standard checks for API errors and file issues.
- Use Case Relevance: This directly addresses the "Technical Interpretation" use case by showing how GPT-4o can process complex visualizations, extract data points, identify trends, and provide summaries, turning visual data into actionable insights. This is valuable for data analysis workflows, report generation, and understanding technical documents.
Remember to use a clear, high-resolution image of a chart or graph for best results when testing this code. Replace "sales_chart.png" with the correct path to your image file.
Document Processing
GPT-4o demonstrates exceptional capabilities in processing and analyzing diverse document formats, serving as a comprehensive solution for document analysis and information extraction. This advanced system leverages sophisticated computer vision and natural language processing to handle an extensive range of document types with remarkable accuracy. Here's a detailed breakdown of its document processing capabilities:
- Handwritten Documents: The system excels at interpreting handwritten content across multiple styles and formats. It can:
- Accurately recognize different handwriting styles, from neat cursive to rushed scribbles
- Process both formal documents and informal notes with high accuracy
- Handle multiple languages and special characters in handwritten form
- Structured Forms: Demonstrates superior ability in processing standardized documentation with:
- Precise extraction of key data fields from complex forms
- Automatic organization of extracted information into structured formats
- Validation of data consistency across multiple form fields
- Technical Documentation: Shows advanced comprehension of specialized technical materials through:
- Detailed interpretation of complex technical notations and symbols
- Understanding of scale and dimensional information in drawings
- Recognition of industry-standard technical specifications and terminology
- Mixed-Format Documents: Demonstrates versatile processing capabilities by:
- Seamlessly integrating information from text, images, and graphical elements
- Maintaining context across different content types within the same document
- Processing complex layouts with multiple information hierarchies
- Legacy Documents: Offers sophisticated handling of historical materials by:
- Adapting to various levels of document degradation and aging
- Processing outdated formatting and typography styles
- Maintaining historical context while making content accessible in modern formats
Example:
This code will send an image of a document (like an invoice or receipt) to GPT-4o and prompt it to identify the document type and extract specific pieces of information, such as vendor name, date, total amount, and line items.
Download a sample of the file “sample_invoice.png” https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability in document processing, a key use case involving understanding and extracting information from images of documents like invoices, receipts, forms, or notes.
- Prerequisites: Requires the standard setup:
openai,python-dotenvlibraries, API key, and an image file of the document to be processed (sample_invoice.pngas the placeholder). - Image Encoding: The
encode_image_to_base64function converts the local document image into the required format for the API. - Prompt Design for Extraction: The prompt is crucial for document processing. It explicitly asks the model to:
- Identify the document type.
- Extract a predefined list of specific fields (Vendor, Date, Total, Line Items, etc.). Requesting "Not Found" for missing fields encourages structured output.
- Provide a summary.
- Including the filename and current timestamp provides context.
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel. - Sends the multi-part message with the text prompt and the base64 encoded document image.
- Uses
detail: "high"for the image, which can be beneficial for improving the accuracy of Optical Character Recognition (OCR) and understanding text within the document image, though it uses more tokens. - Sets
max_tokensto accommodate potentially lengthy extracted information, especially line items.
- Specifies the
- Response Handling: Prints the text response from GPT-4o, which should contain the identified document type and the extracted fields as requested by the prompt. Token usage is also displayed.
- Error Handling: Includes checks for API errors and file system issues, with specific hints for potential image processing problems.
- Use Case Relevance: This directly addresses the "Document Processing" use case. It showcases how GPT-4o vision can automate tasks like data entry from invoices/receipts, summarizing correspondence, or even interpreting handwritten notes, significantly streamlining workflows that involve processing visual documents.
For testing, use a clear image of a document. The accuracy of the extraction will depend on the image quality, the clarity of the document layout, and the text's legibility. Remember to replace "sample_invoice.png" with the path to your actual document image.
Visual Problem Detection
Visual Problem Detection is a sophisticated AI capability that revolutionizes how we identify and analyze visual issues across digital assets. This advanced technology leverages computer vision and machine learning algorithms to automatically scan and evaluate visual elements, detecting problems that might be missed by human reviewers. It systematically examines various aspects of visual content, finding inconsistencies, errors, and usability problems in:
- User interfaces: Detecting misaligned elements, broken layouts, inconsistent styling, and accessibility issues. This capability performs comprehensive analysis of UI elements, including:
- Button placement and interaction zones to ensure optimal user experience
- Form field alignment and validation to maintain visual harmony
- Navigation menu consistency across different pages and states
- Color contrast ratios for WCAG compliance and accessibility standards
- Interactive element spacing and touchpoint sizing for mobile compatibility
- Design mockups: Identifying spacing problems, color contrast issues, and deviations from design guidelines. The system performs detailed analysis including:
- Padding and margin measurements against established specifications
- Color scheme consistency checking across all design elements
- Typography hierarchy verification for readability and brand consistency
- Component library compliance and design system adherence
- Visual rhythm and balance assessment in layouts
- Visual layouts: Spotting typography errors, grid alignment problems, and responsive design breakdowns. This involves sophisticated analysis of:
- Font usage patterns across different content types and sections
- Text spacing and line height optimization for readability
- Grid system compliance across various viewport sizes
- Responsive behavior testing at standard breakpoints
- Layout consistency across different devices and orientations
This capability has become indispensable for quality assurance teams and designers in maintaining high standards across digital products. By implementing Visual Problem Detection:
- Teams can automate up to 80% of visual QA processes
- Detection accuracy reaches 95% for common visual issues
- Review cycles are reduced by an average of 60%
The technology significantly accelerates the review process by automatically flagging potential issues before they reach production. This proactive approach not only reduces the need for time-consuming manual inspection but also improves overall product quality by ensuring consistent visual standards across all digital assets. The result is faster development cycles, reduced costs, and higher-quality deliverables that meet both technical and aesthetic standards.
Example:
This code sends an image of a user interface (UI) mockup or a design screenshot to GPT-4o and prompts it to identify potential design flaws, usability issues, inconsistencies, and other visual problems.
Download a sample of the file “ui_mockup.png” https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code example showcases GPT-4o's capability for visual problem detection, particularly useful in UI/UX design reviews, quality assurance (QA), and identifying potential issues in visual layouts or mockups.
- Prerequisites: Standard setup involving
openai,python-dotenv, API key configuration, and an input image file representing a UI design or mockup (ui_mockup.pngas placeholder). - Image Encoding: The
encode_image_to_base64function is used to prepare the local image file for the API request. - Prompt Design for Review: The prompt is specifically structured to guide GPT-4o to act as a UI/UX reviewer. It asks the model to look for problems within defined categories common in design critiques:
- Layout & Alignment
- Typography
- Color & Contrast (mentioning accessibility/WCAG is key)
- Consistency
- Usability & Clarity
- General Design Principles
Crucially, it asks why something is an issue, prompting for justification beyond simple identification.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the detailed review prompt and the base64 encoded UI image.
- Uses
detail: "high"for the image, potentially improving the model's ability to perceive subtle visual details like slight misalignments or text rendering issues. - Sets
max_tokensto allow for a comprehensive list of potential issues and explanations.
- Targets the
- Response Handling: Prints the textual response from GPT-4o, which should contain a structured list of identified visual problems based on the prompt categories. Token usage is also provided.
- Error Handling: Includes standard checks for API errors and file system issues.
- Use Case Relevance: This directly addresses the "Visual Problem Detection" use case. It demonstrates how AI can assist designers and developers by automatically scanning interfaces for common flaws, potentially speeding up the review process, catching issues early, and improving the overall quality and usability of digital products.
For effective testing, use an image of a UI that intentionally or unintentionally includes some design flaws. Remember to replace "ui_mockup.png" with the path to your actual image file.
1.3.3 Supported Use Cases for Vision in GPT-4o
GPT-4o's vision capabilities extend far beyond simple image recognition, offering a diverse range of applications that can transform how we interact with visual content. This section explores the various use cases where GPT-4o's visual understanding can be leveraged to create more intelligent and responsive applications.
From analyzing complex diagrams to providing detailed descriptions of images, GPT-4o's vision features enable developers to build solutions that bridge the gap between visual and textual understanding. These capabilities can be particularly valuable in fields such as education, accessibility, content moderation, and automated analysis.
Let's explore the key use cases where GPT-4o's vision capabilities shine, along with practical examples and implementation strategies that demonstrate its versatility in real-world applications.
| Use Case | Example | Explanation |
| Image captioning | "Describe this image in detail." | Converts visual content into detailed textual descriptions, useful for content cataloging, accessibility, and automated image indexing. |
| UI analysis | "Are there any visual bugs in this webpage screenshot?" | Examines user interfaces for design inconsistencies, alignment issues, and usability problems, helping streamline QA processes. |
| Document reading | "Extract the invoice number and date from this scan." | Processes scanned documents to extract specific information, automating data entry and document processing workflows. |
| Data visualization interpretation | "Summarize this pie chart in plain English." | Translates complex visual data representations into clear, narrative descriptions, making data more accessible to all users. |
| Educational Q&A | "What is this geometric figure? What are its properties?" | Provides interactive learning support by analyzing and explaining visual educational content, helping students understand complex concepts. |
| Accessibility support | "Read aloud the contents of this image." | Enhances digital accessibility by providing detailed descriptions of visual content for users with visual impairments. |
1.3.4 Best Practices for Vision Prompts
Crafting effective prompts for vision-enabled AI models requires a different approach compared to text-only interactions. While the fundamental principles of clear communication remain important, visual prompts need to account for the spatial, contextual, and multi-modal nature of image analysis. This section explores key strategies and best practices to help you create more effective vision-based prompts that maximize GPT-4o's visual understanding capabilities.
Whether you're building applications for image analysis, document processing, or visual QA, understanding these best practices will help you:
- Get more accurate and relevant responses from the model
- Reduce ambiguity in your requests
- Structure your prompts for complex visual analysis tasks
- Optimize the interaction between textual and visual elements
Let's explore the core principles that will help you craft more effective vision-based prompts:
Be direct with your request:
Example 1 (Ineffective Prompt):
"What are the main features in this room?"
This prompt has several issues:
- It's overly broad and unfocused
- Lacks specific criteria for what constitutes a "main feature"
- May result in inconsistent or superficial responses
- Doesn't guide the AI toward any particular aspect of analysis
Example 2 (Effective Prompt):
"Identify all electronic devices in this living room and describe their position."
This prompt is superior because:
- Clearly defines what to look for (electronic devices)
- Specifies the scope (living room)
- Requests specific information (position/location)
- Will generate structured, actionable information
- Makes it easier to verify if the AI missed anything
The key difference is that the second prompt provides clear parameters for analysis and a specific type of output, making it much more likely to receive useful, relevant information that serves your intended purpose.
Combine with text when needed
A standalone image may be enough for basic captioning, but combining it with a well-crafted prompt significantly enhances the model's analytical capabilities and output precision. The key is to provide clear, specific context that guides the model's attention to the aspects most relevant to your needs.
For example, instead of just uploading an image, add detailed contextual prompts like:
- "Analyze this architectural drawing focusing on potential safety hazards, particularly in stairwell and exit areas"
- "Review this graph and explain the trend between 2020-2023, highlighting any seasonal patterns and anomalies"
- "Examine this UI mockup and identify accessibility issues for users with visual impairments"
This approach offers several advantages:
- Focuses the model's analysis on specific features or concerns
- Reduces irrelevant or superficial observations
- Ensures more consistent and structured responses
- Allows for deeper, more nuanced analysis of complex visual elements
- Helps generate more actionable insights and recommendations
The combination of visual input with precise textual guidance helps the model understand exactly what aspects of the image are most important for your use case, resulting in more valuable and targeted responses.
Use structured follow-ups
After completing an initial visual analysis, you can leverage the conversation thread to conduct a more thorough investigation through structured follow-up questions. This approach allows you to build upon the model's initial observations and extract more detailed, specific information. Follow-up questions help create a more interactive and comprehensive analysis process.
Here's how to effectively use structured follow-ups:
- Drill down into specific details
- Example: "Can you describe the lighting fixtures in more detail?"
- This helps focus the model's attention on particular elements that need closer examination
- Useful for technical analysis or detailed documentation
- Compare elements
- Example: "How does the layout of room A compare to room B?"
- Enables systematic comparison of different components or areas
- Helps identify patterns, inconsistencies, or relationships
- Get recommendations
- Example: "Based on this floor plan, what improvements would you suggest?"
- Leverages the model's understanding to generate practical insights
- Can lead to actionable feedback for improvement
By using structured follow-ups, you create a more dynamic interaction that can uncover deeper insights and more nuanced understanding of the visual content you're analyzing.
1.3.5 Multi-Image Input
You can pass multiple images in a single message if your use case requires cross-image comparison. This powerful feature allows you to analyze relationships between images, compare different versions of designs, or evaluate changes over time. The model processes all images simultaneously, enabling sophisticated multi-image analysis that would typically require multiple separate requests.
Here's what you can do with multi-image input:
- Compare Design Iterations
- Analyze UI/UX changes across versions
- Track progression of design implementations
- Identify consistency across different screens
- Document Analysis
- Compare multiple versions of documents
- Cross-reference related paperwork
- Verify document authenticity
- Time-Based Analysis
- Review before-and-after scenarios
- Track changes in visual data over time
- Monitor progress in visual projects
The model processes these images contextually, understanding their relationships and providing comprehensive analysis. It can identify patterns, inconsistencies, improvements, and relationships across all provided images, offering detailed insights that would be difficult to obtain through single-image analysis.
Example:
This code sends two images (e.g., two versions of a UI mockup) along with a text prompt in a single API call, asking the model to compare them and identify differences.
Download a sample of the file “image_path_1.png” https://files.cuantum.tech/images/image_path_1.png
Download a sample of the file “image_path_2.png” https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Code breakdown:
- Context: This code demonstrates GPT-4o's multi-image input capability, allowing users to send multiple images within a single API request for tasks like comparison, relationship analysis, or synthesis of information across visuals. The example focuses on comparing two UI mockups to identify differences.
- Prerequisites: Requires the standard setup (
openai,python-dotenv, API key) but specifically needs two input image files for the comparison task (ui_mockup_v1.pngandui_mockup_v2.pngused as placeholders). - Image Encoding: The
encode_image_to_base64function is used twice, once for each input image. Error handling ensures both images are processed correctly before proceeding. - API Request Structure: The key difference lies in the
messages[0]["content"]list. It now contains:- One dictionary of
type: "text"for the prompt. - Multiple dictionaries of
type: "image_url", one for each image being sent. The images are included sequentially after the text prompt.
- One dictionary of
- Prompt Design for Multi-Image Tasks: The prompt explicitly refers to the two images (e.g., "the first image," "the second image," or by filename as done here) and clearly states the task involving both images (e.g., "Compare Version 1 and Version 2," "list the differences").
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel, which supports multi-image inputs. - Sends the structured
messageslist containing the text prompt and multiple base64 encoded images. - Sets
max_tokensappropriate for the expected output (a list of differences).
- Specifies the
- Response Handling: Prints the textual response from GPT-4o, which should contain the comparison results based on the prompt and the two images provided. Token usage reflects the processing of the text and all images.
- Error Handling: Includes standard checks, emphasizing potential issues with either of the image files.
- Use Case Relevance: This directly addresses the "Multi-Image Input" capability. It's useful for version comparison (designs, documents), analyzing sequences (before/after shots), combining information from different visual sources (e.g., product shots + size chart), or any task where understanding the relationship or differences between multiple images is required.
Remember to provide two distinct image files (e.g., two different versions of a UI mockup) when testing this code, and update the image_path_1 and image_path_2 variables accordingly.
1.3.6 Privacy & Security
As AI systems increasingly process and analyze visual data, understanding the privacy and security implications becomes paramount. This section explores the critical aspects of protecting image data when working with vision-enabled AI models, covering everything from basic security protocols to best practices for responsible data handling.
We'll examine the technical security measures in place, data management strategies, and essential privacy considerations that developers must address when building applications that process user-submitted images. Understanding these principles is crucial for maintaining user trust and ensuring compliance with data protection regulations.
Key areas we'll cover include:
- Security protocols for image data transmission and storage
- Best practices for managing user-submitted visual content
- Privacy considerations and compliance requirements
- Implementation strategies for secure image processing
Let's explore in detail the comprehensive security measures and privacy considerations that are essential for protecting visual data:
- Secure Image Upload and API Authentication:
- Image data is protected through advanced encryption during transit using industry-standard TLS protocols, ensuring end-to-end security
- A robust authentication system ensures that access is strictly limited to requests verified with your specific API credentials, preventing unauthorized access
- The system implements strict isolation - images associated with your API key remain completely separate and inaccessible to other users or API keys, maintaining data sovereignty
- Effective Image Data Management Strategies:
- The platform provides a straightforward method to remove unnecessary files using
openai.files.delete(file_id), giving you complete control over data retention - Best practices include implementing automated cleanup systems that regularly remove temporary image uploads, reducing security risks and storage overhead
- Regular systematic audits of stored files are crucial for maintaining optimal data organization and security compliance
- The platform provides a straightforward method to remove unnecessary files using
- Comprehensive User Privacy Protection:
- Implement explicit user consent mechanisms before any image analysis begins, ensuring transparency and trust
- Develop and integrate clear consent workflows within your application that inform users about how their images will be processed
- Create detailed privacy policies that explicitly outline image processing procedures, usage limitations, and data protection measures
- Establish and clearly communicate specific data retention policies, including how long images are stored and when they are automatically deleted
Summary
In this section, you've gained comprehensive insights into GPT-4o's groundbreaking vision capabilities, which fundamentally transform how AI systems process and understand visual content. This revolutionary feature goes well beyond traditional text processing, enabling AI to perform detailed image analysis with human-like understanding. Through advanced neural networks and sophisticated computer vision algorithms, the system can identify objects, interpret scenes, understand context, and even recognize subtle details within images. With remarkable efficiency and ease of implementation, you can leverage these powerful capabilities through a streamlined API that processes both images and natural language commands simultaneously.
This breakthrough technology represents a paradigm shift in AI applications, opening up an extensive range of practical implementations across numerous domains:
- Education: Create dynamic, interactive learning experiences with visual explanations and automated image-based tutoring
- Generate custom visual aids for complex concepts
- Provide real-time feedback on student drawings or diagrams
- Accessibility: Develop sophisticated tools that provide detailed image descriptions for visually impaired users
- Generate contextual descriptions of images with relevant details
- Create audio narratives from visual content
- Analysis: Perform sophisticated visual data analysis for business intelligence and research
- Extract insights from charts, graphs, and technical diagrams
- Analyze trends in visual data across large datasets
- Automation: Streamline workflows with automated image processing and categorization
- Automatically sort and tag visual content
- Process documents with mixed text and image content
Throughout this comprehensive exploration, you've mastered several essential capabilities that form the foundation of visual AI implementation:
- Upload and interpret images: Master the technical foundations of integrating the API into your applications, including proper image formatting, efficient upload procedures, and understanding the various parameters that affect interpretation accuracy. Learn to receive and parse detailed, context-aware interpretations that can drive downstream processing.
- Use multimodal prompts with text + image: Develop expertise in crafting effective prompts that seamlessly combine textual instructions with visual inputs. Understand how to structure queries that leverage both modalities for enhanced accuracy and more nuanced results. Learn advanced prompting techniques that can guide the AI's attention to specific aspects of images.
- Build assistants that see before they speak: Create sophisticated AI applications that process visual information as a fundamental part of their decision-making process. Learn to develop systems that can understand context from both visual and textual inputs, leading to more intelligent, natural, and context-aware interactions that truly bridge the gap between human and machine understanding.
1.3 Vision Output Capabilities in GPT-4o
With the release of GPT-4o, OpenAI achieved a significant breakthrough in artificial intelligence by introducing native multimodal vision support. This revolutionary capability enables the model to simultaneously process both visual and textual information, effectively allowing it to interpret, analyze, and reason about images with the same sophistication it applies to text processing. The model's visual understanding is comprehensive and versatile, capable of:
- Detailed Image Analysis: Converting visual content into natural language descriptions, identifying objects, colors, patterns, and spatial relationships.
- Technical Interpretation: Processing complex visualizations like charts, graphs, and diagrams, extracting meaningful insights and trends.
- Document Processing: Reading and understanding various document formats, from handwritten notes to structured forms and technical drawings.
- Visual Problem Detection: Identifying issues in user interfaces, design mockups, and visual layouts, making it valuable for quality assurance and design review processes.
In this section, you'll gain practical knowledge about integrating GPT-4o's visual capabilities into your applications. We'll cover the technical aspects of submitting images as input, exploring both structured data extraction and natural-language processing approaches. You'll learn to implement real-world applications such as:
- Interactive Visual Q&A systems that can answer questions about image content
Automated form processing solutions for document management
Advanced object recognition systems for various industries
Accessibility tools that can describe images for visually impaired users
1.3.1 What Is GPT-4o Vision?
GPT-4o ("o" for "omni") represents a revolutionary leap in artificial intelligence technology by achieving seamless integration of language and visual processing capabilities within a single, unified model. This integration is particularly groundbreaking because it mirrors the human brain's natural ability to process multiple types of information simultaneously. Just as humans can effortlessly combine visual cues with verbal information to understand their environment, GPT-4o can process and interpret both text and images in a unified, intelligent manner.
The technical architecture of GPT-4o represents a significant departure from traditional AI models. Earlier systems typically required a complex chain of separate models - one for image processing, another for text analysis, and additional components to bridge these separate systems. These older approaches not only were computationally intensive but also often resulted in information loss between processing steps. GPT-4o eliminates these inefficiencies by handling all processing within a single, streamlined system. Users can now submit both images and text through a simple API call, making the technology more accessible and easier to implement.
What truly sets GPT-4o apart is its sophisticated neural architecture that enables true multimodal understanding. Rather than treating text and images as separate inputs that are processed independently, the model creates a unified semantic space where visual and textual information can interact and inform each other.
This means that when analyzing a chart, for example, GPT-4o doesn't just perform optical character recognition or basic pattern recognition - it actually understands the relationship between visual elements, numerical data, and textual context. This deep integration allows it to provide nuanced, context-aware responses that draw from both the visual and textual elements of the input, much like a human expert would do when analyzing complex information.
Key Requirements for Vision Integration
- Model Selection: GPT-4o must be explicitly specified as your model choice. This is crucial as earlier GPT versions do not support vision capabilities. The 'o' designation indicates the omni-modal version with visual processing abilities. When implementing vision features, ensuring you're using GPT-4o is essential for accessing the full range of visual analysis capabilities and achieving optimal performance.
- Image Upload Process: Your implementation must properly handle image file uploads through OpenAI's dedicated image upload endpoint. This involves:
- Converting the image to an appropriate format: Ensure images are in supported formats (PNG, JPEG) and meet size limitations. The system accepts images up to 20MB in size.
- Generating a secure file handle: The API creates a unique identifier for each uploaded image, allowing secure reference in subsequent API calls while maintaining data privacy.
- Properly managing the uploaded file's lifecycle: Implement proper cleanup procedures to delete uploaded files when they're no longer needed, helping maintain system efficiency and security.
- Prompt Engineering: While the model can process images independently, combining them with well-crafted text prompts often yields better results. You can:
- Ask specific questions about the image: Frame precise queries that target the exact information you need, such as "What color is the car in the foreground?" or "How many people are wearing hats?"
- Request particular types of analysis: Specify the kind of analysis needed, whether it's technical (measuring, counting), descriptive (colors, shapes), or interpretative (emotions, style).
- Guide the model's attention to specific aspects or regions: Direct the model to focus on particular areas or elements within the image for more detailed analysis, such as "Look at the top-right corner" or "Focus on the text in the center."
Example: Analyze a Chart from an Image
Let’s walk through how to send an image (e.g., a bar chart or screenshot) to GPT-4o and ask it a specific question.
Step-by-Step Python Example
Step 1: Upload the Image to OpenAI
import openai
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# Upload the image to OpenAI for vision processing
image_file = openai.files.create(
file=open("sales_chart.png", "rb"),
purpose="vision"
)Let's break down this code:
1. Import Statements
openai: Main library for OpenAI API interactionos: For environment variable handlingdotenv: Loads environment variables from a .env file
2. Environment Setup
- Loads environment variables using
load_dotenv() - Sets the OpenAI API key from environment variables for authentication
3. Image Upload
- Creates a new file upload using
openai.files.create() - Opens 'sales_chart.png' in binary read mode (
'rb') - Specifies the purpose as "vision" for image processing
This code represents the first step in using GPT-4o's vision capabilities, which is necessary before you can analyze images with the model. The image file handle returned by this upload can then be used in subsequent API calls.
Step 2: Send Image + Text Prompt to GPT-4o
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please analyze this chart and summarize the key sales trends."},
{"type": "image_url", "image_url": {"url": f"file-{image_file.id}"}}
]
}
],
max_tokens=300
)
print("GPT-4o Vision Response:")
print(response["choices"][0]["message"]["content"])Let's break down this code:
1. API Call Structure:
- Uses OpenAI's ChatCompletion.create() method
- Specifies "gpt-4o" as the model, which is required for vision capabilities
2. Message Format:
- Creates a message array with a single user message
- The content is an array containing two elements:
- A text element with the prompt requesting chart analysis
- An image_url element referencing the previously uploaded file
3. Parameters:
- Sets max_tokens to 300 to limit response length
- Uses the file ID from a previous upload step
4. Output Handling:
- Prints "GPT-4o Vision Response:"
- Extracts and displays the model's response from the choices array
This code demonstrates how to combine both text and image inputs in a single prompt, allowing GPT-4o to analyze visual content and provide insights based on the specific question asked.
In this example, you're sending both a text prompt and an image in the same message. GPT-4o analyzes the visual input and combines it with your instructions.
1.3.2 Uses Cases for Vision in GPT-4o
GPT-4o's vision capabilities open up a wide range of practical applications across various industries and use cases. From enhancing accessibility to automating complex visual analysis tasks, the model's ability to understand and interpret images has transformed how we interact with visual data. This section explores the diverse applications of GPT-4o's vision capabilities, demonstrating how organizations and developers can leverage this technology to solve real-world problems and create innovative solutions.
By examining specific use cases and implementation examples, we'll see how GPT-4o's visual understanding capabilities can be applied to tasks ranging from simple image description to complex technical analysis. These applications showcase the versatility of the model and its potential to revolutionize workflows in fields such as healthcare, education, design, and technical documentation.
Detailed Image Analysis
Converting visual content into natural language descriptions is one of GPT-4o's most powerful and sophisticated capabilities. The model demonstrates remarkable ability in comprehensive scene analysis, methodically deconstructing images into their fundamental components with exceptional accuracy and detail. Through advanced neural processing, it can perform multiple levels of analysis simultaneously:
- Identify individual objects and their characteristics - from simple elements like shape and size to complex features like brand names, conditions, and specific variations of objects
- Describe spatial relationships between elements - precisely analyzing how objects are positioned relative to each other, including depth perception, overlapping, and hierarchical arrangements in three-dimensional space
- Recognize colors, textures, and patterns with high accuracy - distinguishing between subtle shade variations, complex material properties, and intricate pattern repetitions or irregularities
- Detect subtle visual details that might be missed by conventional computer vision systems - including shadows, reflections, partial occlusions, and environmental effects that affect the appearance of objects
- Understand contextual relationships between objects in a scene - interpreting how different elements interact with each other, their likely purpose or function, and the overall context of the environment
These sophisticated capabilities enable a wide range of practical applications. In automated image cataloging, the system can create detailed, searchable descriptions of large image databases. For visually impaired users, it provides rich, contextual descriptions that paint a complete picture of the visual scene. The model's versatility extends to processing various types of visual content:
- Product photos - detailed descriptions of features, materials, and design elements
- Architectural drawings - interpretation of technical details, measurements, and spatial relationships
- Natural scenes - comprehensive analysis of landscapes, weather conditions, and environmental features
- Social situations - understanding of human interactions, expressions, and body language
This capability enables applications ranging from automated image cataloging to detailed scene description for visually impaired users. The model can process everything from simple product photos to complex architectural drawings, providing rich, contextual descriptions that capture both obvious and nuanced visual elements.
Example: Interactive Visual Q&A systems
This code will send an image (from a local file) and a multi-part prompt to the GPT-4o model to showcase these different analysis types in a single response.
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d")
print(f"Running GPT-4o vision example on: {current_date_str}")
# Initialize the OpenAI client
try:
# Check if API key is loaded correctly
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local image file
# IMPORTANT: Replace 'sample_scene.jpg' with the actual filename of your image.
image_path = "sample_scene.jpg"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Determine the media type based on file extension
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the multi-part prompt targeting different analysis types
prompt_text = """
Analyze the provided image and respond to the following points clearly:
1. **Accessibility Description:** Describe this image in detail as if for someone who cannot see it. Include the overall scene, main objects, colors, and spatial relationships.
2. **Object Recognition:** List all the distinct objects you can clearly identify in the image.
3. **Interactive Q&A / Inference:** Based on the objects and their arrangement, what is the likely setting or context of this image (e.g., office, kitchen, park)? What activity might be happening or about to happen?
"""
print(f"Sending image '{image_path}' and prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Specify the GPT-4o model
messages=[
{
"role": "user",
"content": [ # Content is a list containing text and image(s)
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
# Pass the base64-encoded image data URI
"url": base64_image,
# Optional: Detail level ('low', 'high', 'auto')
# 'high' uses more tokens for more detail analysis
"detail": "auto"
}
}
]
}
],
max_tokens=500 # Adjust max_tokens as needed for expected response length
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Image Analysis Result ---")
print(analysis_result)
print("------------------------------------\n")
# You can also print usage information
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
# You might want to check e.code or e.status_code for specifics
if "content_policy_violation" in str(e):
print("Hint: The request might have been blocked by the content safety policy.")
elif "invalid_image" in str(e):
print("Hint: Check if the image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's ability to perform detailed image analysis, combining several use cases discussed: generating accessibility descriptions, recognizing objects, and answering contextual questions about the visual content.
- Prerequisites: Lists the necessary library (
openai,python-dotenv), how to handle the API key securely (using a.envfile), and the need for a sample image file. - Image Encoding: Includes a helper function
encode_image_to_base64to convert a local image file into the base64 data URI format required by the API when not using a direct public URL. It also performs basic file type checking. - API Client: Initializes the standard OpenAI client, loading the API key from environment variables. Includes error handling for missing keys or initialization issues.
- Multi-Modal Prompt: The core of the request is the
messagesstructure.- It contains a single user message.
- The
contentof this message is a list containing multiple parts:- A
textpart holding the instructions (the prompt asking for description, object list, and context). - An
image_urlpart. Crucially, theurlfield withinimage_urlis set to thedata:[media_type];base64,[encoded_string]URI generated by the helper function. Thedetailparameter can be adjusted (low,high,auto) to influence the analysis depth and token cost.
- A
- API Call (
client.chat.completions.create):- Specifies
model="gpt-4o". - Passes the structured
messageslist. - Sets
max_tokensto control the response length.
- Specifies
- Response Handling: Extracts the text content from the
choices[0].message.contentfield of the API response and prints it. It also shows how to access token usage information. - Error Handling: Includes
try...exceptblocks for API errors (OpenAIError) and general exceptions, providing hints for common issues like content policy flags or invalid images. - Demonstrated Capabilities: This single API call effectively showcases:
- Accessibility: The model generates a textual description suitable for screen readers.
- Object Recognition: It identifies and lists objects present in the image.
- Visual Q&A/Inference: It answers questions about the context and potential activities based on visual evidence.
This example provides a practical and comprehensive demonstration of GPT-4o's vision capabilities for detailed image understanding within the context of your book chapter. Remember to replace "sample_scene.jpg" with an actual image file for testing.
Technical Interpretation and Data Analysis
Processing complex visualizations like charts, graphs, and diagrams requires sophisticated understanding to extract meaningful insights and trends. The system demonstrates remarkable capabilities in translating visual data into actionable information.
This includes the ability to:
- Analyze quantitative data presented in various chart formats (bar charts, line graphs, scatter plots) and identify key patterns, outliers, and correlations. For example, it can detect seasonal trends in line graphs, spot unusual data points in scatter plots, and compare proportions in bar charts.
- Interpret complex technical diagrams such as architectural blueprints, engineering schematics, and scientific illustrations with precise detail. This includes understanding scale drawings, electrical circuit diagrams, molecular structures, and mechanical assembly instructions.
- Extract numerical values, labels, and legends from visualizations while maintaining contextual accuracy. The system can read and interpret axes labels, data point values, legend entries, and footnotes, ensuring all quantitative information is accurately captured.
- Compare multiple data points or trends across different time periods or categories to provide comprehensive analytical insights. This includes year-over-year comparisons, cross-category analysis, and multi-variable trend identification.
- Translate visual statistical information into clear, written explanations that non-technical users can understand, breaking down complex data relationships into accessible language while preserving the accuracy of the underlying information.
Example:
This code will send an image file (e.g., a bar chart) and specific prompts to GPT-4o, asking it to identify the chart type, understand the data presented, and extract key insights or trends.
Download a sample of the file “sales_chart.png” https://files.cuantum.tech/images/sales-chart.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context provided
current_date_str = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Houston, Texas, United States"
print(f"Running GPT-4o technical interpretation example on: {current_date_str}")
print(f"Current Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local chart/graph image file
# IMPORTANT: Replace 'sales_chart.png' with the actual filename of your image.
image_path = "sales_chart.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for technical interpretation
prompt_text = f"""
Analyze the provided chart image ({os.path.basename(image_path)}) in detail. Focus on interpreting the data presented visually. Please provide the following:
1. **Chart Type:** Identify the specific type of chart (e.g., bar chart, line graph, pie chart, scatter plot).
2. **Data Representation:** Describe what data is being visualized. What do the axes represent (if applicable)? What are the units or categories?
3. **Key Insights & Trends:** Summarize the main findings or trends shown in the chart. What are the highest and lowest points? Is there a general increase, decrease, or pattern?
4. **Specific Data Points (Example):** If possible, estimate the value for a specific point (e.g., 'What was the approximate value for July?' - adapt the question based on the likely chart content).
5. **Overall Summary:** Provide a brief overall summary of what the chart communicates.
Current Date for Context: {current_date_str}
"""
print(f"Sending chart image '{image_path}' and analysis prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Use 'high' detail for potentially better analysis of charts
"detail": "high"
}
}
]
}
],
# Increase max_tokens if detailed analysis is expected
max_tokens=700
)
# --- Process and Display the Response ---
if response.choices:
analysis_result = response.choices[0].message.content
print("\n--- GPT-4o Technical Interpretation Result ---")
print(analysis_result)
print("---------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e):
print("Hint: Check if the chart image file is corrupted or in an unsupported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability for technical interpretation, specifically analyzing visual data representations like charts and graphs. Instead of just describing the image, the goal is to extract meaningful insights and understand the data presented.
- Prerequisites: Similar setup requirements:
openai,python-dotenvlibraries, API key in.env, and importantly, an image file containing a chart or graph (sales_chart.pngused as placeholder). - Image Encoding: Uses the same
encode_image_to_base64function to prepare the local image file for the API. - Prompt Design for Interpretation: The prompt is carefully crafted to guide GPT-4o towards analysis rather than simple description. It asks specific questions about:
- Chart Type: Basic identification.
- Data Representation: Understanding axes, units, and categories.
- Key Insights & Trends: The core analytical task – summarizing patterns, highs/lows.
- Specific Data Points: Testing the ability to read approximate values from the chart.
- Overall Summary: A concise takeaway message.
- Contextual Information: Includes the current date and filename for reference within the prompt.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the analytical text prompt and the base64 encoded chart image.
- Sets
detailto"high"in theimage_urlpart, suggesting to the model to use more resources for a potentially more accurate analysis of the visual details in the chart (this may increase token cost). - Allocates potentially more
max_tokens(e.g., 700) anticipating a more detailed analytical response compared to a simple description.
- Targets the
- Response Handling: Extracts and prints the textual analysis provided by GPT-4o. Includes token usage details.
- Error Handling: Standard checks for API errors and file issues.
- Use Case Relevance: This directly addresses the "Technical Interpretation" use case by showing how GPT-4o can process complex visualizations, extract data points, identify trends, and provide summaries, turning visual data into actionable insights. This is valuable for data analysis workflows, report generation, and understanding technical documents.
Remember to use a clear, high-resolution image of a chart or graph for best results when testing this code. Replace "sales_chart.png" with the correct path to your image file.
Document Processing
GPT-4o demonstrates exceptional capabilities in processing and analyzing diverse document formats, serving as a comprehensive solution for document analysis and information extraction. This advanced system leverages sophisticated computer vision and natural language processing to handle an extensive range of document types with remarkable accuracy. Here's a detailed breakdown of its document processing capabilities:
- Handwritten Documents: The system excels at interpreting handwritten content across multiple styles and formats. It can:
- Accurately recognize different handwriting styles, from neat cursive to rushed scribbles
- Process both formal documents and informal notes with high accuracy
- Handle multiple languages and special characters in handwritten form
- Structured Forms: Demonstrates superior ability in processing standardized documentation with:
- Precise extraction of key data fields from complex forms
- Automatic organization of extracted information into structured formats
- Validation of data consistency across multiple form fields
- Technical Documentation: Shows advanced comprehension of specialized technical materials through:
- Detailed interpretation of complex technical notations and symbols
- Understanding of scale and dimensional information in drawings
- Recognition of industry-standard technical specifications and terminology
- Mixed-Format Documents: Demonstrates versatile processing capabilities by:
- Seamlessly integrating information from text, images, and graphical elements
- Maintaining context across different content types within the same document
- Processing complex layouts with multiple information hierarchies
- Legacy Documents: Offers sophisticated handling of historical materials by:
- Adapting to various levels of document degradation and aging
- Processing outdated formatting and typography styles
- Maintaining historical context while making content accessible in modern formats
Example:
This code will send an image of a document (like an invoice or receipt) to GPT-4o and prompt it to identify the document type and extract specific pieces of information, such as vendor name, date, total amount, and line items.
Download a sample of the file “sample_invoice.png” https://files.cuantum.tech/images/sample_invoice.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
current_location = "Little Elm, Texas, United States" # As per context provided
print(f"Running GPT-4o document processing example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local document image file
# IMPORTANT: Replace 'sample_invoice.png' with the actual filename of your document image.
image_path = "sample_invoice.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for document processing and data extraction
prompt_text = f"""
Please analyze the provided document image ({os.path.basename(image_path)}) and perform the following tasks:
1. **Document Type:** Identify the type of document (e.g., Invoice, Receipt, Purchase Order, Letter, Handwritten Note).
2. **Information Extraction:** Extract the following specific pieces of information if they are present in the document. If a field is not found, please indicate "Not Found".
* Vendor/Company Name:
* Customer Name (if applicable):
* Document Date / Invoice Date:
* Due Date (if applicable):
* Invoice Number / Document ID:
* Total Amount / Grand Total:
* List of Line Items (include description, quantity, unit price, and total price per item if available):
* Shipping Address (if applicable):
* Billing Address (if applicable):
3. **Summary:** Briefly summarize the main purpose or content of this document.
Present the extracted information clearly.
Current Date/Time for Context: {current_timestamp}
"""
print(f"Sending document image '{image_path}' and extraction prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# Detail level 'high' might be beneficial for reading text in documents
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on expected length of extracted info
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
extracted_data = response.choices[0].message.content
print("\n--- GPT-4o Document Processing Result ---")
print(extracted_data)
print("-----------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the document image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code demonstrates GPT-4o's capability in document processing, a key use case involving understanding and extracting information from images of documents like invoices, receipts, forms, or notes.
- Prerequisites: Requires the standard setup:
openai,python-dotenvlibraries, API key, and an image file of the document to be processed (sample_invoice.pngas the placeholder). - Image Encoding: The
encode_image_to_base64function converts the local document image into the required format for the API. - Prompt Design for Extraction: The prompt is crucial for document processing. It explicitly asks the model to:
- Identify the document type.
- Extract a predefined list of specific fields (Vendor, Date, Total, Line Items, etc.). Requesting "Not Found" for missing fields encourages structured output.
- Provide a summary.
- Including the filename and current timestamp provides context.
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel. - Sends the multi-part message with the text prompt and the base64 encoded document image.
- Uses
detail: "high"for the image, which can be beneficial for improving the accuracy of Optical Character Recognition (OCR) and understanding text within the document image, though it uses more tokens. - Sets
max_tokensto accommodate potentially lengthy extracted information, especially line items.
- Specifies the
- Response Handling: Prints the text response from GPT-4o, which should contain the identified document type and the extracted fields as requested by the prompt. Token usage is also displayed.
- Error Handling: Includes checks for API errors and file system issues, with specific hints for potential image processing problems.
- Use Case Relevance: This directly addresses the "Document Processing" use case. It showcases how GPT-4o vision can automate tasks like data entry from invoices/receipts, summarizing correspondence, or even interpreting handwritten notes, significantly streamlining workflows that involve processing visual documents.
For testing, use a clear image of a document. The accuracy of the extraction will depend on the image quality, the clarity of the document layout, and the text's legibility. Remember to replace "sample_invoice.png" with the path to your actual document image.
Visual Problem Detection
Visual Problem Detection is a sophisticated AI capability that revolutionizes how we identify and analyze visual issues across digital assets. This advanced technology leverages computer vision and machine learning algorithms to automatically scan and evaluate visual elements, detecting problems that might be missed by human reviewers. It systematically examines various aspects of visual content, finding inconsistencies, errors, and usability problems in:
- User interfaces: Detecting misaligned elements, broken layouts, inconsistent styling, and accessibility issues. This capability performs comprehensive analysis of UI elements, including:
- Button placement and interaction zones to ensure optimal user experience
- Form field alignment and validation to maintain visual harmony
- Navigation menu consistency across different pages and states
- Color contrast ratios for WCAG compliance and accessibility standards
- Interactive element spacing and touchpoint sizing for mobile compatibility
- Design mockups: Identifying spacing problems, color contrast issues, and deviations from design guidelines. The system performs detailed analysis including:
- Padding and margin measurements against established specifications
- Color scheme consistency checking across all design elements
- Typography hierarchy verification for readability and brand consistency
- Component library compliance and design system adherence
- Visual rhythm and balance assessment in layouts
- Visual layouts: Spotting typography errors, grid alignment problems, and responsive design breakdowns. This involves sophisticated analysis of:
- Font usage patterns across different content types and sections
- Text spacing and line height optimization for readability
- Grid system compliance across various viewport sizes
- Responsive behavior testing at standard breakpoints
- Layout consistency across different devices and orientations
This capability has become indispensable for quality assurance teams and designers in maintaining high standards across digital products. By implementing Visual Problem Detection:
- Teams can automate up to 80% of visual QA processes
- Detection accuracy reaches 95% for common visual issues
- Review cycles are reduced by an average of 60%
The technology significantly accelerates the review process by automatically flagging potential issues before they reach production. This proactive approach not only reduces the need for time-consuming manual inspection but also improves overall product quality by ensuring consistent visual standards across all digital assets. The result is faster development cycles, reduced costs, and higher-quality deliverables that meet both technical and aesthetic standards.
Example:
This code sends an image of a user interface (UI) mockup or a design screenshot to GPT-4o and prompts it to identify potential design flaws, usability issues, inconsistencies, and other visual problems.
Download a sample of the file “ui_mockup.png” https://files.cuantum.tech/images/ui_mockup.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o visual problem detection example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the path to your local UI/design image file
# IMPORTANT: Replace 'ui_mockup.png' with the actual filename of your image.
image_path = "ui_mockup.png"
# --- Function to encode the image to base64 ---
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError:
print(f"Error: Image file not found at '{filepath}'")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding: {e}")
return None
# --- Prepare the API Request ---
# Encode the image
base64_image = encode_image_to_base64(image_path)
if base64_image:
# Define the prompt specifically for visual problem detection in UI/UX
prompt_text = f"""
Act as a UI/UX design reviewer. Analyze the provided interface mockup image ({os.path.basename(image_path)}) for potential design flaws, inconsistencies, and usability issues.
Please identify and list problems related to the following categories, explaining *why* each identified item is a potential issue:
1. **Layout & Alignment:** Check for misaligned elements, inconsistent spacing or margins, elements overlapping unintentionally, or poor use of whitespace.
2. **Typography:** Look for inconsistent font usage (styles, sizes, weights), poor readability (font choice, line spacing, text justification), or text truncation issues.
3. **Color & Contrast:** Evaluate color choices for accessibility (sufficient contrast between text and background, especially for interactive elements), brand consistency, and potential overuse or clashing of colors. Check WCAG contrast ratios if possible.
4. **Consistency:** Identify inconsistencies in button styles, icon design, terminology, interaction patterns, or visual language across the interface shown.
5. **Usability & Clarity:** Point out potentially confusing navigation, ambiguous icons or labels, small touch targets (for mobile), unclear calls to action, or information hierarchy issues.
6. **General Design Principles:** Comment on adherence to basic design principles like visual hierarchy, balance, proximity, and repetition.
List the detected issues clearly. If no issues are found in a category, state that.
Analysis Context Date/Time: {current_timestamp}
"""
print(f"Sending UI image '{image_path}' and review prompt to GPT-4o...")
try:
# Make the API call to GPT-4o
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt_text
},
{
"type": "image_url",
"image_url": {
"url": base64_image,
# High detail might help catch subtle alignment/text issues
"detail": "high"
}
}
]
}
],
# Adjust max_tokens based on the expected number of issues
max_tokens=1000
)
# --- Process and Display the Response ---
if response.choices:
review_result = response.choices[0].message.content
print("\n--- GPT-4o Visual Problem Detection Result ---")
print(review_result)
print("----------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if the UI mockup image file is clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed without a valid base64 encoded image.")Code breakdown:
- Context: This code example showcases GPT-4o's capability for visual problem detection, particularly useful in UI/UX design reviews, quality assurance (QA), and identifying potential issues in visual layouts or mockups.
- Prerequisites: Standard setup involving
openai,python-dotenv, API key configuration, and an input image file representing a UI design or mockup (ui_mockup.pngas placeholder). - Image Encoding: The
encode_image_to_base64function is used to prepare the local image file for the API request. - Prompt Design for Review: The prompt is specifically structured to guide GPT-4o to act as a UI/UX reviewer. It asks the model to look for problems within defined categories common in design critiques:
- Layout & Alignment
- Typography
- Color & Contrast (mentioning accessibility/WCAG is key)
- Consistency
- Usability & Clarity
- General Design Principles
Crucially, it asks why something is an issue, prompting for justification beyond simple identification.
- API Call (
client.chat.completions.create):- Targets the
gpt-4omodel. - Sends the multi-part message containing the detailed review prompt and the base64 encoded UI image.
- Uses
detail: "high"for the image, potentially improving the model's ability to perceive subtle visual details like slight misalignments or text rendering issues. - Sets
max_tokensto allow for a comprehensive list of potential issues and explanations.
- Targets the
- Response Handling: Prints the textual response from GPT-4o, which should contain a structured list of identified visual problems based on the prompt categories. Token usage is also provided.
- Error Handling: Includes standard checks for API errors and file system issues.
- Use Case Relevance: This directly addresses the "Visual Problem Detection" use case. It demonstrates how AI can assist designers and developers by automatically scanning interfaces for common flaws, potentially speeding up the review process, catching issues early, and improving the overall quality and usability of digital products.
For effective testing, use an image of a UI that intentionally or unintentionally includes some design flaws. Remember to replace "ui_mockup.png" with the path to your actual image file.
1.3.3 Supported Use Cases for Vision in GPT-4o
GPT-4o's vision capabilities extend far beyond simple image recognition, offering a diverse range of applications that can transform how we interact with visual content. This section explores the various use cases where GPT-4o's visual understanding can be leveraged to create more intelligent and responsive applications.
From analyzing complex diagrams to providing detailed descriptions of images, GPT-4o's vision features enable developers to build solutions that bridge the gap between visual and textual understanding. These capabilities can be particularly valuable in fields such as education, accessibility, content moderation, and automated analysis.
Let's explore the key use cases where GPT-4o's vision capabilities shine, along with practical examples and implementation strategies that demonstrate its versatility in real-world applications.
| Use Case | Example | Explanation |
| Image captioning | "Describe this image in detail." | Converts visual content into detailed textual descriptions, useful for content cataloging, accessibility, and automated image indexing. |
| UI analysis | "Are there any visual bugs in this webpage screenshot?" | Examines user interfaces for design inconsistencies, alignment issues, and usability problems, helping streamline QA processes. |
| Document reading | "Extract the invoice number and date from this scan." | Processes scanned documents to extract specific information, automating data entry and document processing workflows. |
| Data visualization interpretation | "Summarize this pie chart in plain English." | Translates complex visual data representations into clear, narrative descriptions, making data more accessible to all users. |
| Educational Q&A | "What is this geometric figure? What are its properties?" | Provides interactive learning support by analyzing and explaining visual educational content, helping students understand complex concepts. |
| Accessibility support | "Read aloud the contents of this image." | Enhances digital accessibility by providing detailed descriptions of visual content for users with visual impairments. |
1.3.4 Best Practices for Vision Prompts
Crafting effective prompts for vision-enabled AI models requires a different approach compared to text-only interactions. While the fundamental principles of clear communication remain important, visual prompts need to account for the spatial, contextual, and multi-modal nature of image analysis. This section explores key strategies and best practices to help you create more effective vision-based prompts that maximize GPT-4o's visual understanding capabilities.
Whether you're building applications for image analysis, document processing, or visual QA, understanding these best practices will help you:
- Get more accurate and relevant responses from the model
- Reduce ambiguity in your requests
- Structure your prompts for complex visual analysis tasks
- Optimize the interaction between textual and visual elements
Let's explore the core principles that will help you craft more effective vision-based prompts:
Be direct with your request:
Example 1 (Ineffective Prompt):
"What are the main features in this room?"
This prompt has several issues:
- It's overly broad and unfocused
- Lacks specific criteria for what constitutes a "main feature"
- May result in inconsistent or superficial responses
- Doesn't guide the AI toward any particular aspect of analysis
Example 2 (Effective Prompt):
"Identify all electronic devices in this living room and describe their position."
This prompt is superior because:
- Clearly defines what to look for (electronic devices)
- Specifies the scope (living room)
- Requests specific information (position/location)
- Will generate structured, actionable information
- Makes it easier to verify if the AI missed anything
The key difference is that the second prompt provides clear parameters for analysis and a specific type of output, making it much more likely to receive useful, relevant information that serves your intended purpose.
Combine with text when needed
A standalone image may be enough for basic captioning, but combining it with a well-crafted prompt significantly enhances the model's analytical capabilities and output precision. The key is to provide clear, specific context that guides the model's attention to the aspects most relevant to your needs.
For example, instead of just uploading an image, add detailed contextual prompts like:
- "Analyze this architectural drawing focusing on potential safety hazards, particularly in stairwell and exit areas"
- "Review this graph and explain the trend between 2020-2023, highlighting any seasonal patterns and anomalies"
- "Examine this UI mockup and identify accessibility issues for users with visual impairments"
This approach offers several advantages:
- Focuses the model's analysis on specific features or concerns
- Reduces irrelevant or superficial observations
- Ensures more consistent and structured responses
- Allows for deeper, more nuanced analysis of complex visual elements
- Helps generate more actionable insights and recommendations
The combination of visual input with precise textual guidance helps the model understand exactly what aspects of the image are most important for your use case, resulting in more valuable and targeted responses.
Use structured follow-ups
After completing an initial visual analysis, you can leverage the conversation thread to conduct a more thorough investigation through structured follow-up questions. This approach allows you to build upon the model's initial observations and extract more detailed, specific information. Follow-up questions help create a more interactive and comprehensive analysis process.
Here's how to effectively use structured follow-ups:
- Drill down into specific details
- Example: "Can you describe the lighting fixtures in more detail?"
- This helps focus the model's attention on particular elements that need closer examination
- Useful for technical analysis or detailed documentation
- Compare elements
- Example: "How does the layout of room A compare to room B?"
- Enables systematic comparison of different components or areas
- Helps identify patterns, inconsistencies, or relationships
- Get recommendations
- Example: "Based on this floor plan, what improvements would you suggest?"
- Leverages the model's understanding to generate practical insights
- Can lead to actionable feedback for improvement
By using structured follow-ups, you create a more dynamic interaction that can uncover deeper insights and more nuanced understanding of the visual content you're analyzing.
1.3.5 Multi-Image Input
You can pass multiple images in a single message if your use case requires cross-image comparison. This powerful feature allows you to analyze relationships between images, compare different versions of designs, or evaluate changes over time. The model processes all images simultaneously, enabling sophisticated multi-image analysis that would typically require multiple separate requests.
Here's what you can do with multi-image input:
- Compare Design Iterations
- Analyze UI/UX changes across versions
- Track progression of design implementations
- Identify consistency across different screens
- Document Analysis
- Compare multiple versions of documents
- Cross-reference related paperwork
- Verify document authenticity
- Time-Based Analysis
- Review before-and-after scenarios
- Track changes in visual data over time
- Monitor progress in visual projects
The model processes these images contextually, understanding their relationships and providing comprehensive analysis. It can identify patterns, inconsistencies, improvements, and relationships across all provided images, offering detailed insights that would be difficult to obtain through single-image analysis.
Example:
This code sends two images (e.g., two versions of a UI mockup) along with a text prompt in a single API call, asking the model to compare them and identify differences.
Download a sample of the file “image_path_1.png” https://files.cuantum.tech/images/image_path_1.png
Download a sample of the file “image_path_2.png” https://files.cuantum.tech/images/image_path_2.png
import os
import base64
from openai import OpenAI, OpenAIError
from dotenv import load_dotenv
import datetime
# --- Configuration ---
# Load environment variables (especially OPENAI_API_KEY)
load_dotenv()
# Get the current date and location context
current_timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S %Z")
# Location context from user prompt
current_location = "Little Elm, Texas, United States"
print(f"Running GPT-4o multi-image input example at: {current_timestamp}")
print(f"Location Context: {current_location}")
# Initialize the OpenAI client
try:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY not found in environment variables. Please set it in your .env file or environment.")
client = OpenAI(api_key=api_key)
except OpenAIError as e:
print(f"Error initializing OpenAI client: {e}")
exit()
except ValueError as e:
print(e)
exit()
# Define the paths to your TWO local image files
# IMPORTANT: Replace these with the actual filenames of your images.
image_path_1 = "ui_mockup_v1.png"
image_path_2 = "ui_mockup_v2.png"
# --- Function to encode the image to base64 ---
# (Same function as used in previous examples)
def encode_image_to_base64(filepath):
"""Encodes a local image file into base64 data URI format."""
try:
# Basic check if file exists
if not os.path.exists(filepath):
raise FileNotFoundError(f"Image file not found at '{filepath}'")
_, ext = os.path.splitext(filepath)
ext = ext.lower()
if ext == ".png":
media_type = "image/png"
elif ext in [".jpg", ".jpeg"]:
media_type = "image/jpeg"
elif ext == ".gif":
media_type = "image/gif"
elif ext == ".webp":
media_type = "image/webp"
else:
raise ValueError(f"Unsupported image format: {ext}. Use PNG, JPEG, GIF, or WEBP.")
with open(filepath, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
return f"data:{media_type};base64,{encoded_string}"
except FileNotFoundError as e:
print(f"Error: {e}")
return None
except ValueError as e:
print(f"Error: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred during image encoding for {filepath}: {e}")
return None
# --- Prepare the API Request ---
# Encode both images
base64_image_1 = encode_image_to_base64(image_path_1)
base64_image_2 = encode_image_to_base64(image_path_2)
# Proceed only if both images were encoded successfully
if base64_image_1 and base64_image_2:
# Define the prompt specifically for comparing the two images
prompt_text = f"""
Please analyze the two UI mockup images provided. The first image represents Version 1 ({os.path.basename(image_path_1)}) and the second image represents Version 2 ({os.path.basename(image_path_2)}).
Compare Version 1 and Version 2, and provide a detailed list of the differences you observe. Focus on changes in:
- Layout and element positioning
- Text content or wording
- Colors, fonts, or general styling
- Added or removed elements (buttons, icons, text fields, etc.)
- Any other significant visual changes.
List the differences clearly.
"""
print(f"Sending images '{image_path_1}' and '{image_path_2}' with comparison prompt to GPT-4o...")
try:
# Make the API call to GPT-4o with multiple images
response = client.chat.completions.create(
model="gpt-4o", # Use the GPT-4o model
messages=[
{
"role": "user",
# The 'content' field is a list containing text and MULTIPLE image parts
"content": [
# Part 1: The Text Prompt
{
"type": "text",
"text": prompt_text
},
# Part 2: The First Image
{
"type": "image_url",
"image_url": {
"url": base64_image_1,
"detail": "auto" # Or 'high' for more detail
}
},
# Part 3: The Second Image
{
"type": "image_url",
"image_url": {
"url": base64_image_2,
"detail": "auto" # Or 'high' for more detail
}
}
# Add more image_url blocks here if needed
]
}
],
# Adjust max_tokens based on the expected detail of the comparison
max_tokens=800
)
# --- Process and Display the Response ---
if response.choices:
comparison_result = response.choices[0].message.content
print("\n--- GPT-4o Multi-Image Comparison Result ---")
print(comparison_result)
print("--------------------------------------------\n")
print(f"API Usage: Prompt Tokens={response.usage.prompt_tokens}, Completion Tokens={response.usage.completion_tokens}, Total Tokens={response.usage.total_tokens}")
else:
print("Error: No response received from the API.")
except OpenAIError as e:
print(f"An API error occurred: {e}")
if "invalid_image" in str(e) or "could not process image" in str(e).lower():
print("Hint: Check if both image files are clear, not corrupted, and in a supported format/encoding.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
else:
print("Could not proceed. Ensure both images were encoded successfully.")
if not base64_image_1: print(f"Failed to encode: {image_path_1}")
if not base64_image_2: print(f"Failed to encode: {image_path_2}")
Code breakdown:
- Context: This code demonstrates GPT-4o's multi-image input capability, allowing users to send multiple images within a single API request for tasks like comparison, relationship analysis, or synthesis of information across visuals. The example focuses on comparing two UI mockups to identify differences.
- Prerequisites: Requires the standard setup (
openai,python-dotenv, API key) but specifically needs two input image files for the comparison task (ui_mockup_v1.pngandui_mockup_v2.pngused as placeholders). - Image Encoding: The
encode_image_to_base64function is used twice, once for each input image. Error handling ensures both images are processed correctly before proceeding. - API Request Structure: The key difference lies in the
messages[0]["content"]list. It now contains:- One dictionary of
type: "text"for the prompt. - Multiple dictionaries of
type: "image_url", one for each image being sent. The images are included sequentially after the text prompt.
- One dictionary of
- Prompt Design for Multi-Image Tasks: The prompt explicitly refers to the two images (e.g., "the first image," "the second image," or by filename as done here) and clearly states the task involving both images (e.g., "Compare Version 1 and Version 2," "list the differences").
- API Call (
client.chat.completions.create):- Specifies the
gpt-4omodel, which supports multi-image inputs. - Sends the structured
messageslist containing the text prompt and multiple base64 encoded images. - Sets
max_tokensappropriate for the expected output (a list of differences).
- Specifies the
- Response Handling: Prints the textual response from GPT-4o, which should contain the comparison results based on the prompt and the two images provided. Token usage reflects the processing of the text and all images.
- Error Handling: Includes standard checks, emphasizing potential issues with either of the image files.
- Use Case Relevance: This directly addresses the "Multi-Image Input" capability. It's useful for version comparison (designs, documents), analyzing sequences (before/after shots), combining information from different visual sources (e.g., product shots + size chart), or any task where understanding the relationship or differences between multiple images is required.
Remember to provide two distinct image files (e.g., two different versions of a UI mockup) when testing this code, and update the image_path_1 and image_path_2 variables accordingly.
1.3.6 Privacy & Security
As AI systems increasingly process and analyze visual data, understanding the privacy and security implications becomes paramount. This section explores the critical aspects of protecting image data when working with vision-enabled AI models, covering everything from basic security protocols to best practices for responsible data handling.
We'll examine the technical security measures in place, data management strategies, and essential privacy considerations that developers must address when building applications that process user-submitted images. Understanding these principles is crucial for maintaining user trust and ensuring compliance with data protection regulations.
Key areas we'll cover include:
- Security protocols for image data transmission and storage
- Best practices for managing user-submitted visual content
- Privacy considerations and compliance requirements
- Implementation strategies for secure image processing
Let's explore in detail the comprehensive security measures and privacy considerations that are essential for protecting visual data:
- Secure Image Upload and API Authentication:
- Image data is protected through advanced encryption during transit using industry-standard TLS protocols, ensuring end-to-end security
- A robust authentication system ensures that access is strictly limited to requests verified with your specific API credentials, preventing unauthorized access
- The system implements strict isolation - images associated with your API key remain completely separate and inaccessible to other users or API keys, maintaining data sovereignty
- Effective Image Data Management Strategies:
- The platform provides a straightforward method to remove unnecessary files using
openai.files.delete(file_id), giving you complete control over data retention - Best practices include implementing automated cleanup systems that regularly remove temporary image uploads, reducing security risks and storage overhead
- Regular systematic audits of stored files are crucial for maintaining optimal data organization and security compliance
- The platform provides a straightforward method to remove unnecessary files using
- Comprehensive User Privacy Protection:
- Implement explicit user consent mechanisms before any image analysis begins, ensuring transparency and trust
- Develop and integrate clear consent workflows within your application that inform users about how their images will be processed
- Create detailed privacy policies that explicitly outline image processing procedures, usage limitations, and data protection measures
- Establish and clearly communicate specific data retention policies, including how long images are stored and when they are automatically deleted
Summary
In this section, you've gained comprehensive insights into GPT-4o's groundbreaking vision capabilities, which fundamentally transform how AI systems process and understand visual content. This revolutionary feature goes well beyond traditional text processing, enabling AI to perform detailed image analysis with human-like understanding. Through advanced neural networks and sophisticated computer vision algorithms, the system can identify objects, interpret scenes, understand context, and even recognize subtle details within images. With remarkable efficiency and ease of implementation, you can leverage these powerful capabilities through a streamlined API that processes both images and natural language commands simultaneously.
This breakthrough technology represents a paradigm shift in AI applications, opening up an extensive range of practical implementations across numerous domains:
- Education: Create dynamic, interactive learning experiences with visual explanations and automated image-based tutoring
- Generate custom visual aids for complex concepts
- Provide real-time feedback on student drawings or diagrams
- Accessibility: Develop sophisticated tools that provide detailed image descriptions for visually impaired users
- Generate contextual descriptions of images with relevant details
- Create audio narratives from visual content
- Analysis: Perform sophisticated visual data analysis for business intelligence and research
- Extract insights from charts, graphs, and technical diagrams
- Analyze trends in visual data across large datasets
- Automation: Streamline workflows with automated image processing and categorization
- Automatically sort and tag visual content
- Process documents with mixed text and image content
Throughout this comprehensive exploration, you've mastered several essential capabilities that form the foundation of visual AI implementation:
- Upload and interpret images: Master the technical foundations of integrating the API into your applications, including proper image formatting, efficient upload procedures, and understanding the various parameters that affect interpretation accuracy. Learn to receive and parse detailed, context-aware interpretations that can drive downstream processing.
- Use multimodal prompts with text + image: Develop expertise in crafting effective prompts that seamlessly combine textual instructions with visual inputs. Understand how to structure queries that leverage both modalities for enhanced accuracy and more nuanced results. Learn advanced prompting techniques that can guide the AI's attention to specific aspects of images.
- Build assistants that see before they speak: Create sophisticated AI applications that process visual information as a fundamental part of their decision-making process. Learn to develop systems that can understand context from both visual and textual inputs, leading to more intelligent, natural, and context-aware interactions that truly bridge the gap between human and machine understanding.